Zero-Flow Encoders
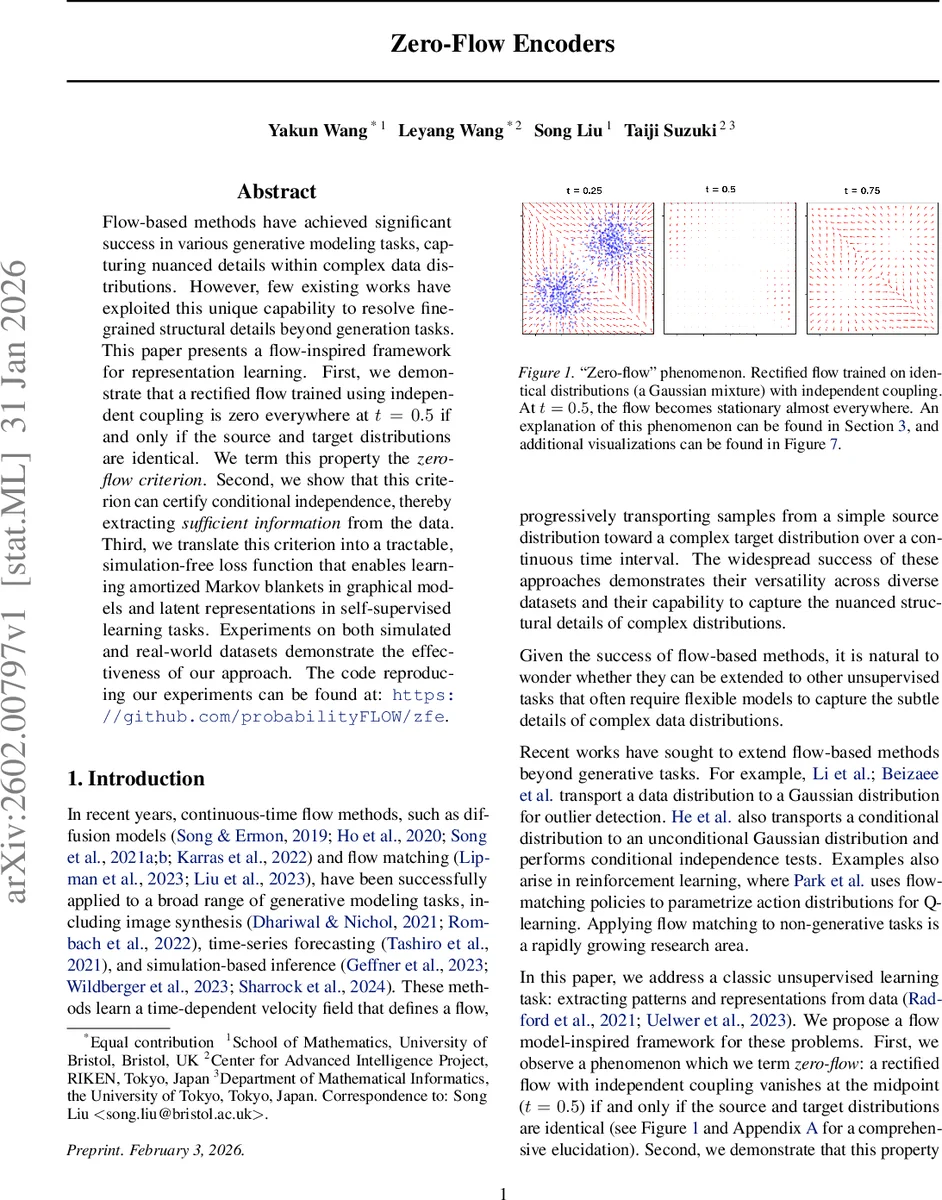
Flow-based methods have achieved significant success in various generative modeling tasks, capturing nuanced details within complex data distributions. However, few existing works have exploited this unique capability to resolve fine-grained structural details beyond generation tasks. This paper presents a flow-inspired framework for representation learning. First, we demonstrate that a rectified flow trained using independent coupling is zero everywhere at $t=0.5$ if and only if the source and target distributions are identical. We term this property the \emph{zero-flow criterion}. Second, we show that this criterion can certify conditional independence, thereby extracting \emph{sufficient information} from the data. Third, we translate this criterion into a tractable, simulation-free loss function that enables learning amortized Markov blankets in graphical models and latent representations in self-supervised learning tasks. Experiments on both simulated and real-world datasets demonstrate the effectiveness of our approach. The code reproducing our experiments can be found at: https://github.com/probabilityFLOW/zfe.
💡 Research Summary
The paper introduces a novel framework called “Zero‑Flow Encoders” that repurposes flow‑based models, specifically Rectified Flow, for representation learning and structural inference rather than pure generative modeling. The core observation is a “zero‑flow” phenomenon: when a Rectified Flow is trained with independent coupling between source and target samples, the velocity field at the midpoint (t = 0.5) becomes identically zero if and only if the two marginal distributions are identical. This is formalized as the Zero‑Flow Condition (Theorem 3.1).
The authors extend this property to conditional distributions. By defining a velocity field that depends on both the original features Y and a candidate summary statistic f(Y), they prove (Theorem 3.3) that the midpoint velocity vanishes exactly when the conditional distribution p(X|Y) equals p(X|f(Y)). Consequently, the zero‑flow condition is equivalent to the conditional independence statement X ⊥⊥ Y | f(Y), i.e., f(Y) is a sufficient statistic for predicting X.
To exploit this insight, the paper proposes a tractable, simulation‑free loss that combines the standard Rectified Flow objective with a “zero‑flow loss” penalizing the squared norm of the midpoint velocity. The overall objective (Equation 8) is a weighted integral over time, with a weighting function ω(t) that peaks at t = 0.5, encouraging the learned velocity field to be zero at the midpoint while still fitting the overall transport. The encoder f and the velocity network u_t are jointly optimized from data using only shuffled pairs (X, Y) and (X′, Y′).
Two concrete applications are demonstrated:
-
Amortized Markov Blanket Discovery – In an undirected graphical model, a Markov blanket of a target set of variables is the minimal subset of remaining variables that renders the target conditionally independent of the rest. Traditional methods rely on parametric assumptions (e.g., lasso) and are limited to a fixed set of targets. The zero‑flow encoder learns a non‑parametric mapping f(Y) that serves as a sufficient statistic for any chosen target, thereby implicitly identifying its Markov blanket. Because f is amortized, the same model can answer blanket queries for arbitrary targets at test time without retraining.
-
Self‑Supervised Representation Learning – Standard contrastive methods (InfoNCE, SimCLR) maximize mutual information between augmented views, which can lead to “shortcut” solutions that latch onto spurious patterns. By enforcing the zero‑flow condition between two views of the same sample, the encoder is forced to retain only information that makes the conditional distributions identical, i.e., the true semantic content. Experiments on CIFAR‑10/100 and ImageNet‑100 show that the learned representations achieve competitive linear probe accuracy and are robust to artificial watermarks that typically fool contrastive learners.
The experimental section includes synthetic 2‑D Gaussian mixture visualizations confirming the zero‑flow phenomenon, benchmark comparisons for Markov blanket recovery on synthetic graphs and real genomic data, and standard self‑supervised benchmarks. Across tasks, the zero‑flow encoder matches or exceeds baselines while requiring no explicit density estimation or adversarial training.
Strengths:
- Provides a rigorous theoretical link between flow dynamics and conditional independence.
- Introduces a practical, simulation‑free loss that can be optimized with standard stochastic gradient methods.
- Demonstrates versatility by applying the same principle to both graphical model inference and representation learning.
- Offers an amortized solution for Markov blanket queries, a capability lacking in prior work.
Weaknesses / Open Questions:
- The zero‑flow property relies on independent coupling; the sensitivity to sampling bias or dependence between paired samples is not explored.
- The choice of the time‑weighting function ω(t) and its impact on convergence are only heuristically justified.
- The velocity network architecture and its capacity may affect the ability to achieve exact zero‑flow; ablation studies are limited.
- Experiments focus on moderate‑dimensional data; scalability to very high‑dimensional or sequential domains (e.g., language, long time series) remains to be shown.
Conclusion:
Zero‑Flow Encoders turn a peculiar dynamical property of flow models into a powerful tool for unsupervised learning. By translating the requirement that the midpoint velocity vanish into a loss, the method enforces conditional independence without explicit density modeling. This yields a non‑parametric, amortized approach to Markov blanket discovery and a robust alternative to contrastive self‑supervision. With further investigation into hyper‑parameter robustness and broader domain applicability, zero‑flow encoders could become a foundational technique for extracting sufficient statistics and structural information from complex data.
Comments & Academic Discussion
Loading comments...
Leave a Comment