Influence Guided Sampling for Domain Adaptation of Text Retrievers
General-purpose open-domain dense retrieval systems are usually trained with a large, eclectic mix of corpora and search tasks. How should these diverse corpora and tasks be sampled for training? Conventional approaches sample them uniformly, proportional to their instance population sizes, or depend on human-level expert supervision. It is well known that the training data sampling strategy can greatly impact model performance. However, how to find the optimal strategy has not been adequately studied in the context of embedding models. We propose Inf-DDS, a novel reinforcement learning driven sampling framework that adaptively reweighs training datasets guided by influence-based reward signals and is much more lightweight with respect to GPU consumption. Our technique iteratively refines the sampling policy, prioritizing datasets that maximize model performance on a target development set. We evaluate the efficacy of our sampling strategy on a wide range of text retrieval tasks, demonstrating strong improvements in retrieval performance and better adaptation compared to existing gradient-based sampling methods, while also being 1.5x to 4x cheaper in GPU compute. Our sampling strategy achieves a 5.03 absolute NDCG@10 improvement while training a multilingual bge-m3 model and an absolute NDCG@10 improvement of 0.94 while training all-MiniLM-L6-v2, even when starting from expert-assigned weights on a large pool of training datasets.
💡 Research Summary
The paper tackles a fundamental yet under‑explored problem in dense retrieval: how to sample from a massive, heterogeneous pool of training corpora and tasks so that a model adapts best to a target domain. Conventional strategies—uniform sampling, size‑proportional sampling, or expert‑assigned static weights—are simple but ignore the varying informativeness of each dataset. Recent dynamic methods such as DDS, Multi‑DDS, DoGE, and DoReMi attempt to learn sampling weights online, but they rely on noisy gradient‑based reward signals or expensive proxy models, leading to instability and high GPU costs.
Inf‑DDS (Influence‑guided Dynamic Data Sampling) is introduced as a reinforcement‑learning framework that replaces gradient‑based rewards with influence‑based rewards. The authors formulate the problem as a bilevel optimization: the lower level updates model parameters θ via standard gradient descent on sampled batches, while the upper level learns a parameterized sampling policy ψ (softmax over per‑dataset scores) that maximizes performance on one or more development sets. The key novelty lies in how the reward for each training dataset Di is computed. At each iteration, the current model θt is fine‑tuned on Di for a small number l of steps, producing θi,t+1. The change in a downstream metric M (e.g., NDCG@10) on each dev batch dj,val is measured: ΔMij = M(θi,t+1; dj,val) – M(θt; dj,val). Averaging ΔMij over all dev sets yields a dataset‑level influence score Ii, which directly reflects how much up‑weighting Di would improve the target metric.
These influence scores are then used in two ways:
-
Model update – A Reptile‑style first‑order meta‑update aggregates the per‑dataset parameter differences weighted by Ii, producing a normalized gradient (\bar{\nabla}_t). The model is updated as θt+1 = θt + α (\bar{\nabla}_t). This reuses the same gradient cache for all domains, dramatically reducing memory overhead.
-
Sampler update – Using the REINFORCE gradient, the policy parameters ψ are updated with the same influence scores: ∇ψ = Σi P_D(i;ψ) Ii ∇ψ log P_D(i;ψ). To keep computation tractable when the number of domains M is large, a random subset S (|S| = k < M) is sampled each iteration, and the policy gradient is computed only over S, yielding an unbiased estimator for the conditional objective and a biased but practical estimator for the full objective.
The authors evaluate Inf‑DDS on three settings:
-
BEIR benchmark – Seven heterogeneous retrieval tasks (MSMarco, NQ, FEVER, FiQA, HotpotQA, SciFact, NFCorpus) are used for training, with FEVER dev as the primary target. Inf‑DDS outperforms uniform, size‑proportional, expert‑weight, DDS, Multi‑DDS, and DoGE baselines, delivering average NDCG@10 gains of 0.8–1.2 points across the test sets.
-
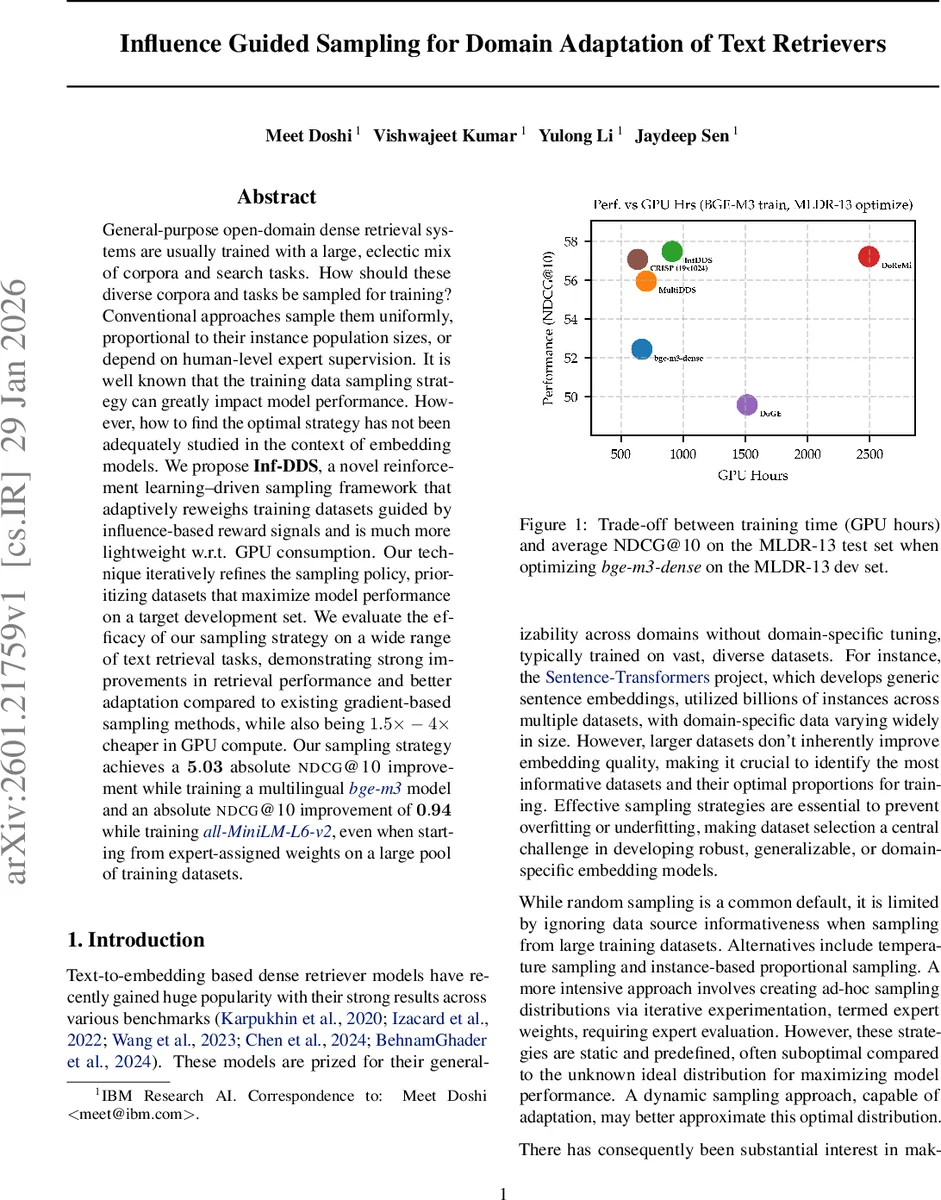
Multilingual Long Document Retrieval (MLDR‑13) – Each language is treated as a domain. Starting from a 568 M‑parameter bge‑m3 checkpoint, Inf‑DDS improves NDCG@10 by 5.03 absolute points on the multilingual test set, while using 1.5–4× fewer GPU hours than gradient‑based baselines.
-
Sentence‑Transformers large‑scale training – Using the 1 B‑sentence, 32‑dataset corpus originally used to train all‑MiniLM‑L6‑v2, the authors begin with the expert‑assigned sampling weights and let Inf‑DDS adapt them. The resulting model gains 0.94 absolute NDCG@10 on the target evaluation set, again with a substantial reduction in compute.
Across all experiments, Inf‑DDS demonstrates greater stability (lower variance in reward signals) and significant compute savings because it avoids repeated back‑propagation through large proxy networks and leverages a single gradient cache per iteration.
The paper also discusses limitations: computing influence scores for every domain each step can still be costly when M is extremely large, prompting the need for careful choice of the subsample size k. The method operates at the dataset level, so it cannot differentiate informative versus noisy instances within the same corpus; future work could combine dataset‑level influence with instance‑level importance sampling. Finally, the current formulation optimizes a single (or averaged) dev metric; extending to multi‑objective settings (e.g., fairness, latency) would require more sophisticated reward design.
In summary, Inf‑DDS offers a principled, influence‑driven reinforcement learning approach to dynamic data sampling for dense retrieval, achieving state‑of‑the‑art performance improvements while cutting GPU costs by up to fourfold. It provides a compelling blueprint for large‑scale, multi‑domain embedding training where data selection is as critical as model architecture.
Comments & Academic Discussion
Loading comments...
Leave a Comment