The Blessing of Dimensionality in LLM Fine-tuning: A Variance-Curvature Perspective
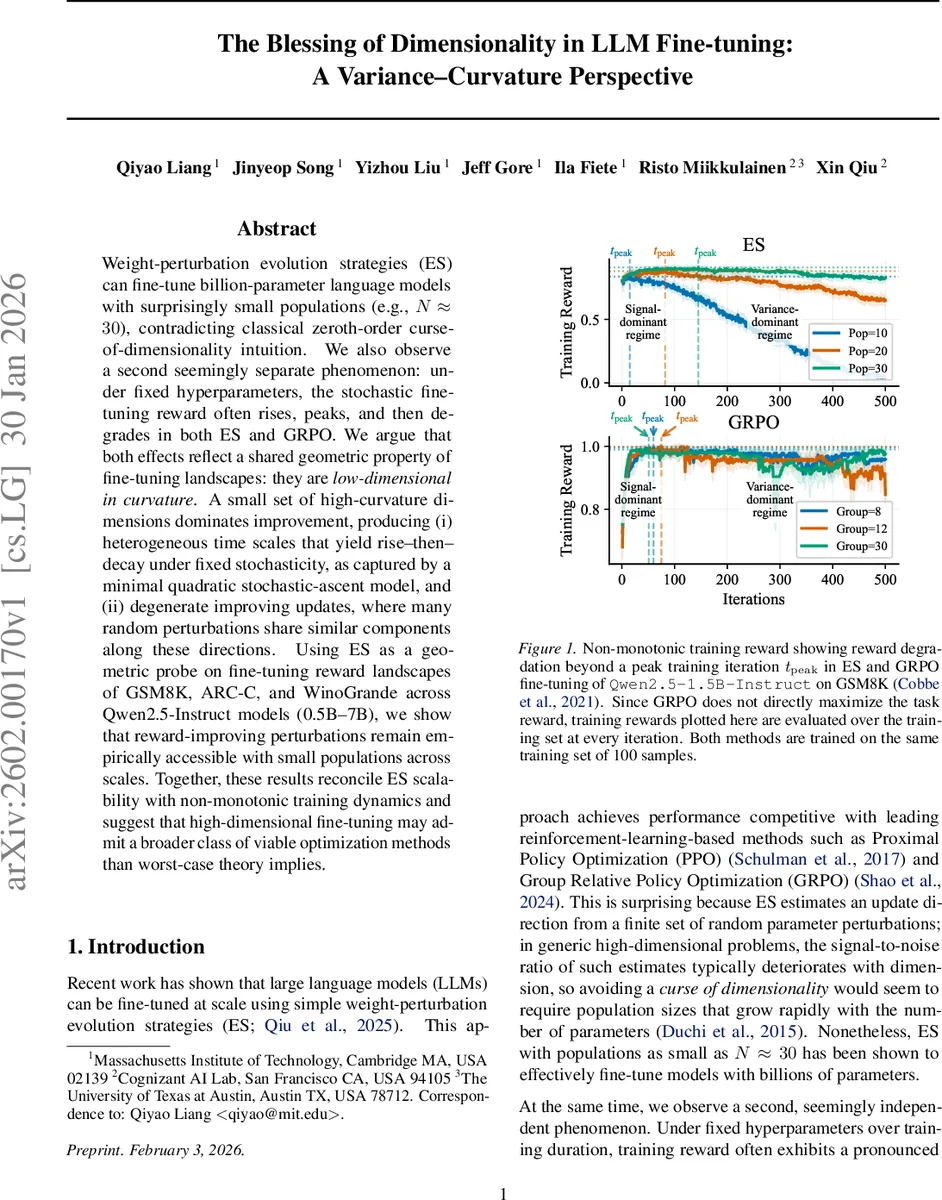
Weight-perturbation evolution strategies (ES) can fine-tune billion-parameter language models with surprisingly small populations (e.g., $N!\approx!30$), contradicting classical zeroth-order curse-of-dimensionality intuition. We also observe a second seemingly separate phenomenon: under fixed hyperparameters, the stochastic fine-tuning reward often rises, peaks, and then degrades in both ES and GRPO. We argue that both effects reflect a shared geometric property of fine-tuning landscapes: they are low-dimensional in curvature. A small set of high-curvature dimensions dominates improvement, producing (i) heterogeneous time scales that yield rise-then-decay under fixed stochasticity, as captured by a minimal quadratic stochastic-ascent model, and (ii) degenerate improving updates, where many random perturbations share similar components along these directions. Using ES as a geometric probe on fine-tuning reward landscapes of GSM8K, ARC-C, and WinoGrande across Qwen2.5-Instruct models (0.5B–7B), we show that reward-improving perturbations remain empirically accessible with small populations across scales. Together, these results reconcile ES scalability with non-monotonic training dynamics and suggest that high-dimensional fine-tuning may admit a broader class of viable optimization methods than worst-case theory implies.
💡 Research Summary
The paper investigates two puzzling phenomena observed when fine‑tuning large language models (LLMs) with weight‑perturbation evolution strategies (ES): (1) ES can succeed with extremely small populations (as low as N≈30) even for models with billions of parameters, seemingly defying the classic “curse of dimensionality” that predicts the number of function evaluations must grow rapidly with dimensionality; and (2) under fixed hyper‑parameters, the training reward often follows a non‑monotonic “rise‑then‑decay” trajectory, first improving rapidly, reaching a peak, and then deteriorating. The authors propose a unified geometric explanation based on the curvature structure of the fine‑tuning reward landscape.
Core hypothesis – a “blessing of dimensionality.”
Empirical studies of over‑parameterized networks consistently show that the Hessian spectrum consists of a bulk of near‑zero eigenvalues and a small set of outliers with large magnitude. The authors argue that fine‑tuning LLMs inherits this property: only a low‑dimensional subspace (denoted d) of the full parameter space (dimension D) is curvature‑active, i.e., has significant second‑order curvature. Crucially, d does not scale with D and may even shrink as model size grows. Consequently, random Gaussian perturbations used by ES have a high probability of containing a component along one of these stiff directions, even when the population is tiny. The paper formalizes this intuition by deriving a probability that at least one perturbation yields improvement: (P_{\text{improve}} \approx 1-(1-c/d)^N), where c captures the average improvement probability per stiff direction. When d is small, the term remains close to one for modest N, explaining why N≈30 suffices across models ranging from 0.5 B to 7 B parameters.
ES as a geometric probe.
ES evaluates the smoothed objective (J_{\sigma}(\theta)=\mathbb{E}_{\epsilon}
Comments & Academic Discussion
Loading comments...
Leave a Comment