Kernelized Edge Attention: Addressing Semantic Attention Blurring in Temporal Graph Neural Networks
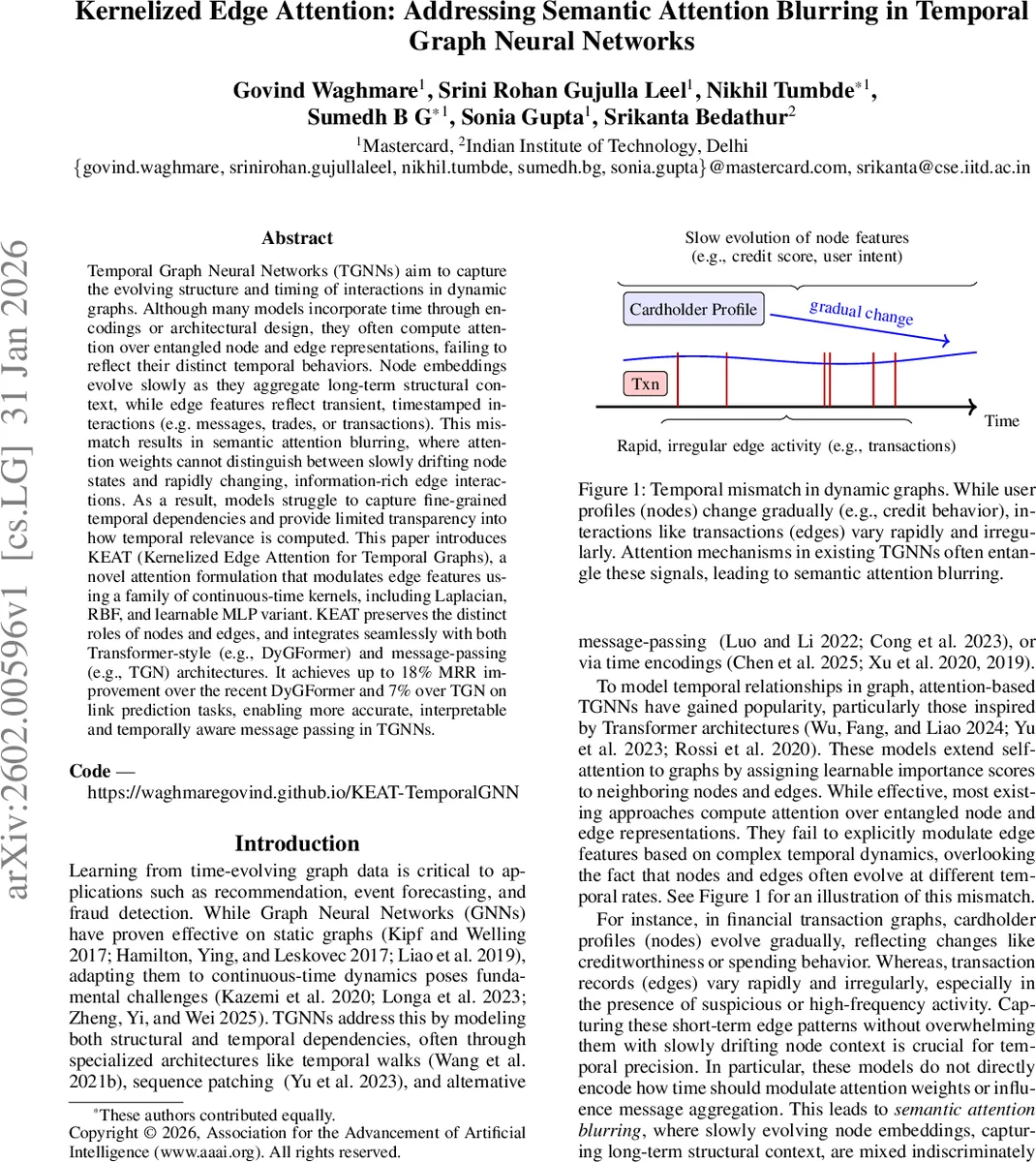
Temporal Graph Neural Networks (TGNNs) aim to capture the evolving structure and timing of interactions in dynamic graphs. Although many models incorporate time through encodings or architectural design, they often compute attention over entangled node and edge representations, failing to reflect their distinct temporal behaviors. Node embeddings evolve slowly as they aggregate long-term structural context, while edge features reflect transient, timestamped interactions (e.g. messages, trades, or transactions). This mismatch results in semantic attention blurring, where attention weights cannot distinguish between slowly drifting node states and rapidly changing, information-rich edge interactions. As a result, models struggle to capture fine-grained temporal dependencies and provide limited transparency into how temporal relevance is computed. This paper introduces KEAT (Kernelized Edge Attention for Temporal Graphs), a novel attention formulation that modulates edge features using a family of continuous-time kernels, including Laplacian, RBF, and learnable MLP variant. KEAT preserves the distinct roles of nodes and edges, and integrates seamlessly with both Transformer-style (e.g., DyGFormer) and message-passing (e.g., TGN) architectures. It achieves up to 18% MRR improvement over the recent DyGFormer and 7% over TGN on link prediction tasks, enabling more accurate, interpretable and temporally aware message passing in TGNNs.
💡 Research Summary
Temporal Graph Neural Networks (TGNNs) have become a cornerstone for modeling dynamic relational data in domains such as recommendation, fraud detection, and event forecasting. Existing TGNNs typically incorporate time either through explicit time‑encoding functions or by designing specialized architectures (e.g., temporal walks, patch‑based attention). However, most attention‑based TGNNs (including TransformerConv, TGN, DyGFormer) compute attention scores over a sum of projected node and edge features. In this formulation, the temporal encoding is merely concatenated with edge attributes and then treated the same as static node embeddings. Consequently, the attention mechanism cannot distinguish between slowly evolving node states (which capture long‑term structural context) and rapidly changing edge interactions (which carry recent, information‑rich signals). This phenomenon, which the authors term “semantic attention blurring,” leads to two major drawbacks: (1) loss of temporal fidelity—recent events are not given higher importance than older ones, and (2) reduced interpretability—attention weights do not reflect the true temporal relevance of each neighbor.
The paper introduces KEAT (Kernelized Edge Attention for Temporal Graphs), a novel attention formulation that directly injects temporal awareness into the attention computation by modulating edge‑time features with continuous‑time kernels. The key idea is simple: before the key and value projections, the concatenated edge feature (\bar e_{ij} =
Comments & Academic Discussion
Loading comments...
Leave a Comment