MonoScale: Scaling Multi-Agent System with Monotonic Improvement
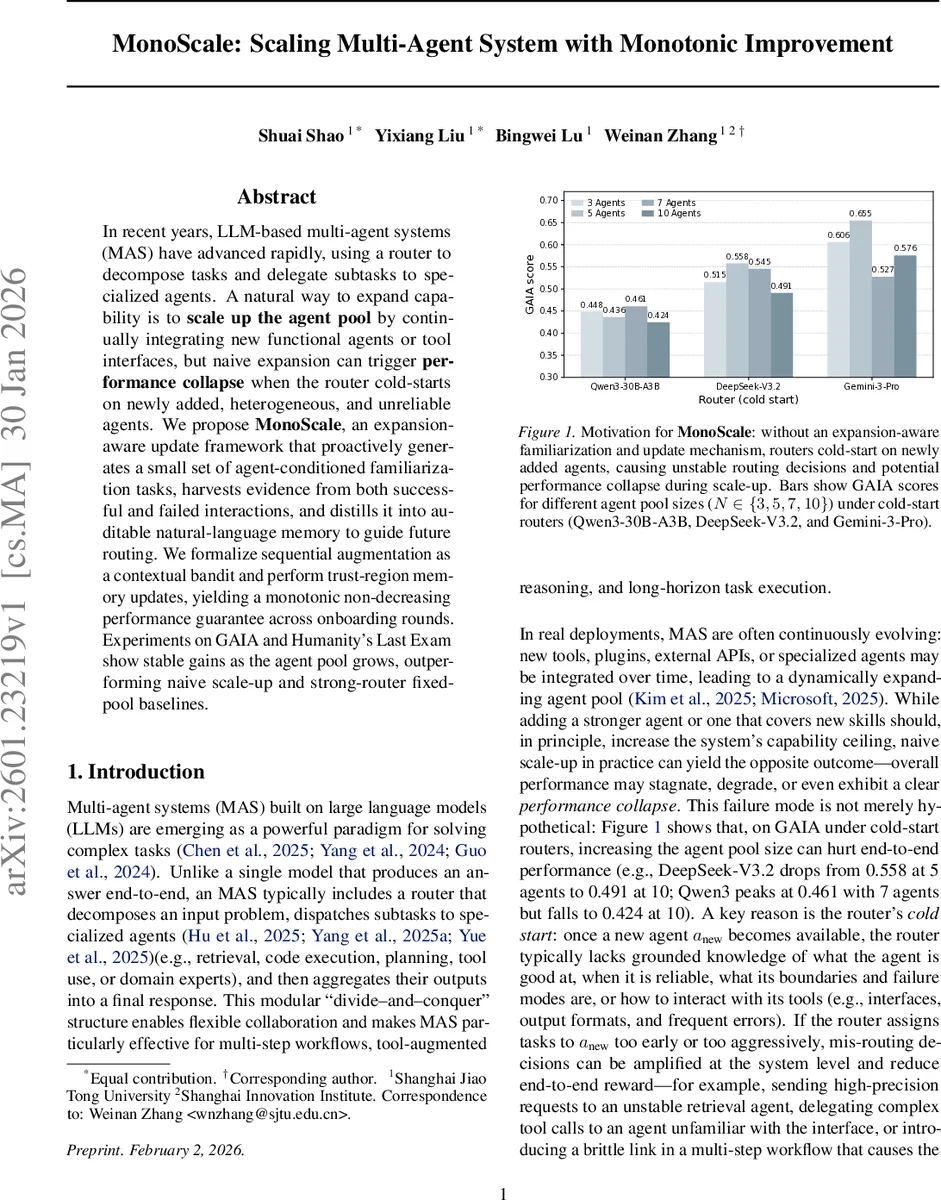
In recent years, LLM-based multi-agent systems (MAS) have advanced rapidly, using a router to decompose tasks and delegate subtasks to specialized agents. A natural way to expand capability is to scale up the agent pool by continually integrating new functional agents or tool interfaces, but naive expansion can trigger performance collapse when the router cold-starts on newly added, heterogeneous, and unreliable agents. We propose MonoScale, an expansion-aware update framework that proactively generates a small set of agent-conditioned familiarization tasks, harvests evidence from both successful and failed interactions, and distills it into auditable natural-language memory to guide future routing. We formalize sequential augmentation as a contextual bandit and perform trust-region memory updates, yielding a monotonic non-decreasing performance guarantee across onboarding rounds. Experiments on GAIA and Humanity’s Last Exam show stable gains as the agent pool grows, outperforming naive scale-up and strong-router fixed-pool baselines.
💡 Research Summary
MonoScale tackles a critical bottleneck in large‑language‑model (LLM) based multi‑agent systems (MAS): when new agents, tools, or plugins are added, the central router typically suffers a “cold‑start” problem, leading to mis‑routing and overall performance collapse. Existing work either assumes a static set of agents or focuses on improving routing within a fixed pool, leaving open‑ended scaling largely unaddressed.
The authors formalize the scaling process as a sequential contextual bandit. At expansion stage k the system possesses an agent pool Sₖ, inducing an action space Yₖ of feasible orchestration plans. The router is a frozen LLM whose behavior is modulated by an editable text memory m (subject to a token budget). The policy πₖᵐ(y|x) = p₍LLM₎(y|x,m;Sₖ) is therefore selected by choosing an appropriate memory state. When a new agent aₖ is introduced, the action space expands (Yₖ₋₁ ⊂ Yₖ) and naïve updates can degrade performance because the router lacks knowledge about aₖ’s capabilities and failure modes.
MonoScale introduces a two‑stage, expansion‑aware protocol. First, it synthesizes a small set of “familiarization tasks” conditioned on the new agent’s specification (the “agent card”). These tasks are deliberately crafted to probe both strengths (e.g., successful tool calls) and weaknesses (e.g., timeout, format errors). Second, the current router executes the tasks, and the system collects success and failure traces. The traces are distilled into natural‑language routing principles—compact textual statements such as “use the search agent only when the query length ≤ 5 tokens” or “if the code‑execution agent returns a non‑JSON payload, fallback to the interpreter”. These principles become candidate memory entries.
Memory updates are performed under a trust‑region constraint: the new memory‑induced policy πₖ must stay within a KL‑divergence ε of the “conservative lift” of the previous policy π↑ₖ₋₁ (which simply disables the new agent). This guarantees that the post‑expansion policy never performs worse than the pre‑expansion baseline, yielding the monotonic improvement guarantee Jₖ(πₖ) ≥ Jₖ₋₁(πₖ₋₁) for every expansion step. The authors prove this property mathematically, assuming non‑interfering expansions (i.e., plans that do not call the new agent retain identical outcomes).
Empirically, MonoScale is evaluated on two benchmarks: GAIA, a suite of complex multi‑step questions, and Humanity’s Last Exam, a multiple‑choice test. Starting from three agents, the pool is expanded to ten agents in increments of two. Baselines include (1) naïve scale‑up (adding agents without any adaptation), (2) strong fixed‑pool routers such as GPT‑5‑based orchestrators, and (3) state‑of‑the‑art static‑pool methods. Results show that naïve scale‑up suffers a clear performance drop (e.g., GAIA score from 0.558 with five agents down to 0.491 with ten), whereas MonoScale steadily improves (GAIA from 0.44 to 0.58) and even outperforms the strong‑router fixed‑pool baseline. In a noisy‑agent scenario where a fraction of agents are deliberately malfunctioning, the strongest baseline collapses, while MonoScale maintains stable performance, demonstrating robustness to heterogeneous and unreliable additions.
Key insights: (i) targeted familiarization tasks quickly surface an agent’s true operating envelope, providing the router with actionable evidence; (ii) natural‑language memory offers a lightweight, auditable, and rollback‑capable mechanism to adjust routing without fine‑tuning the underlying LLM; (iii) trust‑region updates enforce conservative policy evolution, mathematically preventing degradation during expansion.
Limitations include the fixed token budget for memory, which may constrain the number of principles that can be stored in very large pools, and the reliance on accurate agent cards for task synthesis. Future work could explore hierarchical memory compression, meta‑learning of task synthesis, and multi‑router architectures to further scale MAS while preserving the monotonic guarantee.
In summary, MonoScale provides the first principled, provably safe framework for dynamically scaling LLM‑based multi‑agent systems. By coupling agent‑conditioned warm‑up tasks with evidence‑driven natural‑language memory updates and trust‑region policy optimization, it ensures that adding new agents never harms—and typically improves—overall system performance. This work paves the way for truly open‑ended MAS deployments where capabilities can be continuously extended without sacrificing reliability.
Comments & Academic Discussion
Loading comments...
Leave a Comment