Learning Geometrically-Grounded 3D Visual Representations for View-Generalizable Robotic Manipulation
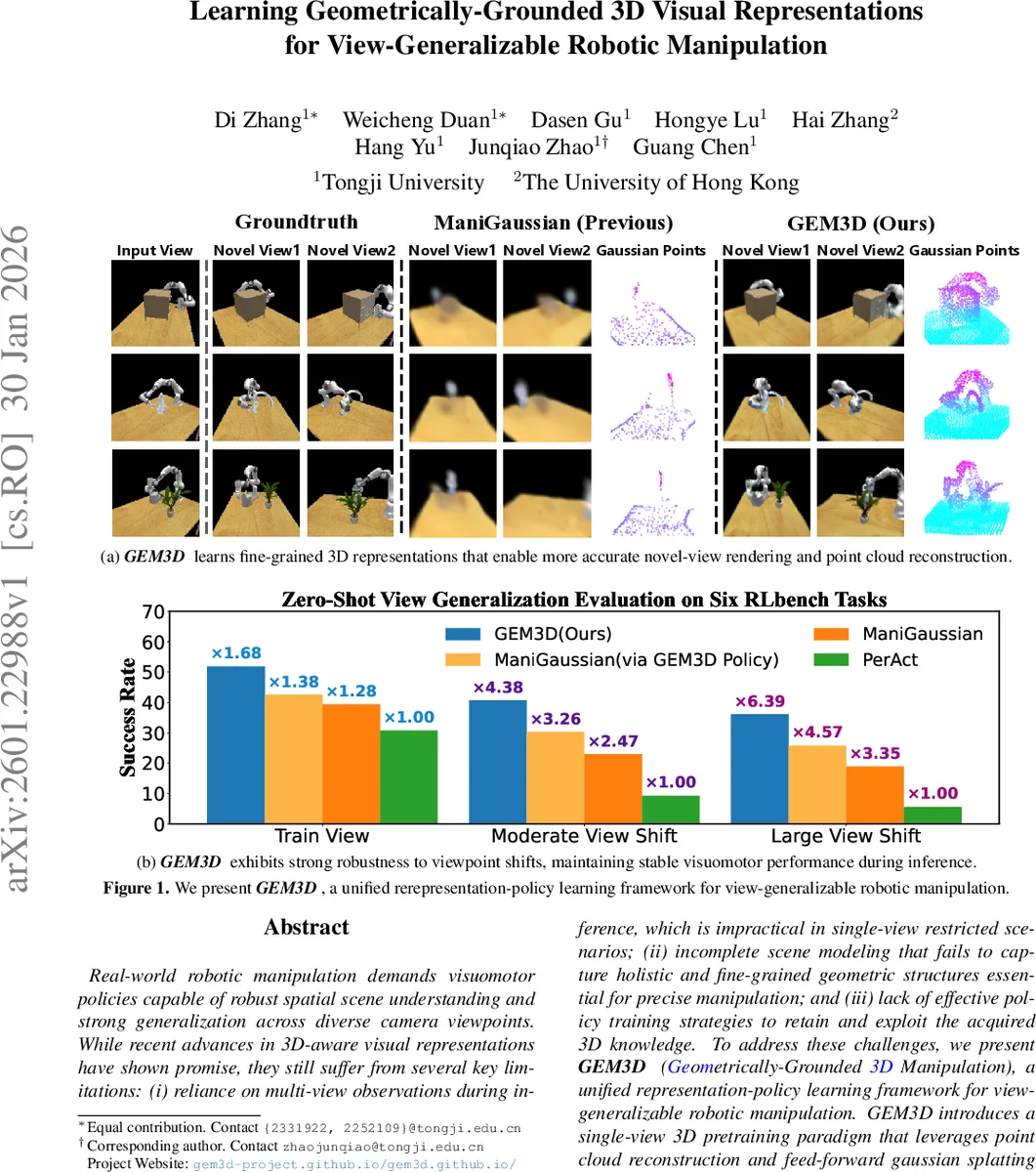
Real-world robotic manipulation demands visuomotor policies capable of robust spatial scene understanding and strong generalization across diverse camera viewpoints. While recent advances in 3D-aware visual representations have shown promise, they still suffer from several key limitations, including reliance on multi-view observations during inference which is impractical in single-view restricted scenarios, incomplete scene modeling that fails to capture holistic and fine-grained geometric structures essential for precise manipulation, and lack of effective policy training strategies to retain and exploit the acquired 3D knowledge. To address these challenges, we present MethodName, a unified representation-policy learning framework for view-generalizable robotic manipulation. MethodName introduces a single-view 3D pretraining paradigm that leverages point cloud reconstruction and feed-forward gaussian splatting under multi-view supervision to learn holistic geometric representations. During policy learning, MethodName performs multi-step distillation to preserve the pretrained geometric understanding and effectively transfer it to manipulation skills. We conduct experiments on 12 RLBench tasks, where our approach outperforms the previous state-of-the-art method by 12.7% in average success rate. Further evaluation on six representative tasks demonstrates strong zero-shot view generalization, with success rate drops of only 22.0% and 29.7% under moderate and large viewpoint shifts respectively, whereas the state-of-the-art method suffers larger decreases of 41.6% and 51.5%.
💡 Research Summary
The paper introduces GEM3D, a unified framework that learns geometrically‑grounded 3D visual representations from a single RGB‑D view and distills this knowledge into a view‑generalizable manipulation policy. The authors identify two major shortcomings of prior work: (1) dependence on multi‑view inputs or coarse scene reconstructions that lack the fine‑grained geometry required for precise manipulation, and (2) the loss of 3D knowledge when directly fine‑tuning a pretrained encoder for control. GEM3D addresses these by first pretraining a 3D encoder that converts a single‑view RGB‑D observation into a dense volumetric feature map. Depth is back‑projected to a point cloud, 2D features from a frozen DinoV2 are projected onto the points, and the resulting semantically enriched cloud is voxelized and processed by a 3D U‑Net. A learnable set of voxel queries undergoes coarse‑to‑fine cross‑attention (low‑resolution pooling followed by 3D deformable attention) to generate sparse seed points. These seeds are refined through a Snowflake‑style point deconvolution (SPD) that iteratively upsamples points by querying the volumetric feature via trilinear interpolation, producing a dense point cloud supervised by Chamfer loss against multi‑view ground‑truth clouds. The refined points serve as Gaussian centers; Gaussian attributes (color, opacity, rotation, scale) are regressed from interpolated volumetric features using a ResNetFC head. A differentiable renderer synthesizes novel‑view images, which are supervised with a focal loss against actual multi‑view RGB images, encouraging accurate texture reconstruction. This pretraining pipeline learns to infer complete geometry and appearance from a single view, yielding representations that are robust to large viewpoint changes.
For policy learning, GEM3D freezes the pretrained 3D feature extractor and introduces a separate visual encoder for the manipulation policy. The policy encoder processes the same RGB‑D input into latent tokens, while the frozen extractor provides reference tokens derived from the dense volumetric feature. A cosine‑similarity distillation loss aligns the policy tokens with the reference tokens at the current and next time steps, enforcing that the policy’s latent space retains the geometric information. An implicit latent dynamics model predicts the next latent state from the current state, proprioceptive signals, and language embeddings, enabling multi‑step distillation and improving temporal consistency. The overall loss combines imitation‑learning action regression with the distillation term.
Experiments on 12 RLBench tasks demonstrate that GEM3D achieves a 12.7 % absolute increase in average success rate over the previous state‑of‑the‑art ManiGaussian method. Zero‑shot view‑generalization tests with moderate (±30°) and large (±60°) camera shifts show success‑rate drops of only 22.0 % and 29.7 % respectively, compared to 41.6 % and 51.5 % for the baseline. Ablation studies confirm the importance of each component: volumetric feature extraction, Snowflake point reconstruction, feed‑forward Gaussian splatting, and especially the multi‑step distillation. The distillation‑based policy also improves performance when combined with other pretrained backbones, indicating broad applicability.
In summary, GEM3D provides a practical solution for real‑world robotic manipulation where only a single camera view is available. By learning high‑fidelity 3D scene embeddings and carefully transferring them to control policies through multi‑step distillation, the framework delivers strong spatial reasoning and robust generalization across unseen viewpoints, advancing the state of the art in view‑generalizable robotic manipulation.
Comments & Academic Discussion
Loading comments...
Leave a Comment