Breaking the Overscaling Curse: Thinking Parallelism Before Parallel Thinking
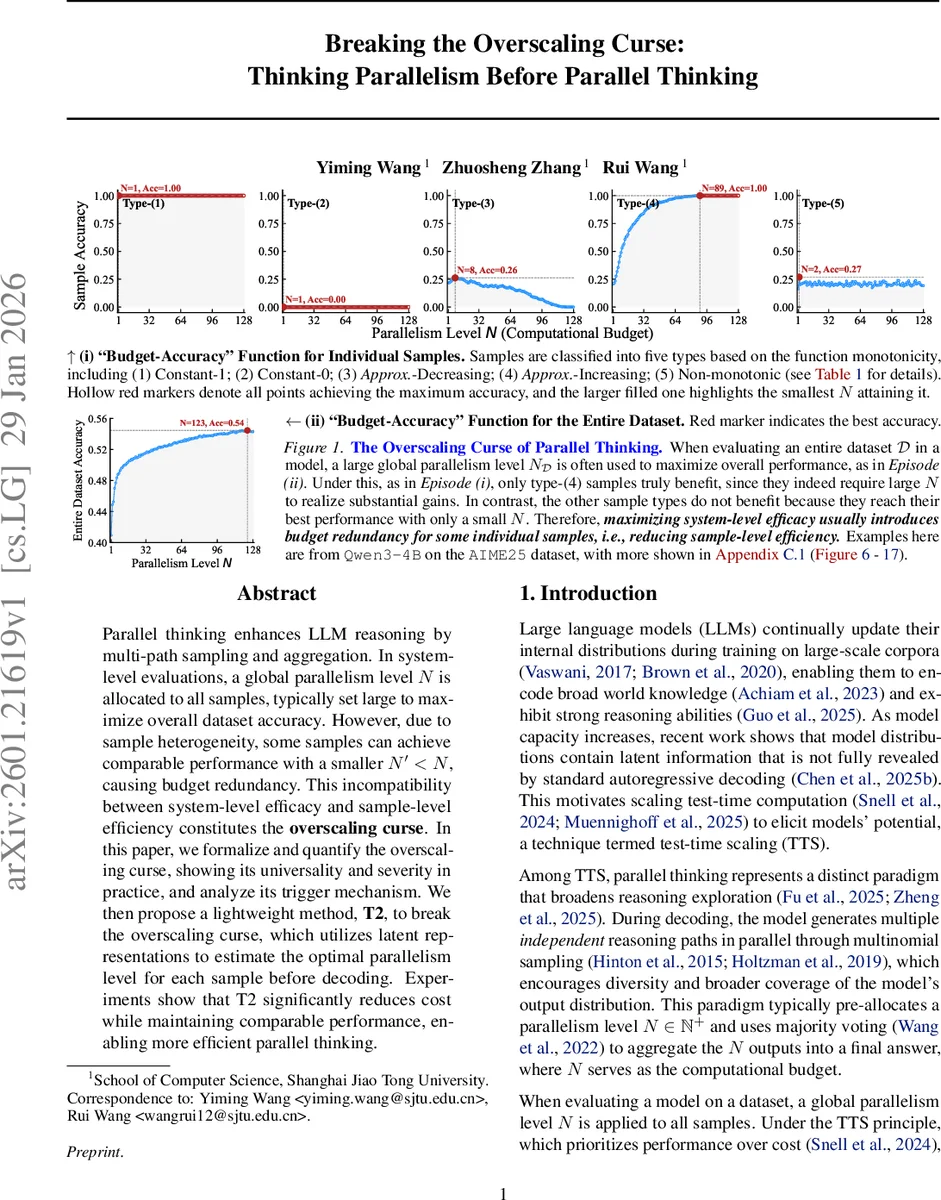
Parallel thinking enhances LLM reasoning by multi-path sampling and aggregation. In system-level evaluations, a global parallelism level N is allocated to all samples, typically set large to maximize overall dataset accuracy. However, due to sample heterogeneity, some samples can achieve comparable performance with a smaller N’< N, causing budget redundancy. This incompatibility between system-level efficacy and sample-level efficiency constitutes the overscaling curse. In this paper, we formalize and quantify the overscaling curse, showing its universality and severity in practice, and analyze its trigger mechanism. We then propose a lightweight method, T2, to break the overscaling curse, which utilizes latent representations to estimate the optimal parallelism level for each sample before decoding. Experiments show that T2 significantly reduces cost while maintaining comparable performance, enabling more efficient parallel thinking.
💡 Research Summary
The paper investigates a fundamental inefficiency in “parallel thinking,” a test‑time scaling technique for large language models (LLMs). In parallel thinking, a model generates N independent reasoning paths for each input and aggregates them via majority voting. Conventional practice fixes a global parallelism level N_D for the entire dataset, often choosing a large N_D to maximize overall accuracy. The authors observe that many individual samples achieve their best performance with a much smaller parallelism level N′ than the globally chosen N_D, leading to wasted computation—a phenomenon they term the “overscaling curse.”
To formalize this, they define for each sample x a “budget‑accuracy” function A_x(N) that maps parallelism level to expected correctness. The sample‑optimal parallelism N*_x is the smallest N that maximizes A_x(N). The dataset‑optimal parallelism N_D is the smallest N that maximizes the average accuracy across all samples. When N_D exceeds the average of N*_x (i.e., N_D > N*_D), the system incurs redundant computation; this is the overscaling curse. They introduce the Overscaling Index M_D = N*_D / N_D, where values close to 1 indicate little waste and values near 0 indicate severe waste.
Empirical evaluation on four recent LLMs (Qwen2.5‑7B, Llama3.1‑8B, Deepseek‑R1‑Distill‑Qwen‑7B, Qwen3‑4B) and six benchmarks (MATH500, AMC, AIME24/25, GPQA, MMLU‑Pro) shows that M_D is always below 0.5, and in many cases below 0.2, meaning that at least half of the allocated compute is unnecessary.
The authors further categorize samples into five types based on the monotonicity of A_x(N):
- Constant‑1 (always correct)
- Constant‑0 (always incorrect)
- Approx‑decreasing (accuracy drops as N increases)
- Approx‑increasing (accuracy improves with larger N)
- Non‑monotonic (no clear trend)
Analysis reveals that type‑4 samples drive the need for large N_D because they gain substantial accuracy from higher parallelism, while the other types either gain nothing or even lose accuracy. Consequently, when type‑4 samples coexist with the rest, the global N_D is pulled upward, causing overscaling for the majority of samples.
To break this curse, the paper proposes T2 (Thinking Parallelism Before Parallel Thinking), a lightweight estimator that predicts the optimal parallelism for each input before decoding. T2 extracts the final‑token representation from each transformer layer, passes it through trainable, layer‑wise regressors, and aggregates them using learned layer weights (based on validation error). The resulting estimate ĤN* is used to allocate the exact number of parallel samples for that input. Training uses a regression loss over many (input, N, accuracy) tuples, while the layer weights are tuned to minimize validation error.
Experiments demonstrate that T2 reduces average inference latency and memory consumption by 35‑60 % compared to a fixed‑N baseline, while preserving overall accuracy within 0.1‑0.3 % of the baseline. Moreover, T2 outperforms prior adaptive‑budget methods in both efficiency and simplicity, and it generalizes across all tested models and datasets.
In summary, the paper (1) identifies and quantifies the overscaling curse in parallel thinking, (2) explains its root cause as the dominance of a minority of “type‑4” samples, and (3) offers a practical, representation‑based per‑sample parallelism predictor (T2) that eliminates most redundant computation without sacrificing performance. This work provides a clear pathway toward more cost‑effective test‑time scaling for LLMs and suggests that similar per‑sample budgeting could benefit other scaling techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment