L2R: Low-Rank and Lipschitz-Controlled Routing for Mixture-of-Experts
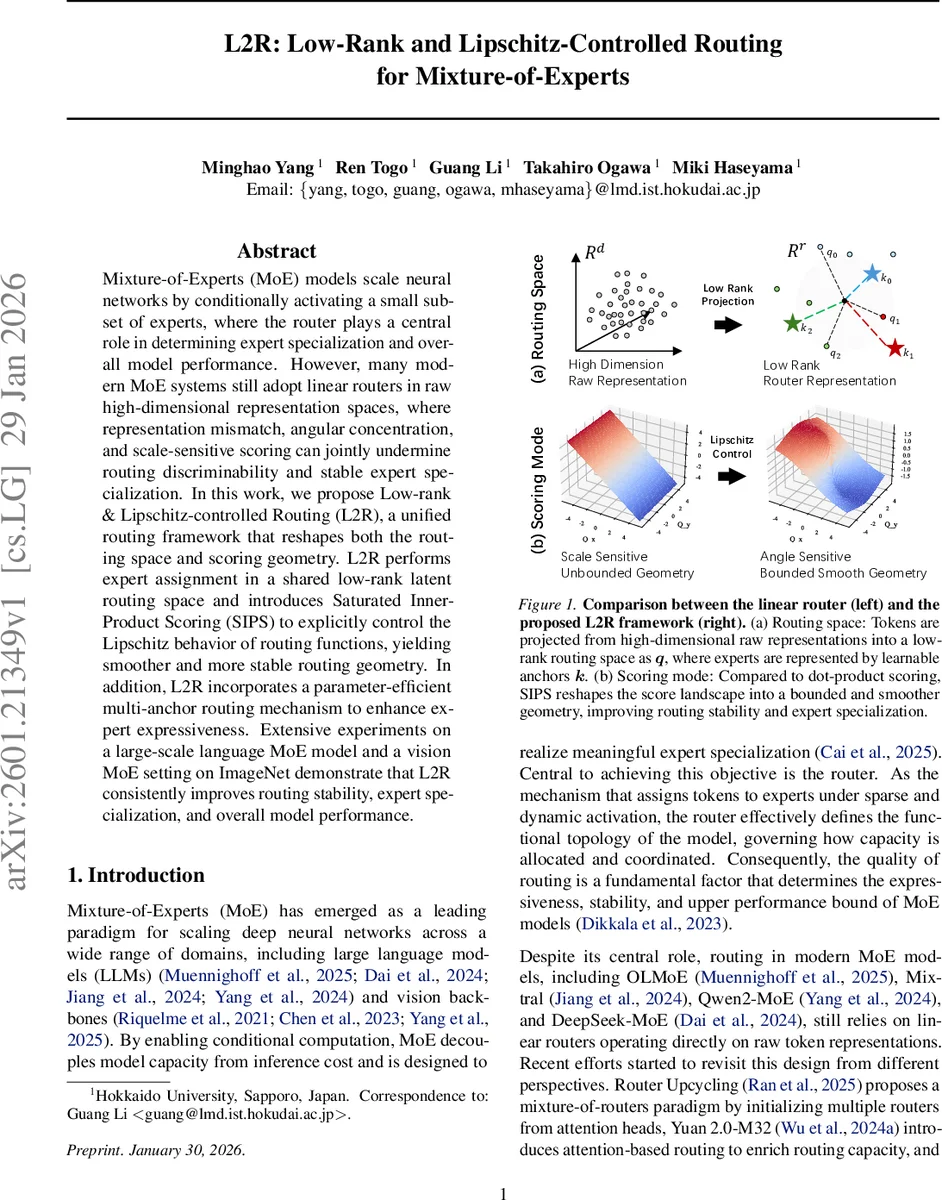
Mixture-of-Experts (MoE) models scale neural networks by conditionally activating a small subset of experts, where the router plays a central role in determining expert specialization and overall model performance. However, many modern MoE systems still adopt linear routers in raw high-dimensional representation spaces, where representation mismatch, angular concentration, and scale-sensitive scoring can jointly undermine routing discriminability and stable expert specialization. In this work, we propose Low-rank & Lipschitz-controlled Routing (L2R), a unified routing framework that reshapes both the routing space and scoring geometry. L2R performs expert assignment in a shared low-rank latent routing space and introduces Saturated Inner-Product Scoring (SIPS) to explicitly control the Lipschitz behavior of routing functions, yielding smoother and more stable routing geometry. In addition, L2R incorporates a parameter-efficient multi-anchor routing mechanism to enhance expert expressiveness. Extensive experiments on a large-scale language MoE model and a vision MoE setting on ImageNet demonstrate that L2R consistently improves routing stability, expert specialization, and overall model performance.
💡 Research Summary
Mixture‑of‑Experts (MoE) models achieve massive scaling by activating only a small subset of expert sub‑networks for each input token. The router, which decides which experts to activate, is therefore a critical component. Existing large‑scale MoE systems (e.g., OLMoE, Mixtral, Qwen2‑MoE, DeepSeek‑MoE) still rely on a simple linear router that computes expert logits directly from the high‑dimensional backbone representation using a single linear projection. This design suffers from two fundamental issues. First, the high‑dimensional raw representation is optimized for downstream tasks, not for discriminating among experts, leading to a representation mismatch. Second, in high‑dimensional spaces, angular similarities concentrate, making the dot‑product scores of different experts almost indistinguishable. Moreover, dot‑product scoring couples directional alignment with vector norms, so variations in token magnitude or expert anchor norm act like an input‑dependent softmax temperature, causing scale‑sensitive routing and norm‑dominated competition among experts.
The paper proposes Low‑rank & Lipschitz‑controlled Routing (L2R), a unified framework that reshapes both the routing space and the scoring geometry. L2R consists of three key components:
-
Low‑rank latent routing space – A shared projection matrix (W_q \in \mathbb{R}^{d \times r}) (with (r \ll d)) maps each backbone token (x) to a routing‑specific query (q = xW_q \in \mathbb{R}^r). Each expert (E_i) is represented by a learnable anchor (k_i \in \mathbb{R}^r). Routing logits are obtained by matching (q) with the set of anchors, essentially an attention‑like operation in a compressed space. This decouples routing from the raw representation, alleviates angular concentration, and reduces the search space for expert anchors, leading to more stable and discriminative expert placement. Empirically, the variance of pairwise cosine similarities in the low‑rank space is dramatically higher than in the raw space (Figure 2), confirming improved angular diversity.
-
Saturated Inner‑Product Scoring (SIPS) – To control Lipschitz continuity, the dot‑product logit (z_i = q^\top k_i) is factorized as
\
Comments & Academic Discussion
Loading comments...
Leave a Comment