Spectral Imbalance Causes Forgetting in Low-Rank Continual Adaptation
Parameter-efficient continual learning aims to adapt pre-trained models to sequential tasks without forgetting previously acquired knowledge. Most existing approaches treat continual learning as avoiding interference with past updates, rather than considering what properties make the current task-specific update naturally preserve previously acquired knowledge. From a knowledge-decomposition perspective, we observe that low-rank adaptations exhibit highly imbalanced singular value spectra: a few dominant components absorb most of the adaptation energy, thereby (i) more likely to disrupt previously acquired knowledge and (ii) making the update more vulnerable to interference from subsequent tasks. To enable explicit balance among components, we decouple the magnitude of the task update from its directional structure and formulate it as a constrained optimization problem on a restricted Stiefel manifold. We address this problem using a projected first-order method compatible with standard deep-learning optimizers used in vision-language models. Our method mitigates both backward and forward forgetting, consistently outperforming continual learning baselines. The implementation code is available at https://github.com/haodotgu/EBLoRA.
💡 Research Summary
The paper tackles the problem of catastrophic forgetting in parameter‑efficient continual learning, focusing on low‑rank adaptation (LoRA) of large pre‑trained vision‑language models. While most continual learning (CL) methods aim to avoid interference with past updates, the authors ask what intrinsic properties of a new task’s update naturally preserve prior knowledge. By decomposing LoRA updates ΔWₜ into singular‑value components ΔWₜ = Σᵢ σₜ,i uₜ,i vₜ,iᵀ, they reveal a pronounced spectral imbalance: a handful of dominant singular values capture the majority of adaptation energy, while many weaker components are suppressed. Empirically, this imbalance intensifies during training and leads to two detrimental effects: (i) the dominant components are more likely to overwrite previously learned representations (backward forgetting), and (ii) they become especially vulnerable to interference from subsequent tasks (forward forgetting).
To substantiate this, the authors conduct a controlled LoRA‑merging experiment. They fine‑tune separate LoRA adapters for each task, then merge them without further optimization. Direct merging causes a large drop in Normalized Accuracy Improvement (NAI), whereas smoothing the singular values (replacing each σₜ vector with its mean) before merging dramatically mitigates the drop, confirming that spectral imbalance drives cross‑task interference.
Motivated by these findings, the paper proposes Energy‑Balanced Low‑Rank Adaptation (EBLoRA). The key idea is to decouple the overall adaptation magnitude from the directional structure of the update: ΔWₜ = sₜ Uₜ Vₜᵀ, where sₜ ∈ ℝ controls the global scale, and Uₜ, Vₜ ∈ ℝ^{d×r} have orthonormal columns (Stiefel manifolds). Additionally, to prevent the new task from interfering with previously important directions, the authors enforce orthogonality between Uₜ and a matrix Gₜ₋₁ that stores representative gradient directions from earlier tasks (Gₜ₋₁ᵀ Uₜ = 0). This yields a restricted Stiefel manifold Mₜ defined by both orthonormality and linear constraints.
The continual learning objective for task t becomes a constrained optimization problem:
min_{sₜ, Uₜ∈Mₜ, Vₜ∈St(d,r)} Lₜ(W_{t‑1} + sₜ Uₜ Vₜᵀ).
To solve it efficiently, the authors design a projected first‑order algorithm that integrates seamlessly with standard deep‑learning optimizers (SGD, Adam). Each iteration consists of: (1) projecting Euclidean gradients onto the tangent space of Mₜ (first removing components violating the linear constraint via the projector P⊥_G, then applying the classic Stiefel tangent projection), (2) performing an optimizer step on the projected gradient, (3) re‑projecting the updated parameters to satisfy the constraints, and (4) retracting back onto the manifold using a whitening operation U⁺ = Y (YᵀY)^{‑½}, where Y = (I ‑ Gₜ₋₁ Gₜ₋₁ᵀ) Ũ. The retraction simultaneously restores orthonormality and the orthogonality to Gₜ₋₁. The authors prove that these projection and retraction steps are optimal under the Riemannian geometry of the restricted Stiefel manifold and provide convergence guarantees analogous to Riemannian SGD.
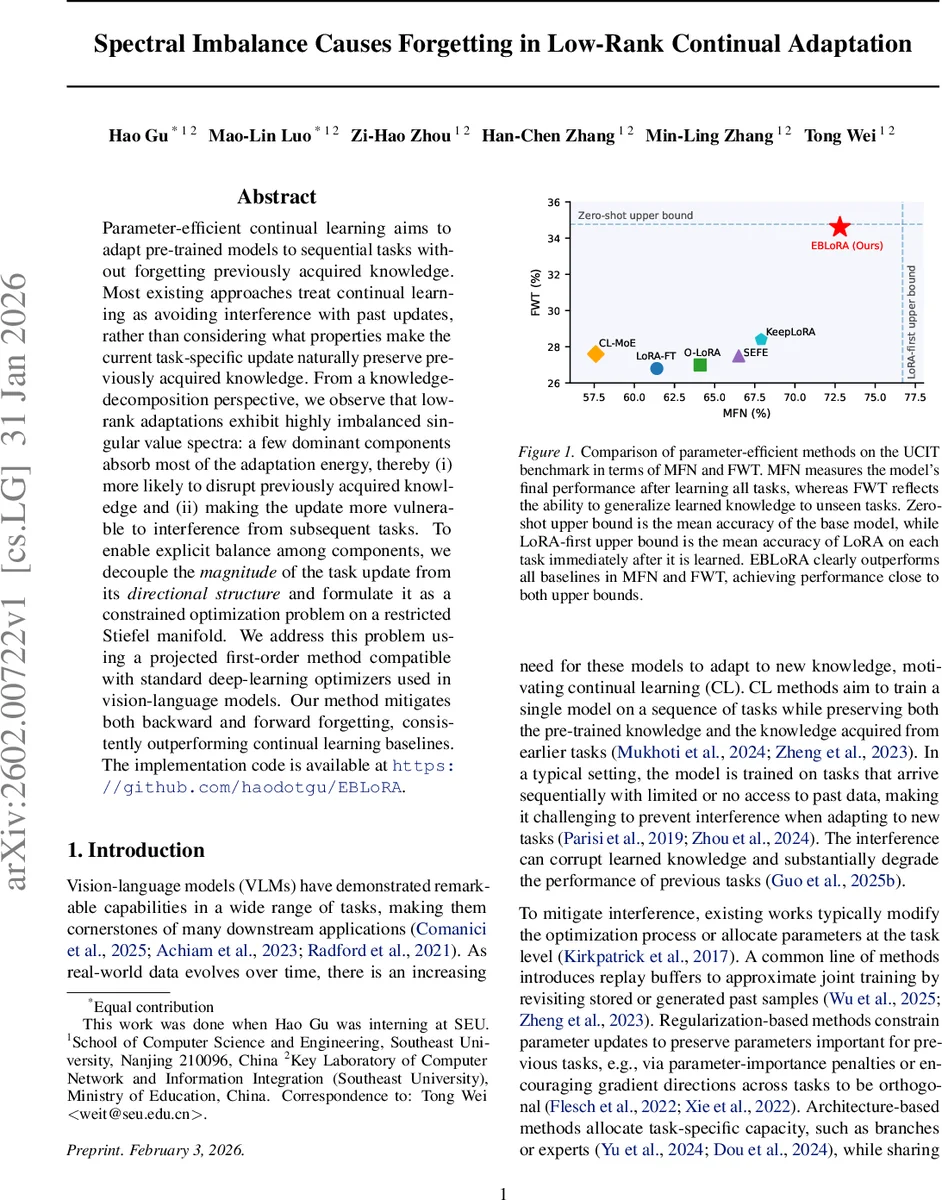
Extensive experiments are conducted on six diverse benchmarks (UCIT, ImageNet‑R, CLEVR, VizWiz, IconQA, Flickr30k) covering both classification and multimodal tasks. Two metrics are reported: Mean Final Accuracy (MFN) after learning all tasks, and Forward Transfer (FWT) measuring the ability to generalize to unseen tasks. EBLoRA consistently outperforms a wide range of baselines—including LoRA‑first, LoRA‑FT, replay‑based methods, regularization approaches (EWC, GPM), and architecture‑based methods (CL‑MoE, SEFE). Notably, EBLoRA’s performance lies close to both the zero‑shot upper bound (the pre‑trained model’s average accuracy) and the LoRA‑first upper bound (the accuracy immediately after each task’s fine‑tuning), indicating that balancing the singular‑value spectrum effectively bridges the gap between these extremes. Ablation studies show that removing the orthogonal constraint or the scalar scaling sₜ degrades performance substantially, confirming the importance of each component.
In summary, the paper makes four major contributions: (1) it introduces a knowledge‑component perspective on LoRA updates, identifying spectral imbalance as a root cause of forgetting; (2) it proposes a novel factorization that separates adaptation energy from directional structure, enabling explicit balance of knowledge components; (3) it formulates continual learning as a restricted Stiefel manifold optimization problem and provides an efficient projected algorithm compatible with existing deep‑learning pipelines; and (4) it validates the method both theoretically and empirically, demonstrating superior mitigation of backward and forward forgetting. This work reframes catastrophic forgetting not merely as an optimization issue but as a structural consequence of imbalanced low‑rank updates, and offers a practical, mathematically grounded solution that is likely to influence future research in parameter‑efficient continual learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment