Fast and Geometrically Grounded Lorentz Neural Networks
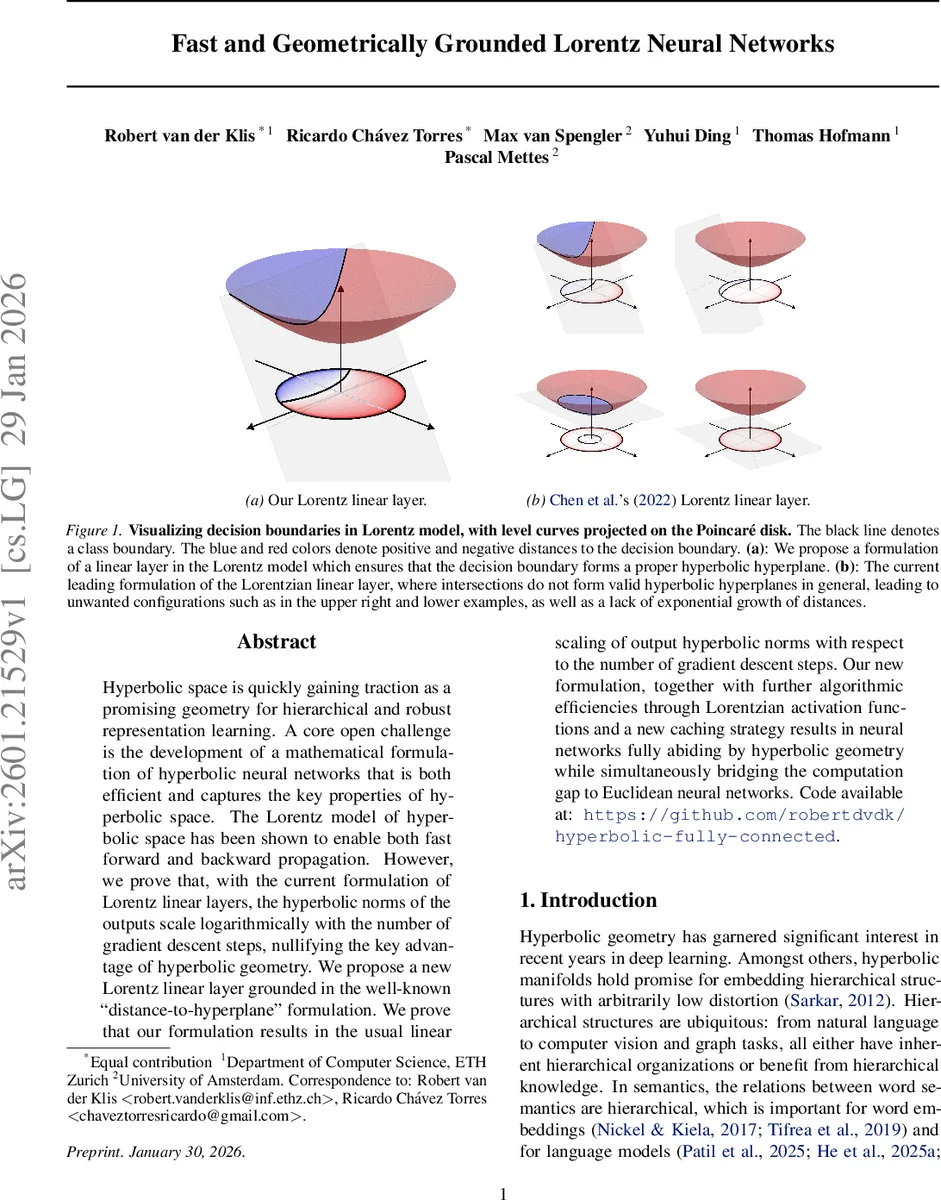
Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
💡 Research Summary
The paper addresses a critical flaw in current hyperbolic neural networks that operate in the Lorentz (hyperboloid) model. Existing Lorentz linear layers, following Chen et al. (2022), compute the spatial component of the output as a standard Euclidean matrix‑vector product Wx and set the time coordinate so that the resulting point lies on the hyperboloid. Because hyperbolic distance grows logarithmically with the Euclidean norm of the coordinates, the hyperbolic norm of the output increases only as O(log n) after n bounded‑norm gradient steps. The authors formalize this pathology through three propositions: (1) the hyperbolic norm increase is logarithmic under bounded updates; (2) low‑distortion embedding of an m‑ary tree requires a minimum parent‑child distance proportional to ln m; (3) consequently, embedding a hierarchy of depth h demands Ω(e^h) gradient updates, making the approach impractical for deep hierarchies.
To overcome this, the authors revisit the Euclidean interpretation of a linear layer as a signed, scaled distance to a hyperplane (the “distance‑to‑hyperplane” view) and transplant it into the Lorentz manifold. They define a reference point p_i on the hyperboloid by exponentiating from the origin along the direction of the weight vector w_i by a distance proportional to the bias b_i. The weight vector is then parallel‑transported to p_i, yielding a tangent‑space normal vector v_i. Using this construction, the hyperplane condition simplifies to the ambient orthogonality constraint z ◦ v_i = 0.
The pre‑activation for the i‑th neuron is defined as the signed, scaled hyperbolic distance from the input x to this hyperplane. Theorem 4.2 shows that the unsigned distance is (1/√κ) arcsinh(√κ |x ◦ v_i| / ‖v_i‖_L). Proposition 4.3 proves that the sign of this distance coincides with the sign of the Minkowski inner product x ◦ v_i. Multiplying by the Euclidean norm of the original weight ‖w_i‖_o yields the final pre‑activation:
z_i = (1/√κ) arcsinh(√κ x ◦ v_i / ‖v_i‖_L) · ‖w_i‖_o.
This formulation mirrors the Euclidean linear layer’s scaling behavior while respecting hyperbolic geometry, ensuring that the hyperbolic norm of the output grows linearly with the number of gradient steps rather than logarithmically.
Beyond the theoretical contribution, the authors introduce “Lorentzian activation” functions that remain closed within the Lorentz manifold, eliminating costly map‑back‑to‑Euclidean operations. They also propose a caching strategy: the transported normals v_i are pre‑computed and stored, so each forward/backward pass avoids repeated parallel transport, dramatically reducing computational overhead. Empirically, the new Lorentz linear layer is 2.9× faster than the current state‑of‑the‑art Lorentz networks and 8.3× faster than Poincaré‑based networks.
The complete architecture, named Fast and Geometrically Grounded Lorentz Neural Networks (FGG‑LNN), integrates the new linear layer, Lorentzian activations, and caching into a ResNet‑18 backbone. Experiments on hierarchical tasks demonstrate that FGG‑LNN trains 3.5× faster than the best existing Lorentz models and 7.5× faster than Poincaré models, while achieving comparable or slightly better accuracy and preserving low‑distortion hierarchical embeddings.
In summary, the paper delivers a mathematically sound, geometrically faithful, and computationally efficient solution to building fully hyperbolic neural networks. By grounding linear transformations in the distance‑to‑hyperplane perspective, it restores the exponential expressive power of hyperbolic space without incurring the previously observed logarithmic bottleneck, opening the door for practical hyperbolic deep learning in NLP, graph representation, few‑shot vision, and other domains where hierarchical structure is paramount.
Comments & Academic Discussion
Loading comments...
Leave a Comment