JoyAvatar: Unlocking Highly Expressive Avatars via Harmonized Text-Audio Conditioning
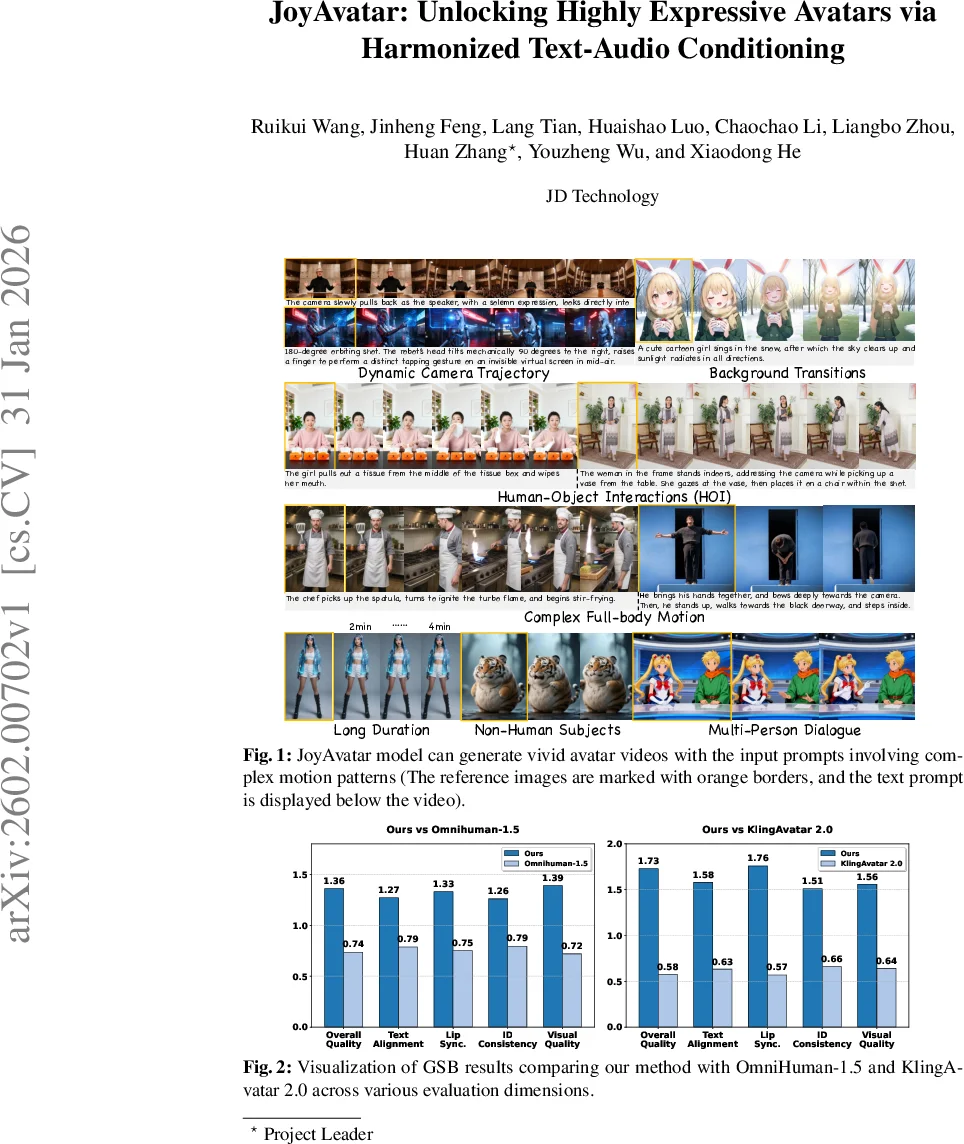
Existing video avatar models have demonstrated impressive capabilities in scenarios such as talking, public speaking, and singing. However, the majority of these methods exhibit limited alignment with respect to text instructions, particularly when the prompts involve complex elements including large full-body movement, dynamic camera trajectory, background transitions, or human-object interactions. To break out this limitation, we present JoyAvatar, a framework capable of generating long duration avatar videos, featuring two key technical innovations. Firstly, we introduce a twin-teacher enhanced training algorithm that enables the model to transfer inherent text-controllability from the foundation model while simultaneously learning audio-visual synchronization. Secondly, during training, we dynamically modulate the strength of multi-modal conditions (e.g., audio and text) based on the distinct denoising timestep, aiming to mitigate conflicts between the heterogeneous conditioning signals. These two key designs serve to substantially expand the avatar model’s capacity to generate natural, temporally coherent full-body motions and dynamic camera movements as well as preserve the basic avatar capabilities, such as accurate lip-sync and identity consistency. GSB evaluation results demonstrate that our JoyAvatar model outperforms the state-of-the-art models such as Omnihuman-1.5 and KlingAvatar 2.0. Moreover, our approach enables complex applications including multi-person dialogues and non-human subjects role-playing. Some video samples are provided on https://joyavatar.github.io/.
💡 Research Summary
**
JoyAvatar introduces a novel framework for generating long‑duration, highly expressive avatar videos that are tightly aligned with both textual instructions and audio cues. The authors identify two fundamental limitations of existing audio‑driven avatar models: (1) weak text controllability, especially for complex prompts involving full‑body motion, dynamic camera trajectories, background changes, and human‑object interactions; and (2) conflicts between multimodal conditioning signals (audio, text, reference image) that degrade the model’s ability to follow text instructions.
To overcome these challenges, JoyAvatar proposes two key technical innovations. First, a Twin‑Teacher Enhanced Distribution Matching Distillation (DMD) scheme is employed. In addition to the conventional audio‑driven teacher (the base avatar model obtained after pre‑training), a large‑scale video‑foundation model (Wan2.2‑I2V‑14B) is introduced as a second teacher that excels at text‑driven generation. During post‑training, the student avatar model receives gradient supervision from both teachers: the audio teacher guides lip‑sync and rhythmic motion, while the text teacher supplies expert‑level semantic alignment for complex actions and camera movements. This dual‑teacher setup enables the student to disentangle competing modality biases without requiring new, diverse training data.
Second, the authors design a time‑step‑conditioned dynamic Classifier‑Free Guidance (CFG) strategy. Recognizing that early (high‑noise) diffusion steps primarily shape global motion patterns, while later (low‑noise) steps refine fine visual details, they modulate the CFG scales for text and audio separately across timesteps. Text CFG is set high in early steps to prioritize semantic alignment, whereas audio CFG is kept low initially and gradually increased in later steps to ensure precise lip‑sync and subtle hand gestures. This scheduling mitigates inter‑modality conflicts and lets each condition exert influence when it is most effective.
The overall architecture consists of a 3D VAE that encodes video clips into a compact latent space, a FramePack module that stitches motion frames for unlimited video length, and a DiT‑based video diffusion backbone. After an initial pre‑training phase (training FramePack and self‑attention, then adding audio cross‑attention with pretrained Wave2Vec2 features), the model possesses basic audio‑controllable avatar capabilities. The subsequent twin‑teacher DMD with dynamic CFG refines text controllability and reduces the number of denoising steps, improving inference efficiency.
Extensive experiments using the Generalized Subjective Benchmark (GSB) demonstrate that JoyAvatar outperforms state‑of‑the‑art models such as Omnihuman‑1.5 and KlingAvatar 2.0 across four dimensions: text alignment, lip‑sync accuracy, identity consistency, and visual quality. Qualitative examples include multi‑minute scenes where a girl picks up a chocolate box, a chef ignites a flame and stir‑fries, and a robot performs a 180‑degree orbit while tapping a virtual screen—each faithfully following detailed textual prompts. The model also supports multi‑person dialogues and non‑human role‑playing, showcasing its versatility for cinematic content creation.
In summary, JoyAvatar’s contributions are: (1) a twin‑teacher DMD approach that injects strong text‑driven supervision without new data; (2) a dynamic CFG schedule that harmonizes audio and text conditioning across diffusion timesteps; and (3) a unified avatar generation system that achieves state‑of‑the‑art performance on complex, long‑form video generation tasks, opening avenues for real‑time interactive media, games, and VR/AR applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment