Unveiling Scaling Behaviors in Molecular Language Models: Effects of Model Size, Data, and Representation
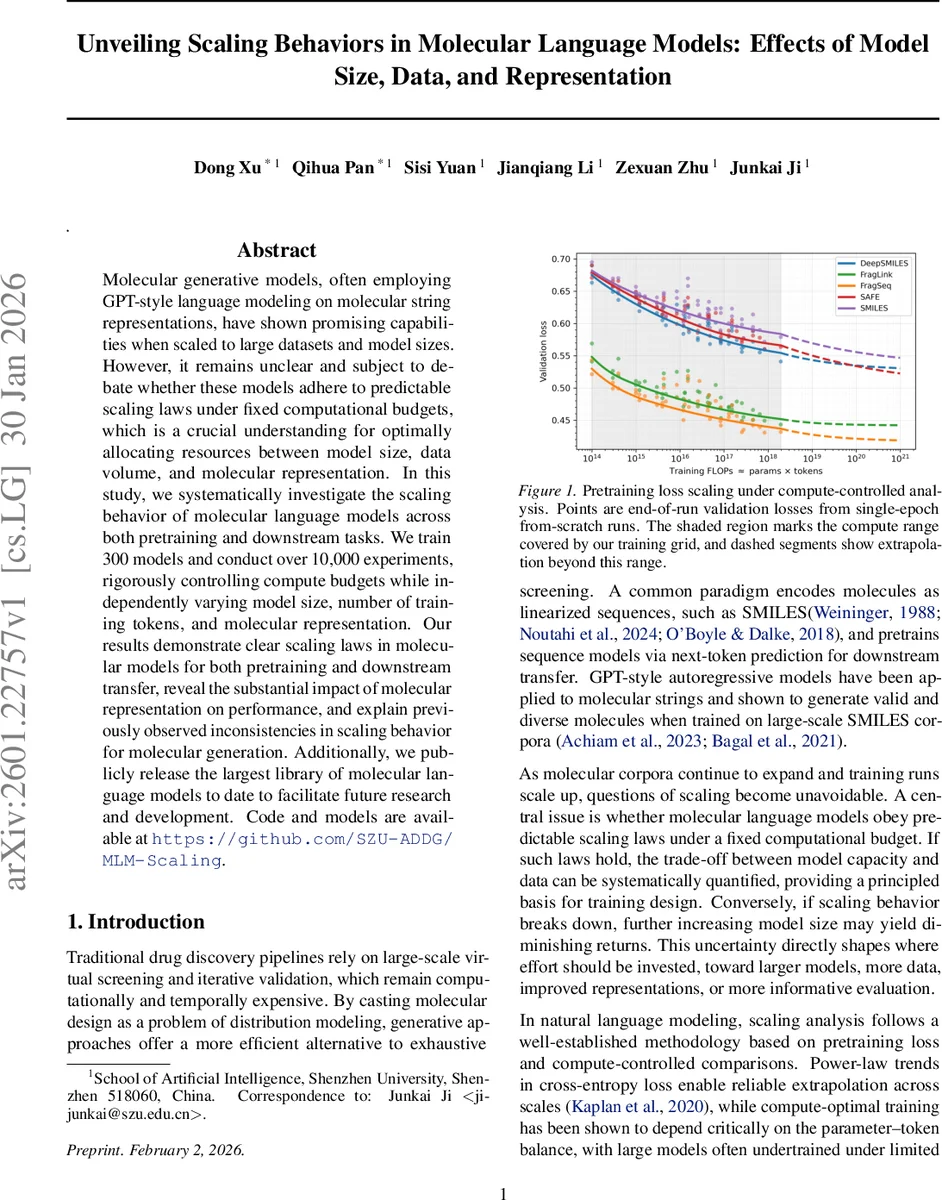
Molecular generative models, often employing GPT-style language modeling on molecular string representations, have shown promising capabilities when scaled to large datasets and model sizes. However, it remains unclear and subject to debate whether these models adhere to predictable scaling laws under fixed computational budgets, which is a crucial understanding for optimally allocating resources between model size, data volume, and molecular representation. In this study, we systematically investigate the scaling behavior of molecular language models across both pretraining and downstream tasks. We train 300 models and conduct over 10,000 experiments, rigorously controlling compute budgets while independently varying model size, number of training tokens, and molecular representation. Our results demonstrate clear scaling laws in molecular models for both pretraining and downstream transfer, reveal the substantial impact of molecular representation on performance, and explain previously observed inconsistencies in scaling behavior for molecular generation. Additionally, we publicly release the largest library of molecular language models to date to facilitate future research and development. Code and models are available at https://github.com/SZU-ADDG/MLM-Scaling.
💡 Research Summary
This paper presents a comprehensive scaling study of GPT‑style autoregressive language models applied to molecular string representations. The authors train a total of 300 models across five distinct molecular encodings—SMILES, SAFE, DeepSMILES, FragSeq, and FragLink—varying model size from 1 M to 650 M parameters and dataset token counts from 100 M to 3 B tokens. Crucially, all experiments are conducted under fixed compute budgets, where the product of parameters (P) and effective training tokens (D) equals a prescribed FLOP budget (C). This compute‑controlled design enables a clean investigation of the trade‑off between model capacity and data volume.
The core contribution is the formulation and empirical validation of a bivariate power‑law scaling relation for pre‑training loss:
L(P,D) = L∞ + k_P·P^{‑α} + k_D·D^{‑β}.
Each representation receives its own fitted constants (L∞, k_P, k_D, α, β). Across all encodings, α and β are positive, confirming that both larger models and more data consistently reduce loss. However, the magnitude of the exponents differs markedly: SMILES and DeepSMILES exhibit larger α (model‑centric scaling) and smaller β (data‑centric scaling), whereas FragSeq and FragLink show the opposite pattern, indicating that for these representations data expansion is more beneficial.
By imposing the compute constraint C = P·D, the authors derive the compute‑optimal allocation that minimizes loss. Closed‑form solutions give:
P_opt(C) ∝ C^{β/(α+β)} and D_opt(C) ∝ C^{α/(α+β)}.
The resulting token‑per‑parameter ratio ρ_opt = D_opt/P_opt follows a simple power law ρ_opt ≈ a·C^{s}, where the exponent s varies by representation (e.g., s≈0.45 for SMILES, s≈0.30 for SAFE). This quantifies how the optimal balance shifts: representations with higher s favor data‑heavy training, while lower s favors larger models for the same compute budget.
Downstream transfer performance is evaluated on nine benchmark tasks (six classification, three regression) using lightweight LoRA adaptation. The authors adapt 400 checkpoints (selected across the four model sizes and four token budgets for each representation) to each task, yielding 3 600 fine‑tuning runs. Results show a strong correlation between pre‑training loss L(P,D) and downstream metrics (ROC‑AUC for classification, RMSE for regression). The best trade‑off is observed for a 43 M‑parameter model trained on 300 M tokens, aligning precisely with the compute‑optimal frontier predicted by the scaling law.
A notable controversy in the field concerns the apparent lack of scaling in de‑novo molecular generation. The paper demonstrates that conventional generation metrics—validity, uniqueness, novelty, diversity—do not capture the continuous improvement in the underlying language model’s loss. While loss keeps decreasing with scale, generation diversity saturates at different points depending on the representation, explaining why prior work reported inconsistent scaling.
Finally, the authors release the entire library of 300 pretrained models, tokenizers, and training scripts on GitHub, providing the community with a reproducible benchmark for future scaling investigations.
In summary, this work establishes that molecular language models obey clear, representation‑dependent scaling laws when compute is held constant. It offers analytical formulas for optimal model‑data allocation, validates them empirically across pre‑training and downstream tasks, and clarifies why generation‑specific scaling may appear absent. The findings give practitioners concrete guidance on how to allocate resources—whether to invest in larger architectures, more data, or better molecular encodings—to achieve the best performance under a given computational budget.
Comments & Academic Discussion
Loading comments...
Leave a Comment