Matterhorn: Efficient Analog Sparse Spiking Transformer Architecture with Masked Time-To-First-Spike Encoding
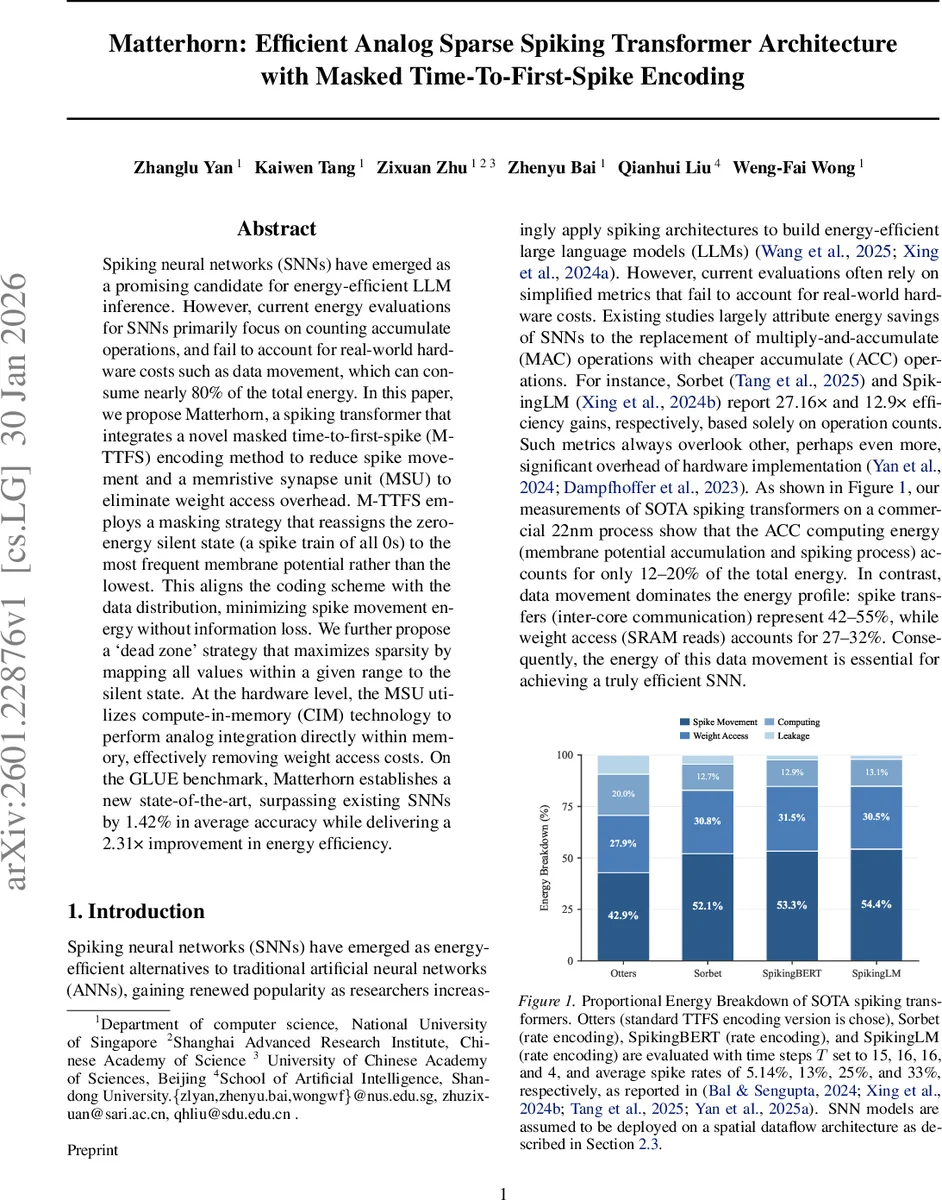
Spiking neural networks (SNNs) have emerged as a promising candidate for energy-efficient LLM inference. However, current energy evaluations for SNNs primarily focus on counting accumulate operations, and fail to account for real-world hardware costs such as data movement, which can consume nearly 80% of the total energy. In this paper, we propose Matterhorn, a spiking transformer that integrates a novel masked time-to-first-spike (M-TTFS) encoding method to reduce spike movement and a memristive synapse unit (MSU) to eliminate weight access overhead. M-TTFS employs a masking strategy that reassigns the zero-energy silent state (a spike train of all 0s) to the most frequent membrane potential rather than the lowest. This aligns the coding scheme with the data distribution, minimizing spike movement energy without information loss. We further propose a `dead zone’ strategy that maximizes sparsity by mapping all values within a given range to the silent state. At the hardware level, the MSU utilizes compute-in-memory (CIM) technology to perform analog integration directly within memory, effectively removing weight access costs. On the GLUE benchmark, Matterhorn establishes a new state-of-the-art, surpassing existing SNNs by 1.42% in average accuracy while delivering a 2.31 times improvement in energy efficiency.
💡 Research Summary
Matterhorn addresses the often‑overlooked energy bottlenecks of spiking neural network (SNN) transformers by jointly redesigning the encoding scheme and the compute substrate. The authors first quantify that, on a commercial 22 nm process, data movement dominates energy consumption: spike transfers account for 42–55 % and weight SRAM reads for 27–32 %, while the actual accumulate operations consume only 12–20 %. This motivates a two‑pronged solution.
The algorithmic contribution is Masked Time‑to‑First‑Spike (M‑TTFS) encoding. Conventional TTFS maps the all‑zero spike train (the silent state) to the smallest membrane potential, which is rarely observed in transformer activations. M‑TTFS instead identifies the most frequent firing time I_max and masks spikes at that time, reassigning the silent state to the most common activation values. A “dead zone” of radius k further expands this masking around I_max, allowing the model to suppress all spikes whose firing times fall within
Comments & Academic Discussion
Loading comments...
Leave a Comment