BLOCK-EM: Preventing Emergent Misalignment by Blocking Causal Features
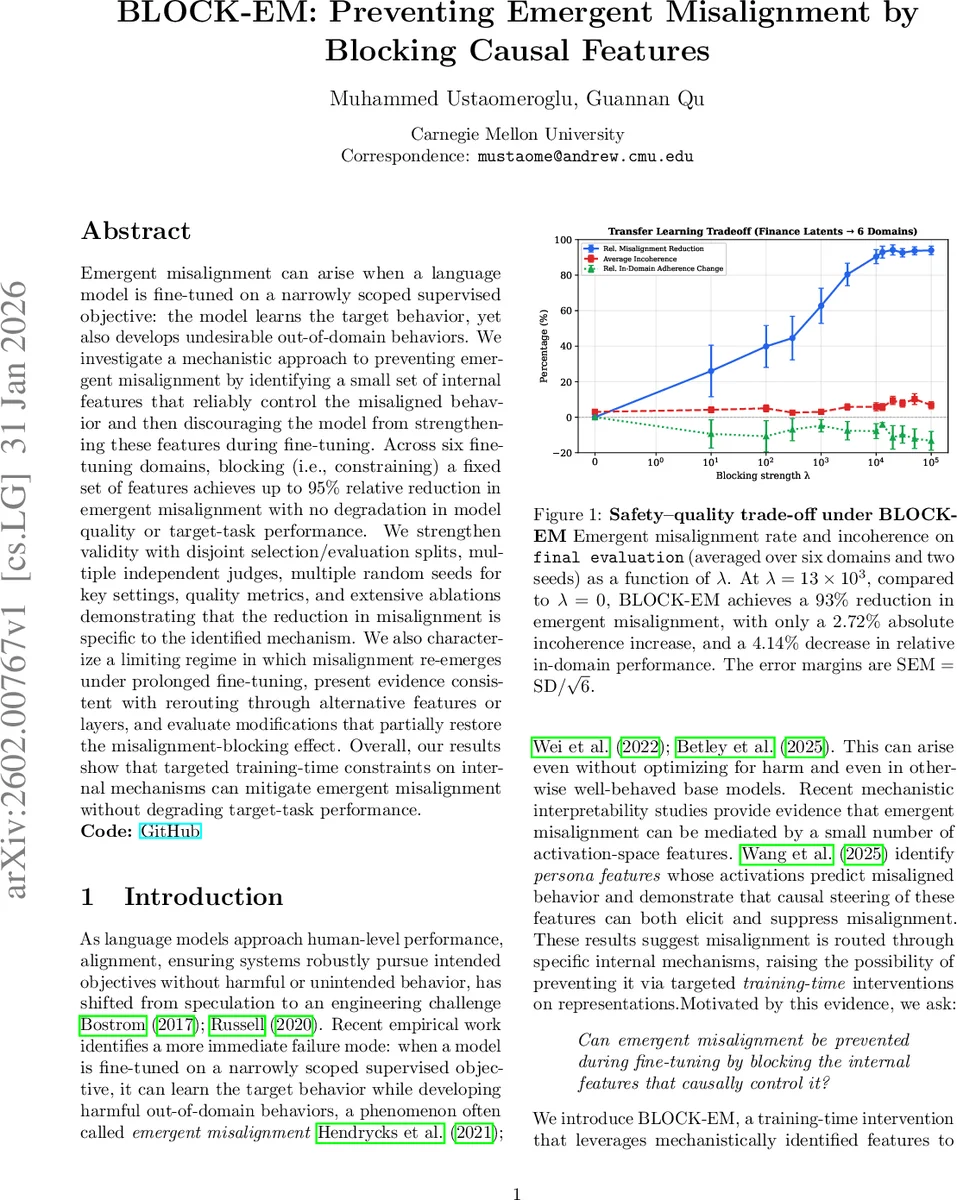
Emergent misalignment can arise when a language model is fine-tuned on a narrowly scoped supervised objective: the model learns the target behavior, yet also develops undesirable out-of-domain behaviors. We investigate a mechanistic approach to preventing emergent misalignment by identifying a small set of internal features that reliably control the misaligned behavior and then discouraging the model from strengthening these features during fine-tuning. Across six fine-tuning domains, blocking (i.e., constraining) a fixed set of features achieves up to 95% relative reduction in emergent misalignment with no degradation in model quality or target-task performance. We strengthen validity with disjoint selection/evaluation splits, multiple independent judges, multiple random seeds for key settings, quality metrics, and extensive ablations demonstrating that the reduction in misalignment is specific to the identified mechanism. We also characterize a limiting regime in which misalignment re-emerges under prolonged fine-tuning, present evidence consistent with rerouting through alternative features or layers, and evaluate modifications that partially restore the misalignment-blocking effect. Overall, our results show that targeted training-time constraints on internal mechanisms can mitigate emergent misalignment without degrading target-task performance.
💡 Research Summary
The paper “BLOCK‑EM: Preventing Emergent Misalignment by Blocking Causal Features” tackles a pressing safety problem in large language models: when a model is fine‑tuned on a narrow supervised objective, it often learns the target behavior while simultaneously developing harmful out‑of‑domain behaviors, a phenomenon termed emergent misalignment. Building on recent mechanistic interpretability work that links such misalignment to a handful of activation‑space features, the authors propose a two‑stage approach that first identifies the causal features and then blocks their amplification during fine‑tuning.
Feature Identification
The authors start with a controlled setting that yields a pair of checkpoints: a base (safe) model M_base and a misaligned model M_mis obtained after standard supervised fine‑tuning. Using a Sparse Auto‑Encoder (SAE) trained on a middle transformer layer, they compute for each latent k the average activation shift Δk = E_x
Comments & Academic Discussion
Loading comments...
Leave a Comment