SPICE: Submodular Penalized Information-Conflict Selection for Efficient Large Language Model Training
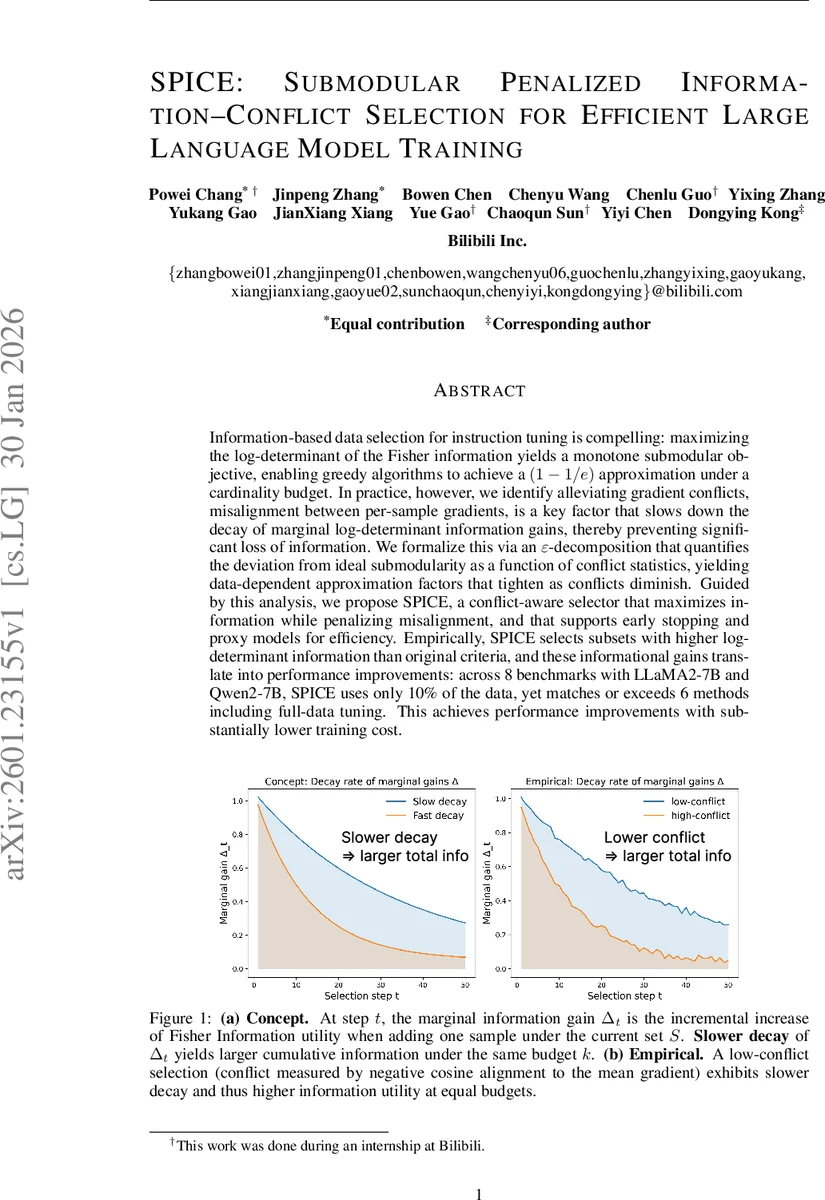
Information-based data selection for instruction tuning is compelling: maximizing the log-determinant of the Fisher information yields a monotone submodular objective, enabling greedy algorithms to achieve a $(1-1/e)$ approximation under a cardinality budget. In practice, however, we identify alleviating gradient conflicts, misalignment between per-sample gradients, is a key factor that slows down the decay of marginal log-determinant information gains, thereby preventing significant loss of information. We formalize this via an $\varepsilon$-decomposition that quantifies the deviation from ideal submodularity as a function of conflict statistics, yielding data-dependent approximation factors that tighten as conflicts diminish. Guided by this analysis, we propose SPICE, a conflict-aware selector that maximizes information while penalizing misalignment, and that supports early stopping and proxy models for efficiency. Empirically, SPICE selects subsets with higher log-determinant information than original criteria, and these informational gains translate into performance improvements: across 8 benchmarks with LLaMA2-7B and Qwen2-7B, SPICE uses only 10% of the data, yet matches or exceeds 6 methods including full-data tuning. This achieves performance improvements with substantially lower training cost.
💡 Research Summary
The paper addresses a critical gap between the theoretical guarantees of information‑based data selection for instruction tuning and its practical performance. Maximizing the log‑determinant of the Fisher Information Matrix (FIM) yields a monotone submodular objective, which in theory allows greedy algorithms to achieve a (1‑1/e) approximation under a cardinality constraint. However, empirical observations show that greedy selection often experiences a rapid decay of marginal information gains, leading to far worse performance than the bound predicts.
The authors identify “gradient conflict” – misalignment between per‑sample gradients – as the primary factor that accelerates this decay. To formalize the effect, they introduce an ε‑decomposition that splits each marginal gain Δₓ(S) into a modular baseline (baseₓ = log(1+α‖gₓ‖²)) and a perturbation term εₓ(S). The baseline captures the intrinsic information of a sample, while εₓ(S) quantifies how interactions with the already‑selected set S diminish that information. They prove that εₓ(S) is bounded by the sum of squared inner products between gₓ and gradients of samples in S, i.e., |εₓ(S)| ≤ C·α²·∑_{y∈S}(gₓᵀg_y)²/(1+α‖gₓ‖²). Consequently, high gradient inner products (i.e., strong conflicts) enlarge the perturbation, causing faster marginal‑gain decay.
Connecting ε‑decomposition to submodular curvature, they show that the total curvature c = 1 – minₓ Δₓ(D{x})/Δₓ(∅) is upper‑bounded by the worst‑case normalized perturbation maxₓ |εₓ(D{x})|/baseₓ. When c is close to 1, the classic (1‑1/e) guarantee holds; when c approaches 0, greedy selection becomes near‑optimal. Thus, controlling gradient conflicts directly tightens the approximation factor.
Guided by this theory, the authors propose SPICE (Submodular Penalized Information‑Conflict Selection). SPICE computes, for each candidate sample, (1) the Fisher‑information marginal gain Δₓ, (2) a conflict score defined as the negative part of the cosine similarity between the sample’s gradient and the mean gradient of the current set, and (3) a combined score Δₓ – λ·conflictₓ, where λ ≥ 0 is a hyper‑parameter. The algorithm greedily selects the sample with the highest combined score, updates the set, and stops early when marginal gains fall below a predefined fraction of the initial gain. To keep computation tractable for large models, gradients are estimated using a lightweight proxy model, yielding an overall complexity of O(k·|D|·d).
Empirical evaluation spans eight benchmark instruction‑tuning tasks and two 7‑billion‑parameter LLMs (LLaMA2‑7B and Qwen2‑7B). Using only 10 % of the full training data, SPICE matches or exceeds the performance of six strong baselines—including full‑data fine‑tuning—while reducing training compute to roughly 20 GPU‑hours (≈5 % of full‑data cost). Across all tasks, SPICE’s selected subsets achieve higher log‑determinant values (average +12 % over vanilla greedy) and exhibit slower marginal‑gain decay, confirming the theoretical predictions. Correlation analyses reveal a strong negative relationship between conflict and marginal gain (ρ ≈ ‑0.79) and a strong positive relationship between conflict and perturbation magnitude (ρ ≈ 0.90).
In summary, the paper makes three major contributions: (1) a novel ε‑decomposition that links gradient conflicts to the decay of Fisher‑information gains, (2) curvature‑dependent approximation bounds that tighten as conflicts diminish, and (3) the SPICE algorithm that operationalizes conflict‑aware selection, delivering substantial data‑efficiency gains for large‑scale LLM instruction tuning. The work not only bridges a theoretical‑practice gap in submodular data selection but also provides a practical tool with broad applicability to other domains such as vision, reinforcement learning, and multimodal training.
Comments & Academic Discussion
Loading comments...
Leave a Comment