Error Amplification Limits ANN-to-SNN Conversion in Continuous Control
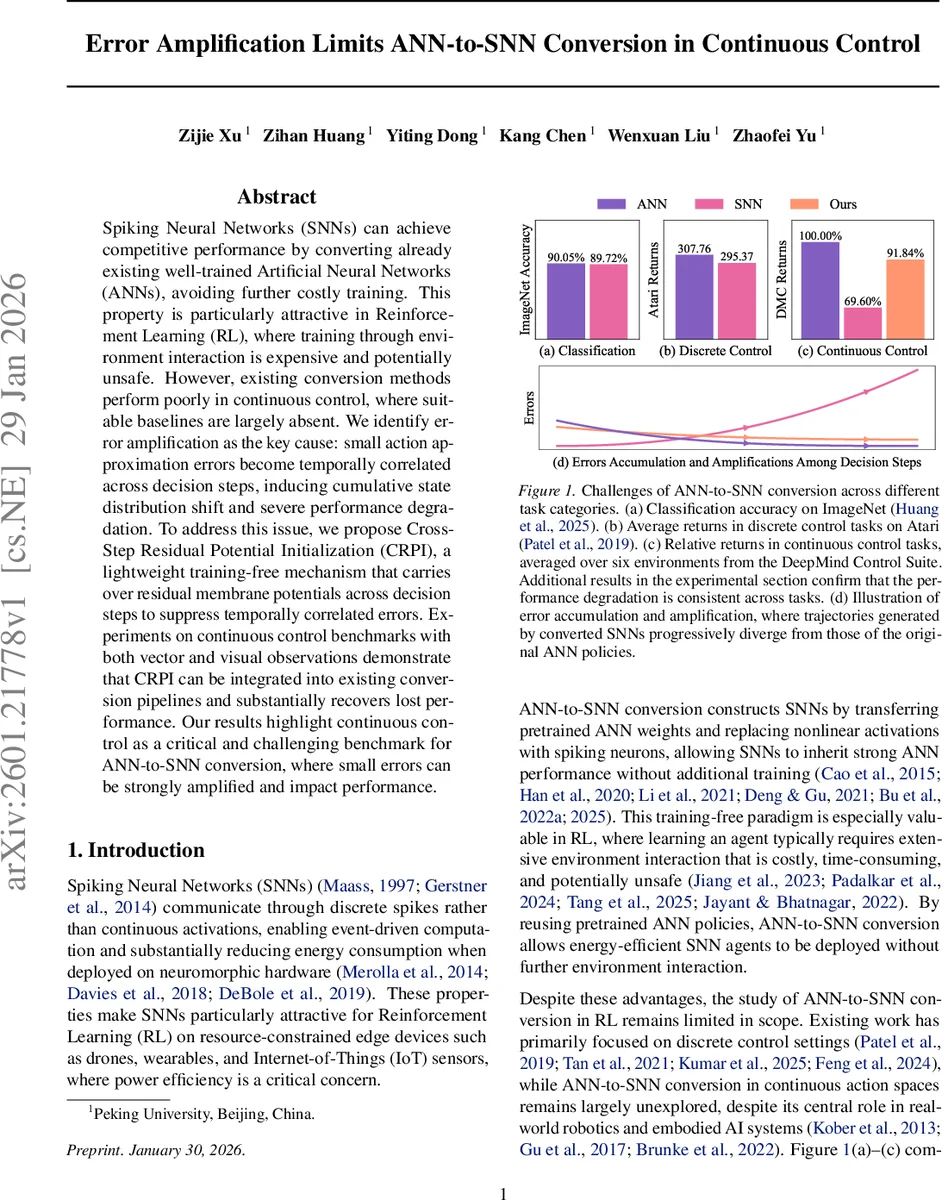
Spiking Neural Networks (SNNs) can achieve competitive performance by converting already existing well-trained Artificial Neural Networks (ANNs), avoiding further costly training. This property is particularly attractive in Reinforcement Learning (RL), where training through environment interaction is expensive and potentially unsafe. However, existing conversion methods perform poorly in continuous control, where suitable baselines are largely absent. We identify error amplification as the key cause: small action approximation errors become temporally correlated across decision steps, inducing cumulative state distribution shift and severe performance degradation. To address this issue, we propose Cross-Step Residual Potential Initialization (CRPI), a lightweight training-free mechanism that carries over residual membrane potentials across decision steps to suppress temporally correlated errors. Experiments on continuous control benchmarks with both vector and visual observations demonstrate that CRPI can be integrated into existing conversion pipelines and substantially recovers lost performance. Our results highlight continuous control as a critical and challenging benchmark for ANN-to-SNN conversion, where small errors can be strongly amplified and impact performance.
💡 Research Summary
The paper investigates why converting pretrained artificial neural networks (ANNs) into spiking neural networks (SNNs) works well for image classification and discrete‑action reinforcement learning (RL) but fails dramatically in continuous‑control tasks. The authors first demonstrate a large performance gap on a suite of continuous‑control benchmarks (MuJoCo, DeepMind Control Suite) while showing that existing conversion pipelines achieve near‑state‑of‑the‑art results on classification and Atari games.
To pinpoint the cause, they decompose the expected return difference between the original ANN policy (π_ANN) and the converted SNN policy (π_SNN) into two factors: (i) the instantaneous action error (π_ANN vs. π_SNN) and (ii) the shift in the state visitation distribution (P_ANN vs. P_SNN). By constructing two auxiliary returns—R_SNN|ANN (using π_SNN but the ANN‑induced state distribution) and R_ANN|SNN (using π_ANN but the SNN‑induced state distribution)—they find that the action‑only term contributes less than 0.5 % loss, whereas the state‑distribution term accounts for the bulk of the degradation. Visualizations (t‑SNE, PCA) confirm that even tiny per‑step action discrepancies cause the trajectories of the SNN agent to diverge dramatically from those of the ANN agent over an episode.
The authors then examine how this divergence evolves. Because RL environments are Markovian, each action influences the next state, which in turn affects all future actions. Consequently, small action approximation errors accumulate across decision steps, leading to progressive state drift and a widening return gap. Empirical plots of state evolution and per‑step reward illustrate that the gap is negligible at the start of an episode but grows steadily as the horizon lengthens.
A key insight is that the per‑step action errors are positively temporally correlated. The paper reports cosine‑similarity measurements of action error vectors across consecutive steps, showing high similarity across a variety of environments. This positive correlation means that an error made at step k tends to persist at step k + 1, preventing the system from self‑correcting and amplifying the error over time.
Existing ANN‑to‑SNN conversion methods reset all neuronal states (membrane potentials) at the beginning of each decision step, thereby discarding any information that could counteract the temporal correlation. To break this loop, the authors propose Cross‑Step Residual Potential Initialization (CRPI). After the internal simulation of T time steps for a decision, the residual membrane potentials of all neurons are carried over as the initial potentials for the next decision step instead of being zero‑initialized. This simple, training‑free modification preserves the “memory” of the previous step, making the spiking response to the same observation more consistent across steps and dramatically reducing the temporal correlation of action errors.
CRPI can be plugged into any existing conversion pipeline (weight normalization, threshold balancing, signed spikes, multi‑threshold neurons, etc.) without additional training. The authors evaluate CRPI on a broad set of continuous‑control tasks, both vector‑based (HalfCheetah, Hopper, Walker2d) and vision‑based (DMControl suite). Across all baselines, CRPI yields substantial performance recovery, often narrowing the return gap by 20–40 % and, in several vision tasks, surpassing directly trained SNN policies. The method also proves robust to different simulation horizons (T = 8, 16, 32) and to various neuron models.
In summary, the paper makes three major contributions: (1) it identifies error amplification—driven by temporally correlated action errors and resulting state‑distribution shift—as the primary bottleneck for ANN‑to‑SNN conversion in continuous control; (2) it provides a quantitative analysis of the temporal correlation of errors; and (3) it introduces CRPI, a lightweight, training‑free technique that mitigates error amplification and enables energy‑efficient spiking policies to perform competitively on high‑dimensional, long‑horizon control problems. This work opens a practical pathway for deploying low‑power SNN agents on edge devices such as drones, wearables, and IoT robots that require precise continuous‑action control.
Comments & Academic Discussion
Loading comments...
Leave a Comment