ECSEL: Explainable Classification via Signomial Equation Learning
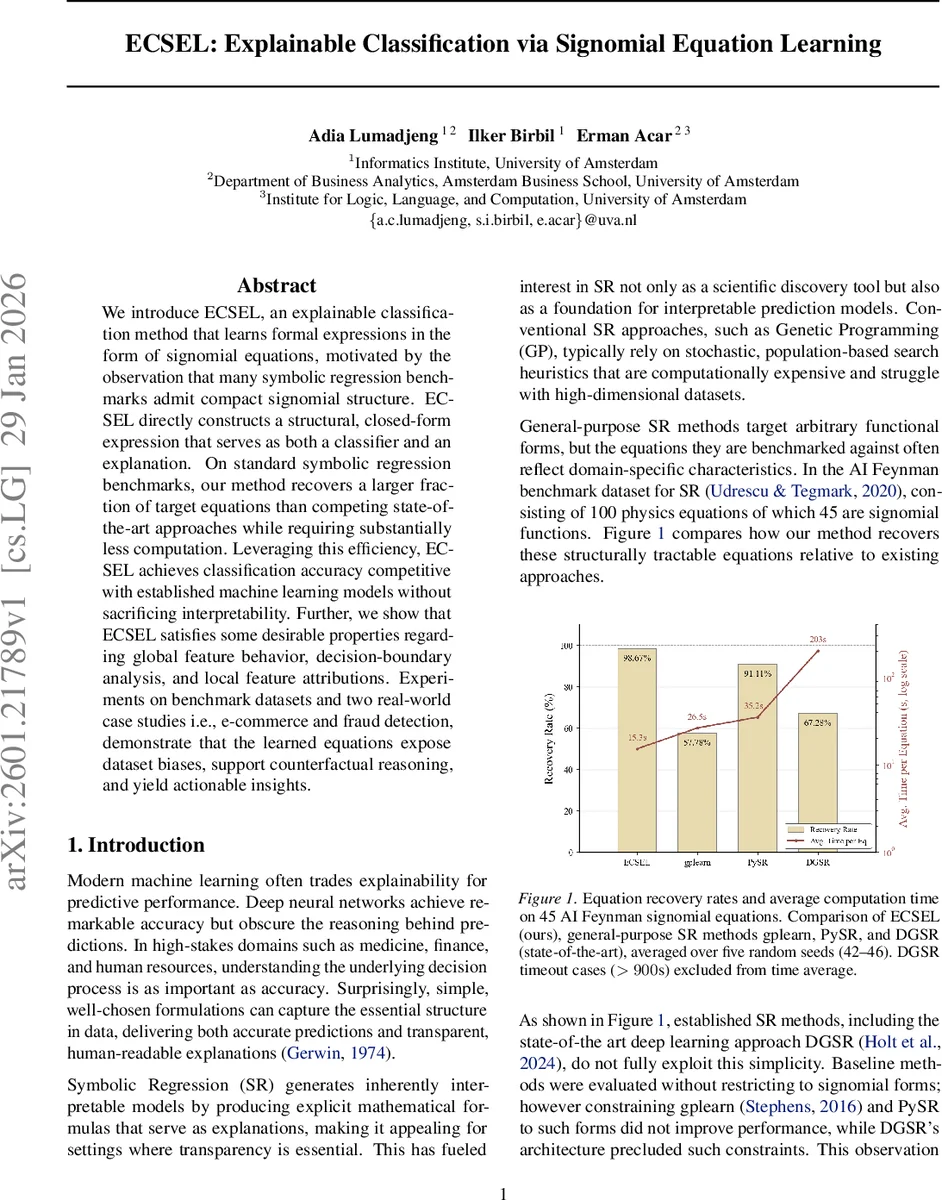
We introduce ECSEL, an explainable classification method that learns formal expressions in the form of signomial equations, motivated by the observation that many symbolic regression benchmarks admit compact signomial structure. ECSEL directly constructs a structural, closed-form expression that serves as both a classifier and an explanation. On standard symbolic regression benchmarks, our method recovers a larger fraction of target equations than competing state-of-the-art approaches while requiring substantially less computation. Leveraging this efficiency, ECSEL achieves classification accuracy competitive with established machine learning models without sacrificing interpretability. Further, we show that ECSEL satisfies some desirable properties regarding global feature behavior, decision-boundary analysis, and local feature attributions. Experiments on benchmark datasets and two real-world case studies i.e., e-commerce and fraud detection, demonstrate that the learned equations expose dataset biases, support counterfactual reasoning, and yield actionable insights.
💡 Research Summary
The paper introduces ECSEL (Explainable Classification via Signomial Equation Learning), a novel framework that unifies symbolic regression’s interpretability with modern classification performance. The authors observe that many benchmark equations, especially those in the AI Feynman dataset, are signomials—finite sums of power‑law terms. Rather than searching a huge expression space with stochastic evolutionary algorithms, ECSEL directly targets this structure by learning a separate signomial score function for each class.
A signomial with K terms is defined as
(z(x)=\sum_{k=1}^{K}\alpha_k\prod_{j=1}^{m}x_j^{\beta_{k,j}}),
where (\alpha_k) are coefficients and (\beta_{k,j}) are real exponents. The authors prove a universal approximation theorem: on any compact subset of the positive orthant, signomials are dense in the space of continuous functions, establishing them as a powerful yet parsimonious function class.
Training proceeds by minimizing cross‑entropy loss together with an (\ell_1) penalty on all exponents (\beta). This regularization drives many exponents toward zero, automatically performing feature selection and yielding sparse, human‑readable equations. Gradient‑based optimizers (e.g., Adam) are used; numerical stability is ensured by scaling inputs to a strictly positive range and performing calculations in log‑space.
The model’s functional form yields three analytically tractable interpretability layers:
-
Global feature behavior – Elasticities (E_{c,j}=∂\log z_c/∂\log x_j) and log‑gradients (G_{c,j}=∂z_c/∂\log x_j) have closed‑form expressions in terms of the learned (\beta)s and term responsibilities. For K=1, elasticity reduces to the constant exponent (\beta_{c,j}), giving an immediate sense of each feature’s proportional impact.
-
Decision‑boundary effects – The sensitivity of the margin (z_c−z_{c’}) to a proportional change in a feature is also closed‑form: (z_cE_{c,j}−z_{c’}E_{c’,j}). When K=1 this simplifies to (z_c\beta_{c,j}−z_{c’}\beta_{c’,j}), directly exposing how exponent differences drive class competition.
-
Local attributions – For small perturbations, the first‑order change in a class score is (\epsilon G_{c,j}). This provides exact, per‑sample feature contributions without recourse to surrogate models.
Empirically, ECSEL is evaluated on two fronts. On the 45 signomial equations of the AI Feynman benchmark, it recovers a larger fraction of the ground‑truth formulas than GP‑based tools (gplearn), PySR, and the state‑of‑the‑art deep symbolic regression method DGSR, while requiring orders of magnitude less computation (average runtimes of a few seconds versus minutes). On standard classification benchmarks (UCI, OpenML), ECSEL achieves accuracy, F1, and AUC scores comparable to logistic regression, random forests, and XGBoost, demonstrating that the interpretability does not come at a substantial predictive cost.
Two real‑world case studies illustrate practical value. In an e‑commerce purchase‑propensity dataset, the learned equations reveal that the exponent of “price” is positive for high‑value items, indicating a super‑linear increase in purchase probability, while “session length” has a negative exponent, suggesting diminishing returns. Counterfactual analysis (e.g., doubling price) can be performed analytically using the signomial scaling property. In a financial fraud detection dataset, the model uncovers that “transaction amount” and “inter‑transaction time” have negative exponents, whereas “country risk score” has a positive exponent, providing a transparent rule that aligns with domain expertise and can be embedded into rule‑based monitoring systems.
The authors discuss limitations: the need for strictly positive inputs, potential loss of expressivity when restricting to low K, and the current focus on multiplicative power‑law relationships. Future work includes automatic selection of K, hybridizing signomials with additive spline components, and extending the framework to handle categorical variables more naturally.
Overall, ECSEL demonstrates that by exploiting a prevalent structural pattern—signomials—one can build classifiers that are both computationally efficient and intrinsically explainable, bridging the gap between symbolic discovery and high‑performance predictive modeling.
Comments & Academic Discussion
Loading comments...
Leave a Comment