Float8@2bits: Entropy Coding Enables Data-Free Model Compression
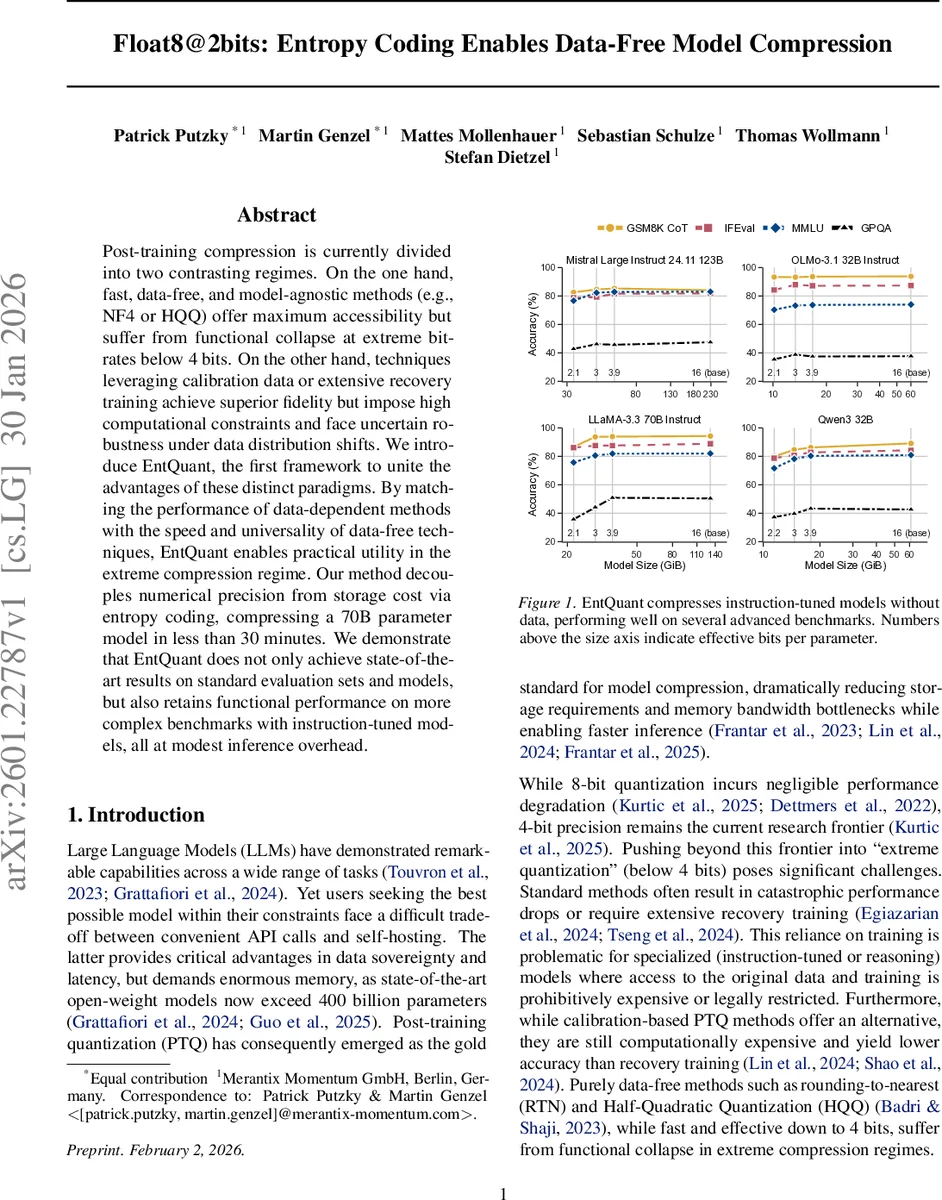
Post-training compression is currently divided into two contrasting regimes. On the one hand, fast, data-free, and model-agnostic methods (e.g., NF4 or HQQ) offer maximum accessibility but suffer from functional collapse at extreme bit-rates below 4 bits. On the other hand, techniques leveraging calibration data or extensive recovery training achieve superior fidelity but impose high computational constraints and face uncertain robustness under data distribution shifts. We introduce EntQuant, the first framework to unite the advantages of these distinct paradigms. By matching the performance of data-dependent methods with the speed and universality of data-free techniques, EntQuant enables practical utility in the extreme compression regime. Our method decouples numerical precision from storage cost via entropy coding, compressing a 70B parameter model in less than 30 minutes. We demonstrate that EntQuant does not only achieve state-of-the-art results on standard evaluation sets and models, but also retains functional performance on more complex benchmarks with instruction-tuned models, all at modest inference overhead.
💡 Research Summary
The paper addresses a fundamental bottleneck in post‑training quantization (PTQ) for large language models: the tight coupling between compression rate and numeric precision. Traditional PTQ methods either rely on data‑free, model‑agnostic quantizers such as NF4 or HQQ, which are fast but collapse when the effective bit‑width drops below four bits, or they depend on calibration data and extensive recovery training, which achieve higher fidelity at the cost of significant compute and potential fragility under distribution shift. The authors propose EntQuant, a novel framework that unifies the strengths of both paradigms by decoupling storage cost from the underlying numeric format through entropy coding.
EntQuant operates in two stages. First, it keeps the weights in an 8‑bit format (Float8 by default, with an optional Int8 variant) and optimizes channel‑wise scaling factors to minimize the entropy of the quantized weight matrix. Direct entropy minimization is non‑differentiable, so the authors replace the empirical entropy with a differentiable surrogate: the ℓ₁‑norm of the quantized weights. This proxy encourages frequent values to become small and sparse, effectively reducing the empirical distribution’s entropy. The optimization problem is formulated as a rate‑distortion trade‑off, min d(W, Ŵ)+λR(W_q), where d is a relative ℓ₁ reconstruction loss and R is the ℓ₁‑norm regularizer. Using L‑BFGS and a straight‑through estimator for quantization, each layer is optimized independently, requiring only a few seconds per layer even for a 70 B parameter model.
Second, the optimized 8‑bit weight tensor is flattened into a symbol stream and losslessly compressed with a GPU‑accelerated Asymmetric Numeral Systems (ANS) coder. ANS delivers arithmetic‑coding‑level compression efficiency while relying only on fast multiplication and bit‑shift operations, making it well‑suited for massive parallel execution on modern GPUs. The final stored representation consists of the compressed bitstream, the tiny set of channel scaling factors, and minimal ANS metadata. Because the scaling factors are negligible in size, the effective compression ratio is dictated almost entirely by the reduced entropy of the quantized weights.
During inference, the model does not load raw weights into memory. Instead, the compressed bitstream remains in VRAM and is decoded on‑the‑fly by a parallel ANS decoder before each matrix multiplication. This introduces a modest compute overhead but preserves the full dynamic range of the original 8‑bit format, allowing the model to retain expressive power that would be impossible under a rigid 2‑bit quantizer. Empirical results show that EntQuant can achieve effective bit‑rates as low as 2–3 bits per parameter while matching or surpassing the accuracy of data‑dependent PTQ methods on a suite of benchmarks (GSM8K, MMLU, GPQA) and across diverse instruction‑tuned models (LLaMA‑2, Mistral, Qwen3). Notably, the method remains completely data‑free, requiring only the weight tensors themselves.
Additional contributions include: (1) a clear demonstration that λ, the rate‑distortion weight, has a log‑linear relationship with the target entropy, simplifying hyper‑parameter selection; (2) the use of channel‑wise scaling as a lightweight outlier‑handling mechanism, avoiding complex grouping schemes; (3) a fully GPU‑native pipeline for both compression and inference, enabling compression of a 70 B model in under 30 minutes.
In summary, EntQuant delivers a practical solution for extreme model compression: it retains the speed and universality of data‑free quantizers, achieves the fidelity of data‑dependent approaches, and introduces a scalable entropy‑coding layer that makes sub‑4‑bit effective compression feasible without sacrificing model functionality. This work paves the way for more accessible self‑hosting of large foundation models, especially in environments with strict memory constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment