Fast Sparse Matrix Permutation for Mesh-Based Direct Solvers
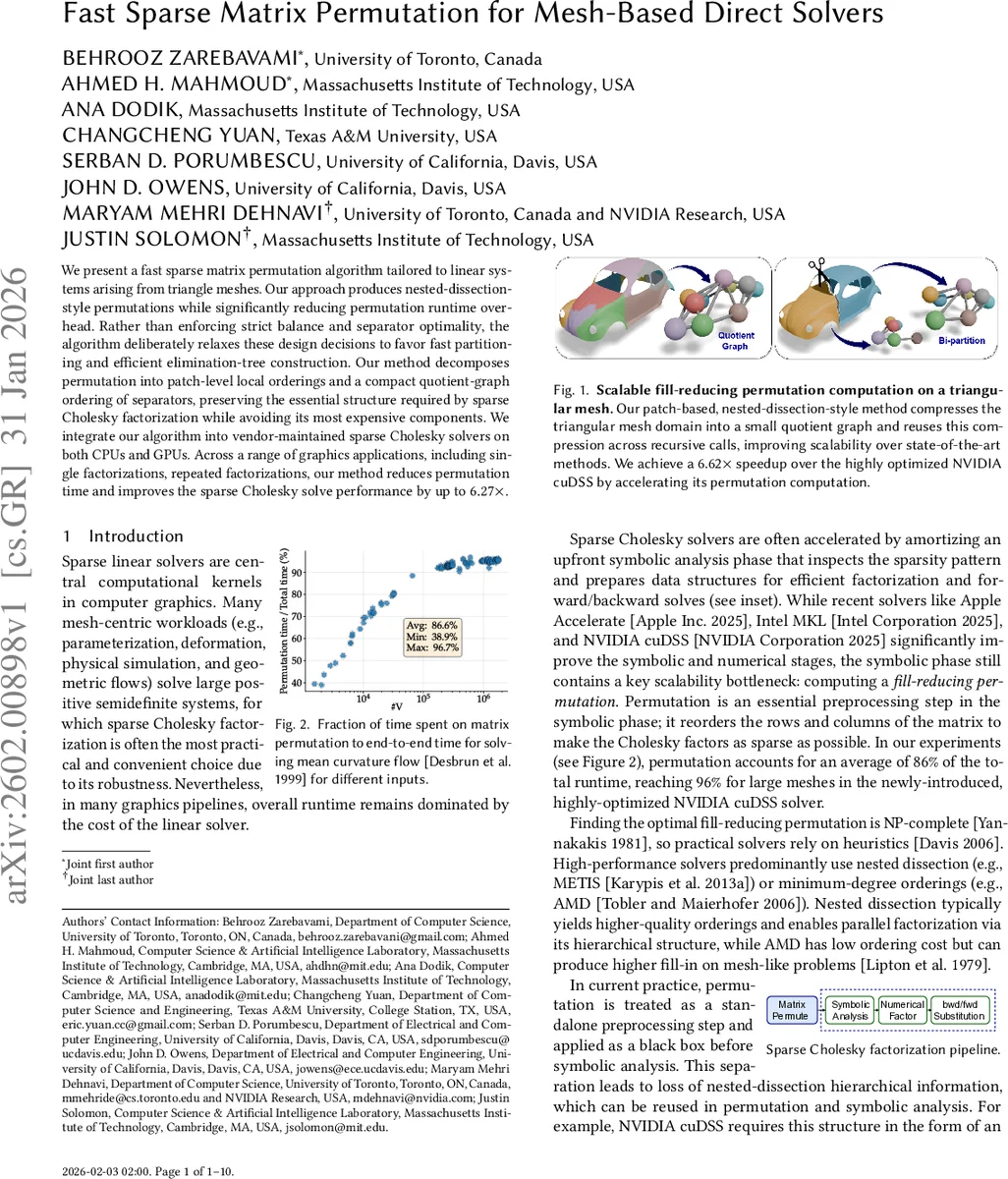
We present a fast sparse matrix permutation algorithm tailored to linear systems arising from triangle meshes. Our approach produces nested-dissection-style permutations while significantly reducing permutation runtime overhead. Rather than enforcing strict balance and separator optimality, the algorithm deliberately relaxes these design decisions to favor fast partitioning and efficient elimination-tree construction. Our method decomposes permutation into patch-level local orderings and a compact quotient-graph ordering of separators, preserving the essential structure required by sparse Cholesky factorization while avoiding its most expensive components. We integrate our algorithm into vendor-maintained sparse Cholesky solvers on both CPUs and GPUs. Across a range of graphics applications, including single factorizations, repeated factorizations, our method reduces permutation time and improves the sparse Cholesky solve performance by up to 6.27x.
💡 Research Summary
The paper addresses a critical bottleneck in modern sparse direct solvers for graphics and physical simulation: the matrix permutation (ordering) phase. For systems derived from triangle meshes—such as Laplacian or Hessian matrices—the permutation step can dominate total runtime, accounting for up to 96 % of the solve time in state‑of‑the‑art GPU solvers like NVIDIA cuDSS. Traditional ordering strategies fall into two categories. Minimum‑degree (AMD) is fast but often yields high fill‑in on mesh‑like graphs, while nested‑dissection (ND) produces high‑quality orderings and exposes parallelism but incurs substantial overhead due to repeated graph coarsening, balancing, and separator refinement (e.g., METIS, PT‑Scotch).
The authors propose a patch‑based nested‑dissection algorithm that dramatically reduces the search space for separators. The method proceeds in four steps:
- Patch Generation – Either reuse existing mesh patches (common in remeshing or domain decomposition) or compute them on‑the‑fly using a fast GPU k‑means routine (RXMesh). Each patch is a connected set of mesh vertices.
- Group Map Construction – The mesh‑to‑matrix correspondence (one vertex per row/column for scalar problems, or a small block for vector‑valued problems) is lifted to the sparse matrix graph. Every matrix vertex receives a group identifier indicating its patch.
- Patch‑Guided ND – The quotient graph, whose nodes are patches and edges reflect inter‑patch adjacency, is recursively partitioned. At each recursion level a separator set of patches is selected, the graph is split into left/right subgraphs, and the separator is recorded. Simultaneously, an elimination tree (etree) node is created for the separator, and recursion continues on the subgraphs until a user‑specified depth is reached. Because the quotient graph is orders of magnitude smaller than the original graph, separator computation is extremely fast.
- Permutation Assembly – A global permutation vector is obtained by traversing the completed etree in preorder (nested‑dissection order). The etree itself is output, allowing downstream symbolic analysis to reuse the hierarchy directly, eliminating a separate etree‑construction step.
Key design choices include relaxing strict balance and separator‑size constraints at the patch level. Instead of insisting on perfectly balanced partitions, the algorithm accepts “good enough” separators, trading a modest increase in fill‑in for a large reduction in preprocessing time. The authors also emphasize single‑time quotient‑graph construction: unlike METIS, which coarsens the graph anew at each recursion depth, the proposed method builds the quotient graph once and reuses it throughout the recursion, avoiding redundant work.
Performance evaluation spans several representative graphics workloads (mean‑curvature flow, mesh parameterization, deformation) and three major solver back‑ends: NVIDIA cuDSS (GPU), Intel MKL (CPU), and Apple Accelerate (CPU). Results show:
- Ordering time: up to 10.27× faster than METIS‑based orderings (geometric‑mean speed‑up 4.58×).
- End‑to‑end solve time: geometric‑mean speed‑up 3.51×, with a peak of 6.62× when the full pipeline (ordering + symbolic + numeric) is considered.
- Scalability: on meshes with several million vertices, permutation time drops from being the dominant cost (>90 % of total) to less than 15 % of total runtime.
- Fill‑in impact: despite slightly larger fill‑in compared to optimal ND, the overall runtime improves because the ordering overhead is reduced far more dramatically.
The authors acknowledge limitations. The quality of patches directly influences separator size; poorly chosen patches could lead to excessive fill‑in, which may be unacceptable for high‑precision scientific simulations. The current implementation focuses on scalar Laplacian‑type systems; extending to block‑structured Hessians requires careful handling of the group map and memory layout. Moreover, dynamic meshes (e.g., adaptive refinement) would need efficient patch‑update mechanisms to retain the speed advantage.
Future work suggested includes: (1) incremental patch updates for evolving meshes, (2) hybrid schemes that combine AMD on small subgraphs with patch‑ND on higher levels to balance quality and speed, and (3) distributed‑memory extensions where the quotient graph is partitioned across multiple GPUs or nodes for extreme‑scale problems.
In summary, the paper delivers a practical, high‑performance ordering technique tailored to mesh‑based SPD systems. By compressing the graph via patches, reusing the quotient graph across recursion, and simultaneously constructing the elimination tree, the method eliminates the dominant permutation bottleneck in modern direct solvers. The approach is validated on both CPU and GPU platforms, showing substantial speed‑ups without sacrificing the robustness of Cholesky factorization, and opens a clear path toward scalable, real‑time geometry processing pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment