EntroCut: Entropy-Guided Adaptive Truncation for Efficient Chain-of-Thought Reasoning in Small-scale Large Reasoning Models
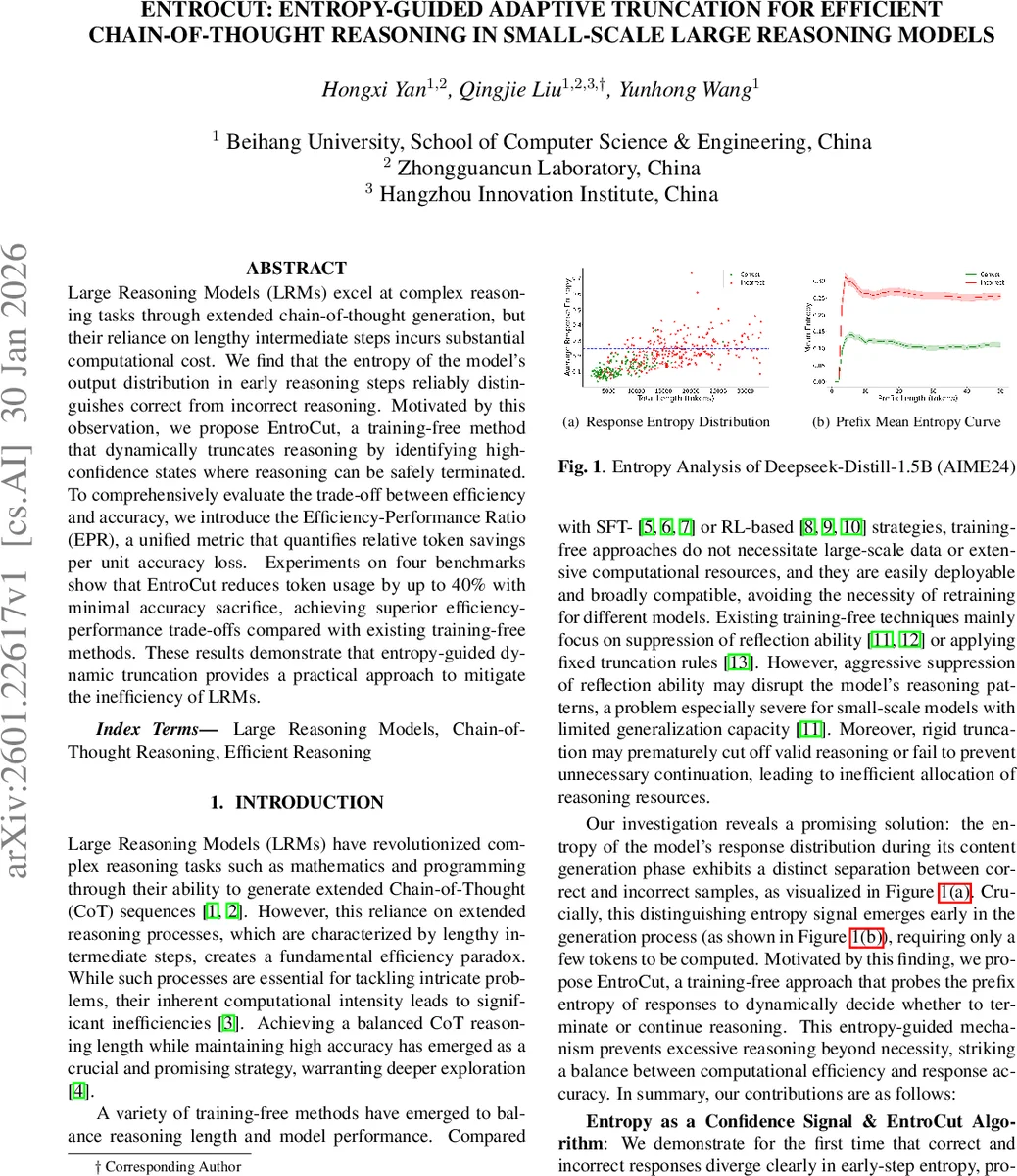
Large Reasoning Models (LRMs) excel at complex reasoning tasks through extended chain-of-thought generation, but their reliance on lengthy intermediate steps incurs substantial computational cost. We find that the entropy of the model’s output distribution in early reasoning steps reliably distinguishes correct from incorrect reasoning. Motivated by this observation, we propose EntroCut, a training-free method that dynamically truncates reasoning by identifying high-confidence states where reasoning can be safely terminated. To comprehensively evaluate the trade-off between efficiency and accuracy, we introduce the Efficiency-Performance Ratio (EPR), a unified metric that quantifies relative token savings per unit accuracy loss. Experiments on four benchmarks show that EntroCut reduces token usage by up to 40% with minimal accuracy sacrifice, achieving superior efficiency-performance trade-offs compared with existing training-free methods. These results demonstrate that entropy-guided dynamic truncation provides a practical approach to mitigate the inefficiency of LRMs.
💡 Research Summary
Large Reasoning Models (LRMs) have demonstrated impressive capabilities on complex tasks by generating long chain‑of‑thought (CoT) sequences. However, the extended reasoning steps dramatically increase token count and inference latency, creating a practical efficiency bottleneck. Existing training‑free approaches either suppress reflective tokens (NOWAIT) or apply fixed truncation budgets, but these static rules either cut off useful reasoning or waste computation on unnecessary steps, especially for smaller models with limited generalisation.
The authors observe that the entropy of a model’s output distribution during the early stages of reasoning serves as a reliable confidence signal: correct reasoning trajectories quickly produce low‑entropy token distributions, whereas incorrect or uncertain paths maintain higher entropy. This separation appears after only a few tokens, as visualised on DeepSeek‑Distill‑1.5B across several math benchmarks.
Motivated by this insight, they introduce EntroCut, a training‑free, entropy‑guided adaptive truncation method. The algorithm works as follows: (1) after the current reasoning token sequence, a special probe string (e.g., “\n\nSo the final answer is”) is appended; (2) the model generates k tokens following the probe, and the token‑level entropy H_i for each token is computed; (3) the average probe entropy (\bar H_{probe} = \frac{1}{k}\sum_i H_i) is compared against a pre‑defined threshold τ. If (\bar H_{probe} \le τ), the reasoning (think) phase is terminated, and the model proceeds directly to answer generation. The probe is only triggered when the model emits reflective markers such as “wait” or “but”, aligning the entropy check with natural pauses in the reasoning flow and avoiding per‑token overhead.
To quantify the trade‑off between computational savings and performance loss, the paper proposes the Efficiency‑Performance Ratio (EPR):
\
Comments & Academic Discussion
Loading comments...
Leave a Comment