Scalable Fair Influence Blocking Maximization via Approximately Monotonic Submodular Optimization
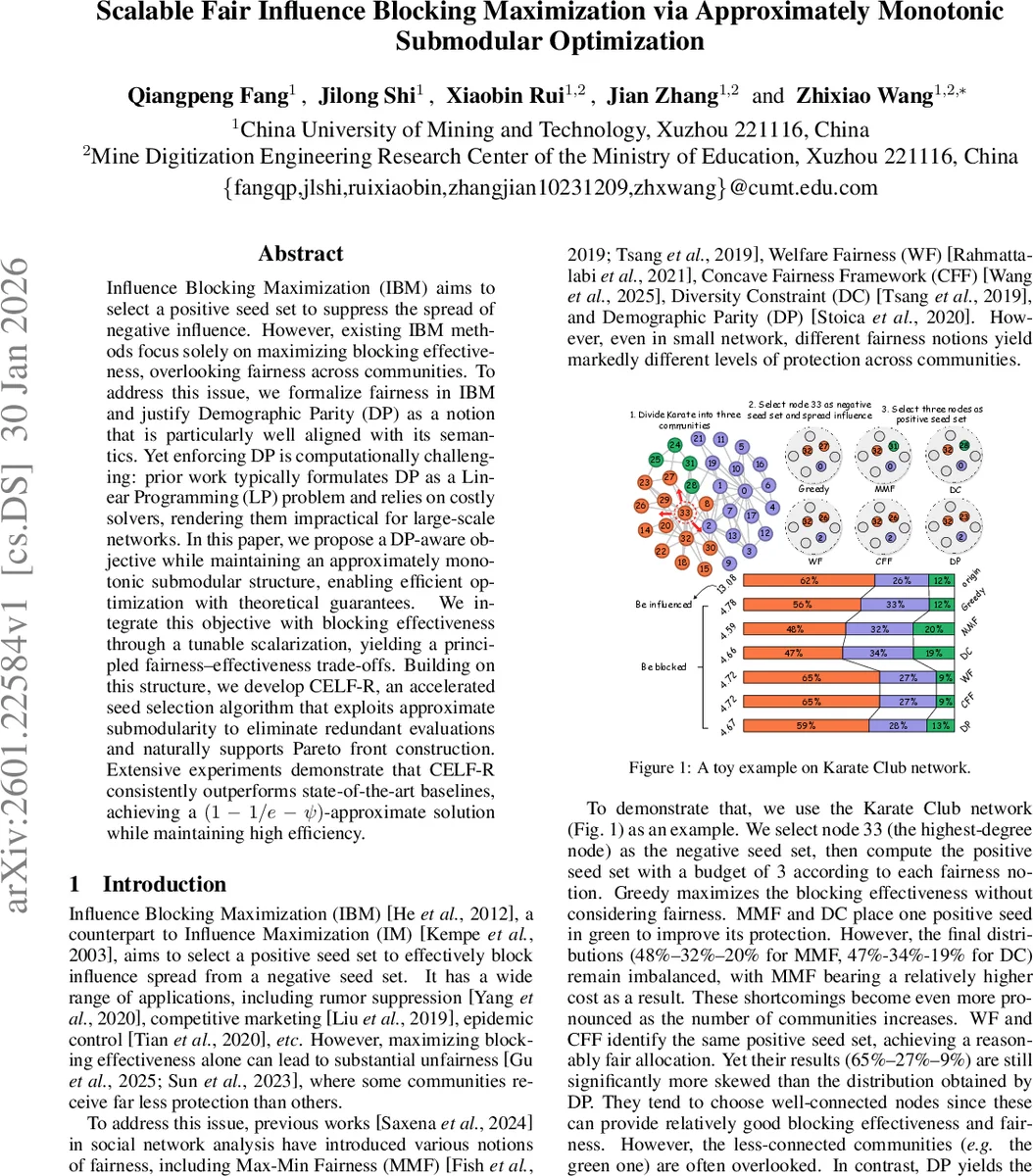
Influence Blocking Maximization (IBM) aims to select a positive seed set to suppress the spread of negative influence. However, existing IBM methods focus solely on maximizing blocking effectiveness, overlooking fairness across communities. To address this issue, we formalize fairness in IBM and justify Demographic Parity (DP) as a notion that is particularly well aligned with its semantics. Yet enforcing DP is computationally challenging: prior work typically formulates DP as a Linear Programming (LP) problem and relies on costly solvers, rendering them impractical for large-scale networks. In this paper, we propose a DP-aware objective while maintaining an approximately monotonic submodular structure, enabling efficient optimization with theoretical guarantees. We integrate this objective with blocking effectiveness through a tunable scalarization, yielding a principled fairness-effectiveness trade-offs. Building on this structure, we develop CELF-R, an accelerated seed selection algorithm that exploits approximate submodularity to eliminate redundant evaluations and naturally supports Pareto front construction. Extensive experiments demonstrate that CELF-R consistently outperforms state-of-the-art baselines, achieving a $(1-1/e-ψ)$-approximate solution while maintaining high efficiency.
💡 Research Summary
Influence Blocking Maximization (IBM) seeks a set of positive seed nodes that immunize a network against the spread of a given negative seed set. Existing IBM work optimizes only the total blocked influence, ignoring how protection is distributed among different communities. This paper introduces fairness into IBM by adopting Demographic Parity (DP) – the requirement that each community’s share of blocked influence matches its share of exposure to the negative seed set. DP is argued to be the most suitable fairness notion for IBM because it is structure‑agnostic, does not penalize sparsely connected or minority groups, and directly addresses the disparity that often arises in rumor‑containment or epidemic‑control scenarios.
Directly enforcing DP as a hard constraint leads to a linear‑programming (LP) formulation that does not scale beyond a few thousand nodes. To overcome this limitation, the authors design a DP‑aware objective that retains an approximately monotone submodular structure, enabling the use of greedy‑style optimization with provable guarantees. The DP surrogate is a concave function
(W(S_P)=\sum_{c\in\mathcal{C}} r_c\bigl(x_c(S_P)\bigr)^{\alpha}) (0 < α < 1), where (x_c) is the proportion of blocked influence in community c and (r_c=n_c^{1-\alpha}) with (n_c) the community’s exposure share. Maximizing W pushes the blocked proportions toward the target exposure shares; W equals 1 only when DP is satisfied exactly.
Blocking effectiveness is measured by the normalized blocked influence
(F(S_P)=\sigma^{-}(S_P)/\sigma(S_N)), a classic monotone submodular function. The two goals are combined linearly:
(K(S_P)=\beta,W(S_P)+(1-\beta),F(S_P)), where β∈
Comments & Academic Discussion
Loading comments...
Leave a Comment