L$^3$: Large Lookup Layers
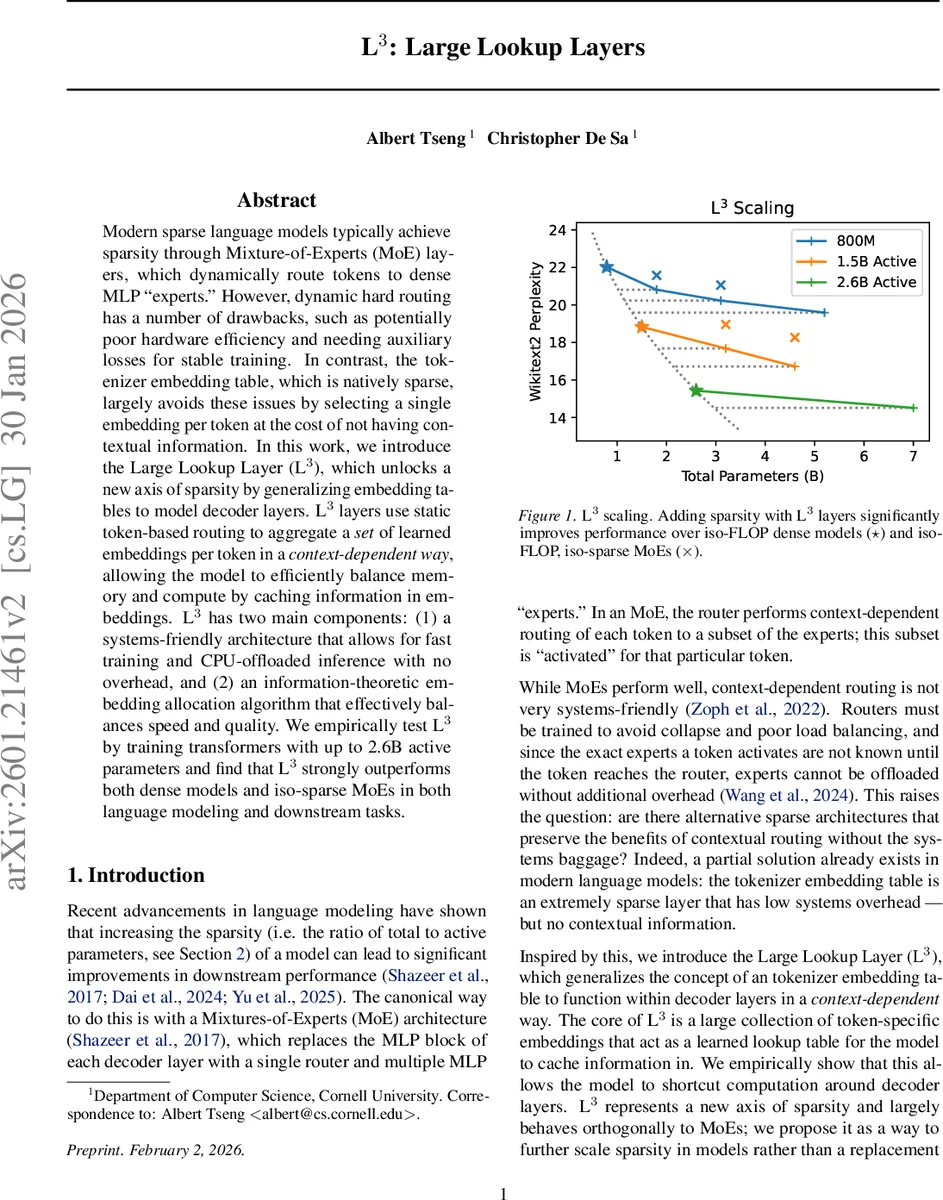
Modern sparse language models typically achieve sparsity through Mixture-of-Experts (MoE) layers, which dynamically route tokens to dense MLP “experts.” However, dynamic hard routing has a number of drawbacks, such as potentially poor hardware efficiency and needing auxiliary losses for stable training. In contrast, the tokenizer embedding table, which is natively sparse, largely avoids these issues by selecting a single embedding per token at the cost of not having contextual information. In this work, we introduce the Large Lookup Layer (L$^3$), which unlocks a new axis of sparsity by generalizing embedding tables to model decoder layers. L$^3$ layers use static token-based routing to aggregate a set of learned embeddings per token in a context-dependent way, allowing the model to efficiently balance memory and compute by caching information in embeddings. L$^3$ has two main components: (1) a systems-friendly architecture that allows for fast training and CPU-offloaded inference with no overhead, and (2) an information-theoretic embedding allocation algorithm that effectively balances speed and quality. We empirically test L$^3$ by training transformers with up to 2.6B active parameters and find that L$^3$ strongly outperforms both dense models and iso-sparse MoEs in both language modeling and downstream tasks.
💡 Research Summary
The paper introduces the Large Lookup Layer (L³), a novel sparsity mechanism for transformer‑based language models that replaces the dynamic routing of Mixture‑of‑Experts (MoE) with a static, token‑based lookup. In an L³ layer, each token identifier t is associated with a pre‑allocated set of key (Kₜ) and value (Vₜ) embedding matrices. When a token is processed, its current hidden state x is multiplied by Kₜ, passed through a softmax, and used to weight‑sum the corresponding rows of Vₜ. The resulting context‑dependent embedding is then combined with the residual hidden state via a layer‑norm and a mixing matrix, effectively performing channel mixing only.
The key innovations are twofold. First, because routing depends solely on the token ID, the exact subset of parameters needed for any token is known at generation time. This enables aggressive system‑level optimizations: during training, an entire batch can be sorted by token ID, turning the lookup into a block‑diagonal attention mask that can be processed with existing high‑performance attention kernels (e.g., MegaBlocks, FlexAttention). During inference, the required Kₜ and Vₜ slices can be off‑loaded to CPU memory and prefetched while earlier layers compute, eliminating the latency and memory‑bandwidth penalties that plague MoE routers.
Second, the paper proposes an information‑theoretic embedding allocation algorithm based on a variant of LZW compression. Given a total budget of v embeddings and a per‑token cap k, the algorithm scans a large corpus, builds a dictionary of frequent suffixes (codewords), and allocates embeddings to tokens proportionally to the frequency of codewords that end with that token. Frequently occurring tokens receive up to k embeddings, while rare tokens receive at least one. This allocation mimics the behavior of a context‑dependent router—high‑frequency tokens get richer representations—while remaining static. Empirically, LZW‑based allocation halves the perplexity gap compared with uniform allocation.
System‑wise, L³ parameters (K and V) are concatenated into two large matrices (W_K, W_V). Because only a small fraction of rows are active for any batch (≈100 M active parameters for a 2.6 B‑parameter model with a 2048‑token context), the memory footprint during training and inference is dramatically reduced. The static routing also simplifies model parallelism: L³ adds no extra communication beyond what dense MLPs require, making it compatible with existing tensor‑parallel and pipeline‑parallel frameworks.
Empirical evaluation trains L³‑augmented transformers up to 2.6 B active parameters on standard language modeling corpora. Compared against dense baselines and iso‑FLOP MoE models (same total FLOPs, same active parameter count), L³ consistently achieves lower validation perplexity (≈1.8–2.2× improvement) and higher scores on downstream benchmarks such as GLUE and SuperGLUE (average gains of 1.5–2.0 points). Notably, L³ attains these gains while using far fewer active parameters per token than MoE, and without the auxiliary router losses or load‑balancing tricks required for stable MoE training.
In summary, Large Lookup Layers provide a hardware‑friendly alternative to MoE: they retain the advantage of parameter sparsity—allocating many parameters overall but activating only a small, token‑specific subset—while eliminating dynamic routing overhead. By coupling static token routing with an LZW‑inspired embedding allocation, L³ achieves strong empirical performance, efficient GPU/CPU utilization, and straightforward integration into existing transformer pipelines. The work opens avenues for further research, including applying L³ to subword or byte‑level tokenizations, extending it to multimodal architectures, and exploring adaptive re‑allocation of embeddings during fine‑tuning.
Comments & Academic Discussion
Loading comments...
Leave a Comment