High-Fidelity Generative Audio Compression at 0.275kbps
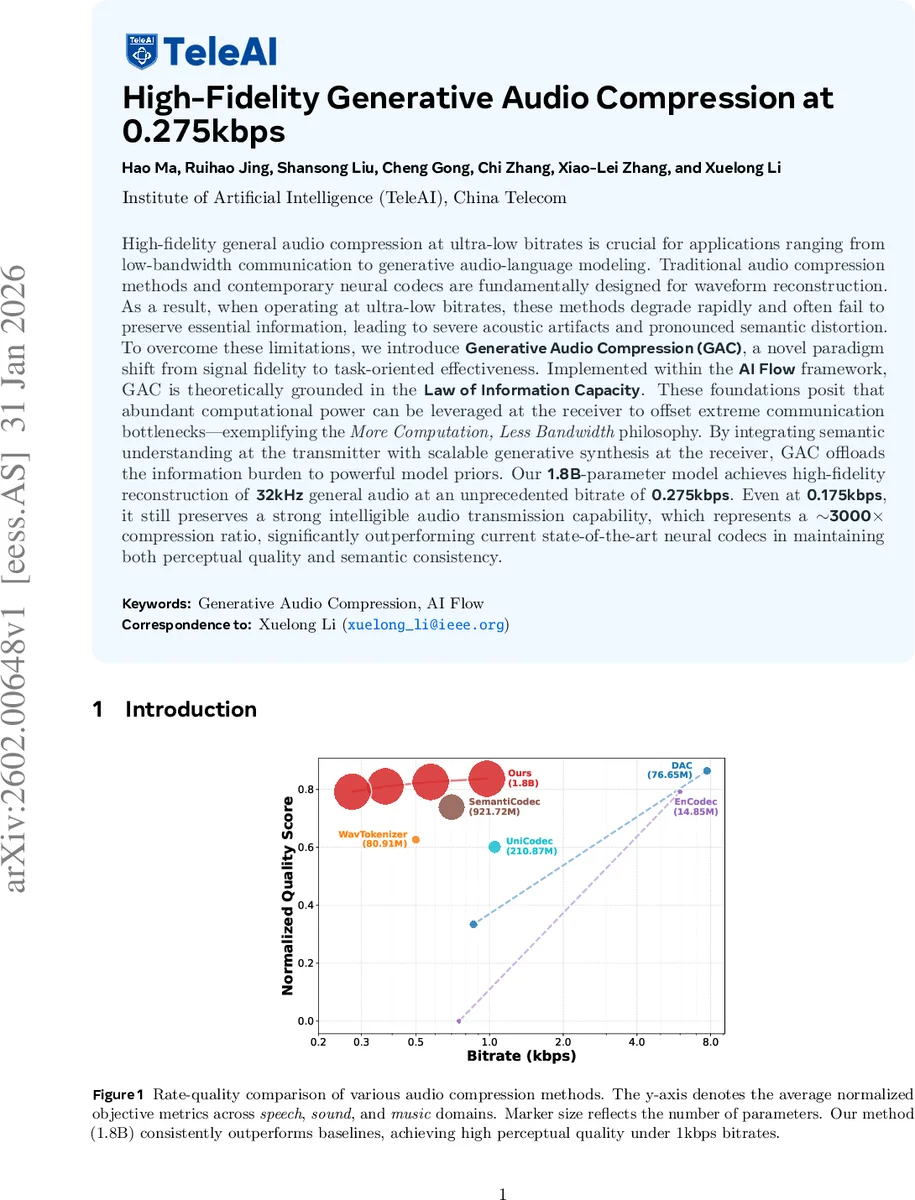
High-fidelity general audio compression at ultra-low bitrates is crucial for applications ranging from low-bandwidth communication to generative audio-language modeling. Traditional audio compression methods and contemporary neural codecs are fundamentally designed for waveform reconstruction. As a result, when operating at ultra-low bitrates, these methods degrade rapidly and often fail to preserve essential information, leading to severe acoustic artifacts and pronounced semantic distortion. To overcome these limitations, we introduce Generative Audio Compression (GAC), a novel paradigm shift from signal fidelity to task-oriented effectiveness. Implemented within the AI Flow framework, GAC is theoretically grounded in the Law of Information Capacity. These foundations posit that abundant computational power can be leveraged at the receiver to offset extreme communication bottlenecks–exemplifying the More Computation, Less Bandwidth philosophy. By integrating semantic understanding at the transmitter with scalable generative synthesis at the receiver, GAC offloads the information burden to powerful model priors. Our 1.8B-parameter model achieves high-fidelity reconstruction of 32kHz general audio at an unprecedented bitrate of 0.275kbps. Even at 0.175kbps, it still preserves a strong intelligible audio transmission capability, which represents an about 3000x compression ratio, significantly outperforming current state-of-the-art neural codecs in maintaining both perceptual quality and semantic consistency.
💡 Research Summary
The paper introduces Generative Audio Compression (GAC), a novel framework that shifts the focus of audio compression from traditional waveform reconstruction to a task‑oriented, semantics‑driven approach. Conventional codecs and recent neural audio codecs aim to faithfully reproduce the raw signal, which leads to rapid degradation when the bitrate drops to ultra‑low levels (below a few kilobits per second). GAC tackles this problem by exploiting the “More Computation, Less Bandwidth” principle, grounded in the Law of Information Capacity (IC‑1) and the AI Flow theoretical framework.
Theoretical foundation
IC‑1 states that the information captured by a model (η N) equals the reduction in dataset entropy (D·(H − L)), where N is the number of parameters, D the amount of training data, H the intrinsic entropy, L the cross‑entropy loss, and η the efficiency per parameter. By equating the residual loss L with the transmission rate R (L ≡ R), the authors derive H = R + η N D. This equation formalizes a zero‑sum trade‑off: decreasing R requires increasing the model’s capacity (η N D). Consequently, a sufficiently large generative model can reconstruct high‑fidelity audio from a highly compressed representation.
Methodology
GAC consists of two stages:
-
Semantic Encoder (Stage 1) – The encoder maps the input audio X to a discrete latent token sequence Z. Using the Information Bottleneck principle, the objective maximizes mutual information between Z and a textual description Y (I(Z;Y)) while minimizing mutual information between Z and the raw audio (I(Z;X)). Practically, a pre‑trained large language model provides the conditional Pθ(Y|Z), encouraging Z to capture semantic content. A KL regularizer against a uniform prior ensures high token utilization and prevents collapse.
-
Generative Decoder (Stage 2) – Conditioned on Z, a large‑scale rectified flow matching model (a type of normalizing flow) learns a velocity field vθ that transports a standard Gaussian X₀ to the data distribution X₁. The loss penalizes the L2 distance between the predicted velocity and the true displacement (X₁ − X₀). At inference, solving the associated ODE yields the reconstructed waveform ˆX. The decoder’s expressive power directly corresponds to the term η N D in the theoretical bound, allowing it to synthesize fine acoustic details that were omitted during encoding.
Experiments
The authors evaluate GAC on three domains—speech, general sound, and music—using datasets SeedTTS‑test, AudioCaps‑test, and MUSDB18‑test, respectively. Objective metrics include DNSMOS, NISQA, FAD, KL divergence, Inception Score, Aesthetic Score, speaker similarity (SIM), and error rates (CER/WER). GAC, with a 1.8 B‑parameter model, operates at 0.275 kbps (and still functional at 0.175 kbps), achieving:
- Speech: MOS ≈ 4.1, SIM ≈ 0.80, CER < 5 %; superior to EnCodec, UniCodec, SemantiCodec.
- Sound: FAD ≈ 130, KL ≈ 0.11; markedly lower than baselines.
- Music: Similar gains in FAD, KL, and aesthetic scores.
Subjective listening tests (MUSHRA) confirm that listeners rate GAC’s output close to high‑bitrate references, indicating that the generative prior successfully restores perceptual quality despite the extreme compression ratio (~3000×).
Strengths
- Strong theoretical grounding linking compression rate to model capacity.
- Innovative two‑stage pipeline that explicitly separates semantic extraction from generative reconstruction.
- Empirical results demonstrate unprecedented quality at sub‑kilobit per second bitrates across diverse audio types.
- Comprehensive evaluation with both objective and subjective metrics.
Weaknesses and open questions
- The 1.8 B‑parameter decoder is computationally heavy, limiting real‑time or edge‑device deployment.
- Dependence on textual annotations for the encoder raises concerns about scalability to unlabeled audio corpora.
- The paper does not explore latency, memory footprint, or energy consumption, which are critical for practical low‑bandwidth scenarios.
- Generalization to languages or acoustic environments not seen during training remains untested.
Future directions suggested include model distillation or pruning for efficiency, self‑supervised semantic token learning without explicit text, and extending the framework to multilingual or multimodal settings.
Conclusion
Generative Audio Compression redefines ultra‑low‑bitrate audio transmission by offloading most of the information burden to a powerful generative model at the receiver. By leveraging semantic understanding and large‑scale generative synthesis, GAC achieves high‑fidelity, semantically consistent reconstruction at 0.275 kbps—far surpassing existing neural codecs. This work opens a promising avenue for bandwidth‑constrained applications such as remote communication, streaming in low‑connectivity regions, and audio‑language multimodal model training, while also highlighting the need for further research on efficiency and label‑free semantics.
Comments & Academic Discussion
Loading comments...
Leave a Comment