Language-based Trial and Error Falls Behind in the Era of Experience
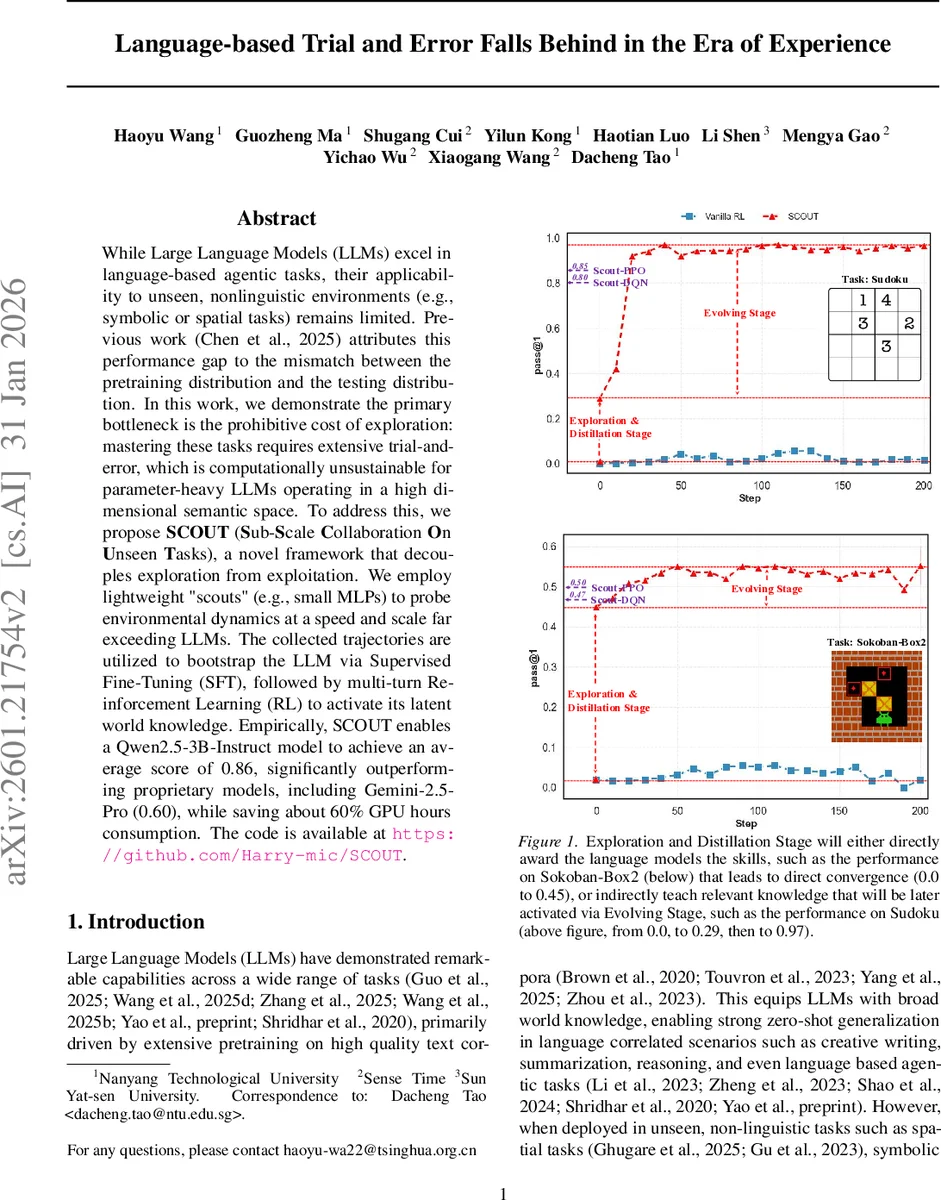
While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight “scouts” (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
💡 Research Summary
The paper tackles a fundamental limitation of large language models (LLMs) when they are deployed in non‑linguistic environments such as symbolic puzzles, spatial navigation, or long‑horizon planning tasks. While LLMs excel at language‑driven agentic tasks, their performance drops dramatically on these “unseen” tasks. Prior work attributes the gap to a distribution mismatch between pre‑training data and test environments, but the authors argue that the real bottleneck is the prohibitive cost of exploration. An LLM must generate tokens from a vocabulary of tens of thousands while simultaneously searching a high‑dimensional semantic action space, which is orders of magnitude larger than the discrete action spaces required by most symbolic tasks. This mismatch leads to inefficient exploration and excessive GPU consumption.
To overcome this, the authors introduce SCOUT (Sub‑Scale Collaboration On Unseen Tasks), a three‑stage framework that decouples exploration from exploitation. In the Exploration Stage, lightweight “scouts” – small multilayer perceptrons or convolutional networks – are trained with classic reinforcement‑learning algorithms (DQN, PPO) directly on the symbolic MDP of each task. Because scouts have far fewer parameters and no token‑generation overhead, they can interact with the environment at a frequency many times higher than an LLM, rapidly learning the transition dynamics and producing high‑quality expert trajectories (D_scout).
The Distillation Stage bridges the modality gap. A deterministic trajectory‑to‑text transformer (the “textualizer” Φ) converts each scout trajectory into a multi‑turn dialogue format that LLMs can ingest (including state descriptions, actions, and rewards, while leaving the
In the Evolving Stage, the warmed‑up LLM is further refined through multi‑turn reinforcement learning. Unlike standard RLHF, which optimizes a single response, the authors apply trajectory‑level PPO that maximizes the expected cumulative discounted reward over the entire interaction history while maintaining a KL‑penalty to a reference policy. Crucially, the model is now encouraged to generate meaningful
Experiments span a suite of symbolic and spatial benchmarks: FrozenLake, Sokoban, Sudoku, 2048, and Rubik’s Cube. Using the Qwen‑2.5‑3B‑Instruct model as the LLM, SCOUT achieves an average score of 0.86, dramatically outperforming proprietary baselines such as Gemini‑2.5‑Pro (0.60). Moreover, because the exploration burden is shouldered by the scouts, total GPU consumption is reduced by roughly 60 % compared to an LLM‑only pipeline, with scouts accounting for only about 40 % of the total compute time.
Key contributions of the work include:
- Identification of exploration cost as the primary bottleneck for LLMs in non‑linguistic tasks.
- A novel decoupling architecture that leverages lightweight agents for rapid environment mastery.
- A systematic trajectory‑to‑text conversion that enables seamless knowledge transfer from scouts to LLMs without hand‑crafted rules.
- Multi‑turn PPO fine‑tuning that activates latent reasoning capabilities (the
blocks) and refines policies beyond the ceiling imposed by the scouts. - Empirical validation across diverse OOD tasks, demonstrating both superior performance and substantial compute savings.
In summary, SCOUT provides a practical and scalable pathway for large language models to acquire competence in unseen, high‑dimensional, non‑linguistic environments. By offloading the expensive exploration phase to compact neural agents and then distilling their expertise into the LLM, the framework unlocks the latent world knowledge of LLMs while keeping computational demands tractable. This work paves the way for future research that combines the expressive power of LLMs with the efficiency of specialized agents to tackle a broader class of real‑world problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment