ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
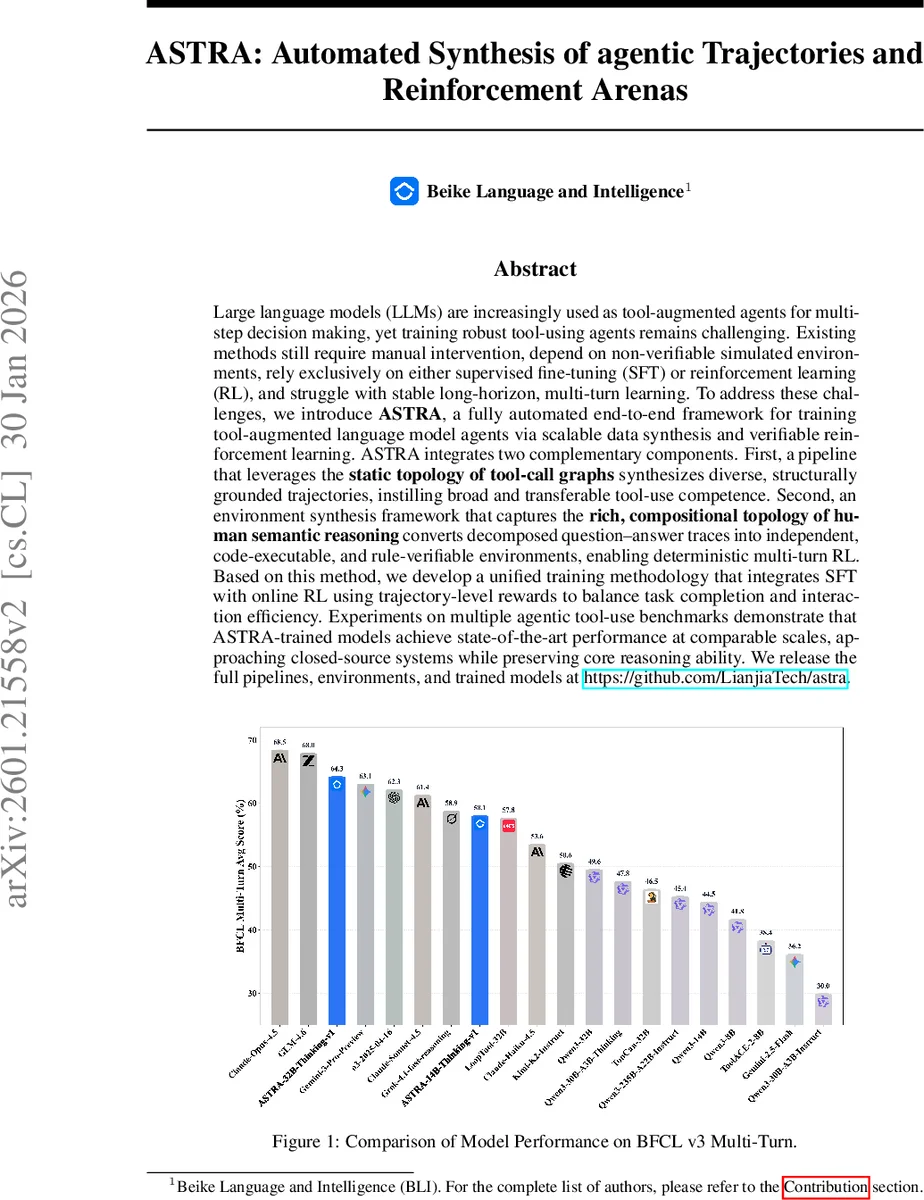
Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.
💡 Research Summary
The paper introduces ASTRA, a fully automated end‑to‑end framework for training tool‑augmented language‑model agents. ASTRA tackles three major bottlenecks in current tool‑using agents: (1) the scarcity and manual effort required to generate diverse multi‑turn tool‑use trajectories, (2) the lack of verifiable, deterministic environments for reinforcement learning, and (3) the instability of long‑horizon, multi‑turn online RL when environments are simulated by language models themselves.
The first component of ASTRA is a trajectory synthesis pipeline that exploits the static topology of tool‑call graphs. The authors first collect tool specifications from public MCP (Multi‑Component Platform) registries, API marketplaces, and internal documentation, then normalize all tools to a unified schema compatible with OpenAI’s tool‑calling protocol. For each MCP server, they construct a directed transition graph where nodes are tools and edges indicate that one tool can follow another in a valid sequence. By performing length‑bounded random walks on this graph (biased by observed frequencies), they generate candidate tool‑chains. Each chain is checked for dependency consistency (required arguments must be supplied by earlier tools) and task‑chain coherence (the associated user task must be plausible).
User tasks are then generated conditioned on either a validated tool‑chain (chain‑conditioned mode) or only on the server specification (server‑only mode) to ensure both executability and topical coverage. Tasks are further augmented along three axes—paraphrastic diversity, increased complexity, and persona conditioning—while preserving language consistency and semantic intent. A three‑dimensional scoring function evaluates question quality, scenario realism, and necessity of tool use; only tasks surpassing predefined thresholds are retained. The resulting tasks, together with the tool‑chains, are fed to a Qwen‑Agent that interacts with a hybrid tool pool (real MCP servers and emulated “doc‑only” tools). The emulator injects a 20 % failure probability to mimic real‑world unreliability.
For supervised fine‑tuning (SFT), ASTRA automatically scores each generated trajectory using seven trajectory‑level metrics: query understanding, planning, tool‑response context understanding, tool‑response context‑conditioned planning, tool‑call success rate, tool‑call conciseness, and final answer quality (semantic correlation plus faithful summarization). The arithmetic mean of these scores forms a scalar reward that guides SFT, producing an initial policy that is already adept at multi‑turn tool usage.
The second component is an environment synthesis framework that turns QA instances into executable, rule‑verifiable code environments. Human‑written question‑answer pairs are parsed to extract a semantic topology, which is then compiled into independent Python scripts together with a suite of deterministic tests. Because the environment’s state transitions and reward signals are fully specified, online reinforcement learning can be performed with stable, reproducible feedback.
Training proceeds in two stages: (i) SFT on the synthetic trajectories to obtain a strong base policy, and (ii) multi‑turn online RL across a diverse set of generated environments. The RL reward combines the same seven metrics, encouraging both task completion and interaction efficiency. An “irrelevant‑tool mixing” technique penalizes unnecessary tool calls, further promoting concise behavior.
Experiments on multiple benchmarks—including BFCL v3, ToolBench, and ReAct—show that ASTRA‑trained models achieve state‑of‑the‑art performance among models of comparable size, often surpassing them by 5–12 percentage points. The gains are especially pronounced on long‑horizon, multi‑turn tasks where prior methods struggled. Moreover, ASTRA models exhibit fewer redundant tool calls and higher overall efficiency, narrowing the gap to closed‑source commercial systems such as ChatGPT‑4.
All pipelines, synthesized tool documents, trajectories, environments, and trained checkpoints are released publicly on GitHub, ensuring reproducibility and enabling future research to extend the framework to new domains and toolsets. In summary, ASTRA provides a comprehensive solution that automates data generation, creates verifiable RL environments, and unifies supervised and reinforcement learning to produce robust, generalizable tool‑using agents.
Comments & Academic Discussion
Loading comments...
Leave a Comment