Cross-Modal Memory Compression for Efficient Multi-Agent Debate
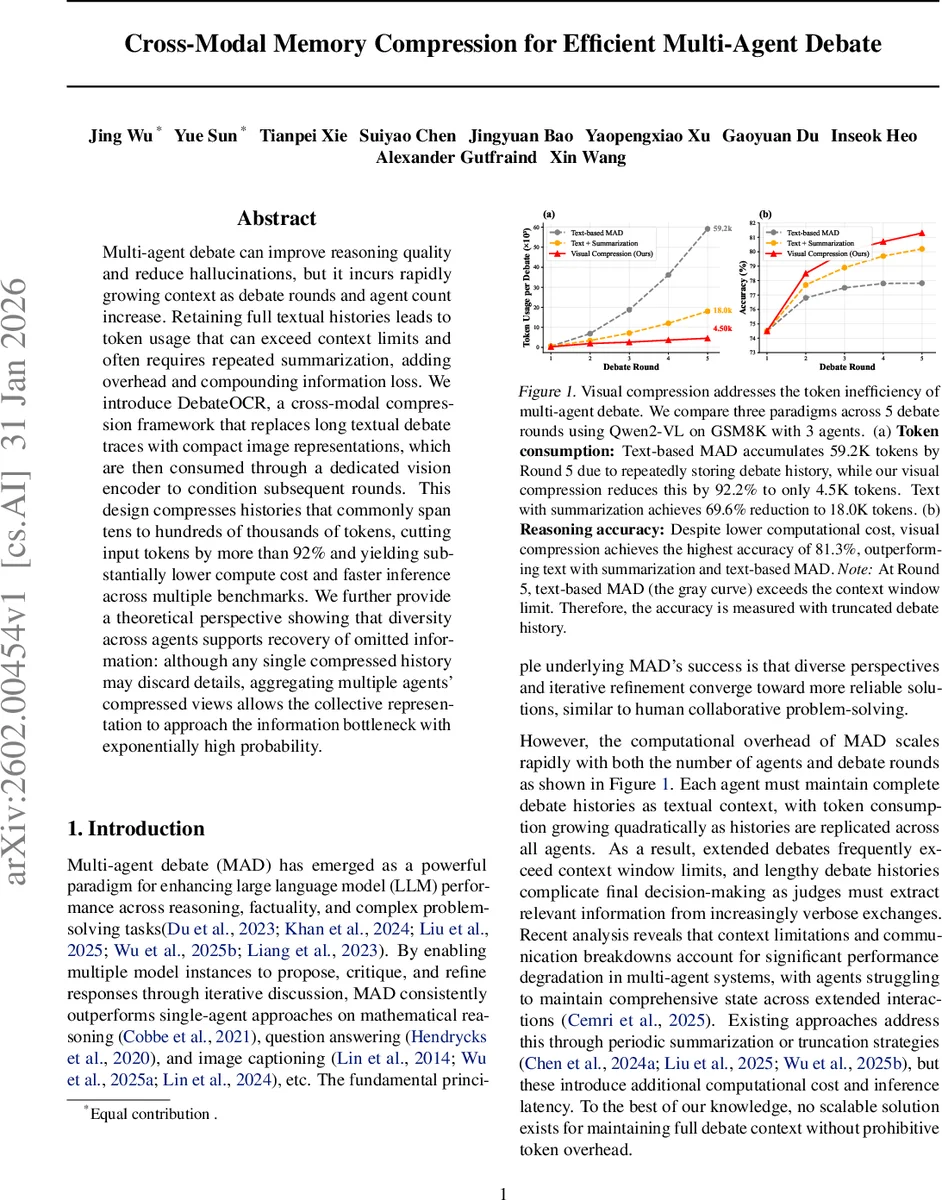
Multi-agent debate can improve reasoning quality and reduce hallucinations, but it incurs rapidly growing context as debate rounds and agent count increase. Retaining full textual histories leads to token usage that can exceed context limits and often requires repeated summarization, adding overhead and compounding information loss. We introduce DebateOCR, a cross-modal compression framework that replaces long textual debate traces with compact image representations, which are then consumed through a dedicated vision encoder to condition subsequent rounds. This design compresses histories that commonly span tens to hundreds of thousands of tokens, cutting input tokens by more than 92% and yielding substantially lower compute cost and faster inference across multiple benchmarks. We further provide a theoretical perspective showing that diversity across agents supports recovery of omitted information: although any single compressed history may discard details, aggregating multiple agents’ compressed views allows the collective representation to approach the information bottleneck with exponentially high probability.
💡 Research Summary
The paper tackles a critical scalability bottleneck in Multi‑Agent Debate (MAD), where each round’s full textual history must be fed to every participating language model. As the number of agents (K) and debate rounds (R) increase, the total token consumption grows quadratically (O(K²R²L)), quickly exceeding the context windows of even the largest LLMs and forcing costly summarization steps that introduce information loss. To overcome this, the authors propose DebateOCR, a cross‑modal compression framework that converts the entire debate transcript into a high‑resolution image and then encodes it with a dedicated vision pipeline, yielding a fixed‑size set of vision tokens that replace the original text in each agent’s context.
The vision pipeline combines a frozen Segment‑Anything Model (SAM) for fine‑grained spatial feature extraction with a frozen CLIP‑Large model for semantic embedding. A lightweight adapter network, trained once per target multimodal LLM, projects the fused SAM‑CLIP features into the LLM’s vision‑token space. Training uses a reconstruction objective: given rendered debate images, the adapter must enable the LLM to recover the original text, encouraging the encoder to retain task‑relevant semantics while discarding redundant characters. Because SAM, CLIP, and the LLM remain frozen, training is fast and the adapter can be reused across different debate scenarios without further fine‑tuning.
During inference, each round’s accumulated history Hᵣ is rendered as a structured image (e.g., with line breaks, speaker tags, and indentation). The image passes through the SAM‑CLIP‑adapter pipeline, producing a constant‑size token sequence (typically 256‑512 tokens). These vision tokens are injected into every agent’s prompt, reducing per‑round token cost from K·|Hᵣ| to O(N), where N is the fixed number of vision tokens. Consequently, total token usage drops from O(K²R²L) to O(K·R·N), a reduction of over 92 % in the authors’ experiments.
A key theoretical contribution is the “diversity‑based information recovery” analysis. The authors model each compressed visual representation as a stochastic projection of the original text. While any single compression inevitably discards some information, different agents generate independent visual views that preserve complementary subsets of the signal. By aggregating the agents’ outputs (e.g., majority vote or weighted consensus), the system can reconstruct the original information with exponentially high probability as the number of diverse agents grows. This argument is framed within the Information Bottleneck theory, showing that the collective compressed representation converges to the optimal bottleneck despite aggressive per‑agent compression.
Empirically, the framework is evaluated on three reasoning benchmarks—GSM8K (arithmetic word problems), MATH (high‑school and competition math), and GPQA (expert‑level multiple‑choice questions)—using four state‑of‑the‑art vision‑language models: Qwen2.5‑VL‑7B, Llama‑3.2‑11B‑Vision, InternVL2‑8B, and Pixtral‑12B. Compared with (1) pure text‑based MAD and (2) text‑plus‑summarization baselines, DebateOCR consistently achieves >92 % token reduction, faster inference (≈30 % speed‑up), and higher accuracy. For example, on a five‑round GSM8K debate with three agents, the text‑only baseline consumes 59 K tokens and drops to 73 % accuracy due to truncation, the summarization baseline uses 18 K tokens and reaches 77 % accuracy, while DebateOCR uses only 4.5 K tokens and attains 81.3 % accuracy—the best among all methods.
The paper highlights three practical advantages: (1) seamless integration with existing MAD pipelines—no architectural changes to the agents are required; (2) elimination of summarization, preserving the full logical flow of the debate; (3) richer contextual encoding, as vision tokens capture layout and relational cues that plain text tokens miss. Limitations include the added GPU memory for image rendering and vision encoding, a fixed image resolution that may become sub‑optimal for extremely long debates, and potential domain mismatch between the vision encoder’s pretraining data and specialized reasoning tasks.
Future work suggested by the authors includes adaptive token budgets (varying N based on debate length), lighter vision encoders for real‑time deployment, cross‑domain adapter fine‑tuning (e.g., legal or medical texts), and privacy analyses of storing debate histories as images.
In summary, DebateOCR introduces a novel cross‑modal compression strategy that dramatically reduces the token footprint of multi‑agent debates while leveraging agent diversity to recover any lost information. This work opens a new pathway for scaling collaborative LLM systems beyond current context limits, enabling deeper, more iterative reasoning without sacrificing performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment