When LLM Agents Meet Graph Optimization: An Automated Data Quality Improvement Approach
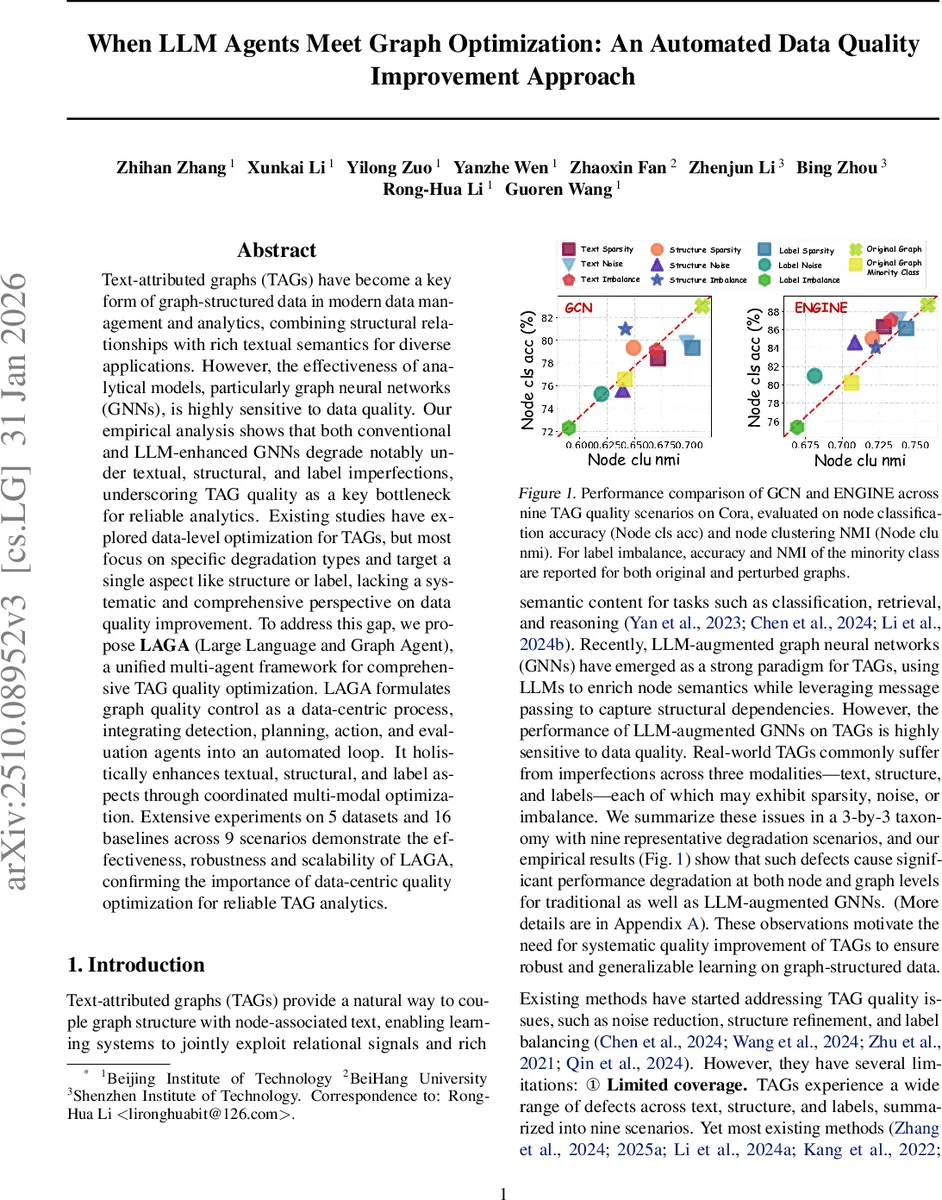
Text-attributed graphs (TAGs) have become a key form of graph-structured data in modern data management and analytics, combining structural relationships with rich textual semantics for diverse applications. However, the effectiveness of analytical models, particularly graph neural networks (GNNs), is highly sensitive to data quality. Our empirical analysis shows that both conventional and LLM-enhanced GNNs degrade notably under textual, structural, and label imperfections, underscoring TAG quality as a key bottleneck for reliable analytics. Existing studies have explored data-level optimization for TAGs, but most focus on specific degradation types and target a single aspect like structure or label, lacking a systematic and comprehensive perspective on data quality improvement. To address this gap, we propose LAGA (Large Language and Graph Agent), a unified multi-agent framework for comprehensive TAG quality optimization. LAGA formulates graph quality control as a data-centric process, integrating detection, planning, action, and evaluation agents into an automated loop. It holistically enhances textual, structural, and label aspects through coordinated multi-modal optimization. Extensive experiments on 5 datasets and 16 baselines across 9 scenarios demonstrate the effectiveness, robustness and scalability of LAGA, confirming the importance of data-centric quality optimization for reliable TAG analytics.
💡 Research Summary
Text‑attributed graphs (TAGs) combine node‑level textual content with graph structure, enabling powerful relational learning for tasks such as node classification, link prediction, and clustering. However, real‑world TAGs frequently suffer from a spectrum of defects across three modalities—text, structure, and labels—each of which can manifest as sparsity, noise, or imbalance. The authors empirically demonstrate that both conventional GNNs and recent LLM‑augmented GNNs experience substantial performance drops when any of these nine degradation types are present, highlighting data quality as a critical bottleneck. Existing work typically addresses a single modality or a single defect type, leaving a gap for a systematic, holistic solution.
To fill this gap, the paper introduces LAGA (Large Language and Graph Agent), a unified, automated framework that treats TAG quality control as a data‑centric optimization problem. LAGA consists of four specialized agents that operate in a closed‑loop pipeline:
-
Detection Agent – Quantifies defects using explicit metrics. Text sparsity is measured by token length, noise by an error‑rate estimate, and imbalance by average TF‑IDF. Structural issues are assessed after Louvain community detection via average degree, edge density, structural entropy, Jaccard similarity, and coefficient of variation of the degree distribution. Label problems are identified through the proportion of unlabeled nodes, neighborhood majority‑vote confidence, and class distribution skew. The agent outputs a global‑local report (R_det) that summarizes both overall quality and localized problem locations.
-
Planning Agent – Leverages a large language model (LLM) to interpret the detection report. It maps each of the nine issues to a severity level (0–3) and, using pre‑defined rule weights, derives a priority ordering (π). Based on the average severity across modalities, the agent computes loss‑weight coefficients (α, β, γ) that sum to one, ensuring that subsequent model training balances text, structure, and label losses according to the observed deficiencies. The agent also solves a cost‑aware planning problem: it selects a subset of actions from a predefined library (text cleaning, edge reconstruction, label regeneration, etc.) that maximizes expected quality gain while respecting a budget constraint, yielding an optimized action plan P*.
-
Action Agent – Executes the plan. It integrates graph learning and graph optimization through a dual‑encoder architecture: a semantic encoder (LLM‑based) processes node texts, while a structural encoder (GCN) captures topology. Textual improvement is performed by LLM‑generated summaries, keywords, and pseudo‑labels, feeding into a semantic loss L_sem. Structural improvement uses a GCN to produce node embeddings and a link predictor that estimates edge probabilities, contributing to a structural loss L_struct. Both losses are combined with a label loss L_label using the previously computed weights (α, β, γ). This joint optimization allows cross‑modality information to reinforce each other, preventing the inconsistencies that arise when modalities are optimized in isolation.
-
Evaluation Agent – After each iteration, the optimized TAG is fed to a suite of downstream GNN/LLM‑GNN backbones. Standard metrics (node classification accuracy, clustering NMI, etc.) are measured and compared against the original graph. Results are fed back to the Detection Agent, enabling further refinement cycles until convergence or budget exhaustion.
The authors conduct extensive experiments on five datasets (including Cora, Citeseer, PubMed, and two domain‑specific graphs) across nine degradation scenarios and sixteen baseline methods. LAGA consistently outperforms all baselines, achieving an average improvement of 7.3 percentage points in node classification accuracy and 5.8 percentage points in clustering NMI. The gains are especially pronounced in compound‑defect settings (e.g., simultaneous text noise and structural sparsity), where LAGA’s multi‑modal coordination yields up to double the performance increase of the best prior method. Moreover, the LLM‑driven planning component selects action sequences that converge 1.6× faster than random or static‑rule baselines, demonstrating both effectiveness and efficiency.
Key contributions are: (1) a comprehensive 3 × 3 taxonomy of TAG quality issues, (2) an LLM‑guided dynamic planning mechanism that balances severity, cost, and priority, and (3) a multi‑agent, dual‑encoder system that jointly optimizes text, structure, and labels. Limitations include the need for domain‑specific threshold tuning in the detection stage and reliance on handcrafted LLM prompts for planning. Future work may explore automatic threshold learning, richer action libraries, and real‑time streaming graph scenarios. Overall, the paper convincingly argues that data‑centric quality improvement, orchestrated by LLM‑powered agents, is essential for reliable graph analytics in modern, text‑rich networked data.
Comments & Academic Discussion
Loading comments...
Leave a Comment