Causal Characterization of Measurement and Mechanistic Anomalies
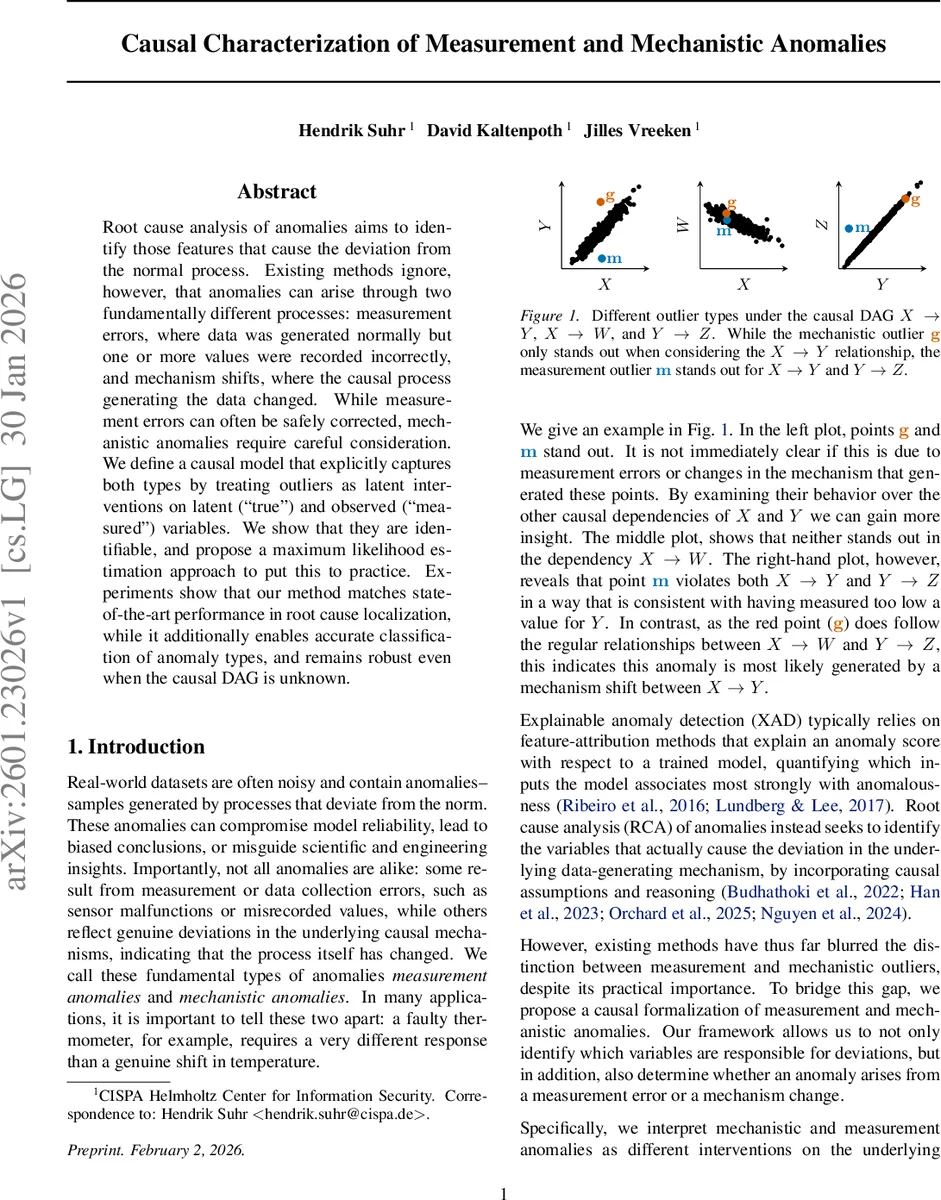
Root cause analysis of anomalies aims to identify those features that cause the deviation from the normal process. Existing methods ignore, however, that anomalies can arise through two fundamentally different processes: measurement errors, where data was generated normally but one or more values were recorded incorrectly, and mechanism shifts, where the causal process generating the data changed. While measurement errors can often be safely corrected, mechanistic anomalies require careful consideration. We define a causal model that explicitly captures both types by treating outliers as latent interventions on latent (“true”) and observed (“measured”) variables. We show that they are identifiable, and propose a maximum likelihood estimation approach to put this to practice. Experiments show that our method matches state-of-the-art performance in root cause localization, while it additionally enables accurate classification of anomaly types, and remains robust even when the causal DAG is unknown.
💡 Research Summary
The paper addresses a critical gap in anomaly detection and root‑cause analysis (RCA): the conflation of measurement errors with genuine shifts in the underlying causal mechanisms. The authors propose a causal framework that explicitly distinguishes these two anomaly types by modeling outliers as hard interventions on latent (“true”) variables and on observed (“measured”) variables. In the clean setting, a structural causal model (SCM) defines latent variables (X^{}) generated by functions (f_j) of their latent parents and independent noise, with each observed variable (X_j) being a faithful read‑out of its counterpart (X^{}_j).
Two kinds of anomalies are introduced: (i) mechanistic anomalies, where the structural assignment for a latent variable is replaced by an outlier distribution with probability (\pi^{\text{mech}}_j); (ii) measurement anomalies, where the observation itself is replaced by an outlier distribution with probability (\pi^{\text{meas}}_j). Both are modeled as independent Bernoulli variables (Z_j) and (W_j), respectively, and are treated as hard interventions that either cut incoming edges to a latent node (mechanistic) or replace the observed node (measurement). This distinction yields different downstream propagation: mechanistic interventions affect all descendants, whereas measurement interventions affect only the corrupted variable because observed nodes have no children in the latent sub‑graph.
Theoretical contributions include a proof of structural identifiability in the infinite‑sample limit: any latent assignment that respects the conditional independence (CI) constraints implied by the data must be structurally equivalent (up to observational equivalence) to the true assignment. Observational equivalence is defined via identical CI constraints on the observed variables; sink nodes illustrate cases where latent and observed interventions are indistinguishable. The Sparse Mechanism Shift (SMS) hypothesis—assuming failures are rare and independent—provides a prior that favors assignments with fewer interventions, breaking ties among equivalent structures.
Because CI testing is infeasible with finite data (especially when anomalies are rare), the authors adopt a maximum‑likelihood estimation (MLE) approach. They first learn a clean conditional density (\hat p(x_j\mid pa_j)) from non‑anomalous samples. For each data point, they evaluate the likelihood under every possible combination of (Z) and (W). Measurement anomalies require marginalizing over the unobserved true value; this integral is approximated via Monte‑Carlo sampling. The overall likelihood for a point is the product of (i) mechanistic outlier densities for variables with (Z_j=1), (ii) measurement outlier densities for variables with (W_j=1), and (iii) the clean conditional densities for the remaining variables. By assigning each point to the combination that maximizes this likelihood, the method implicitly respects the structural constraints of the identifiability theorem while also detecting distributional shifts that do not alter the CI structure (e.g., a root‑node mechanistic shift).
Empirical evaluation comprises synthetic DAGs and real‑world sensor/industrial datasets. Metrics assess (a) root‑cause localization accuracy, (b) anomaly‑type classification (measurement vs mechanistic), and (c) robustness when the causal DAG is unknown. The proposed method matches or exceeds state‑of‑the‑art RCA techniques (e.g., Orchard et al., 2025) in localization, while achieving >95 % accuracy in distinguishing anomaly types—something prior methods cannot do. Moreover, even without explicit knowledge of the DAG, the algorithm remains robust, thanks to its reliance on learned conditional densities and the SMS prior.
In summary, the paper delivers a principled causal model that treats measurement errors and mechanism shifts as distinct interventions, proves that these interventions are identifiable from CI structure, and provides a practical MLE‑based algorithm for simultaneous detection, localization, and classification of anomalies. This contribution bridges a crucial gap for real‑world monitoring systems, offering a tool that can both correct erroneous measurements and flag genuine process changes, thereby supporting more reliable decision‑making in engineering, scientific, and operational contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment