Output-Space Search: Targeting LLM Generations in a Frozen Encoder-Defined Output Space
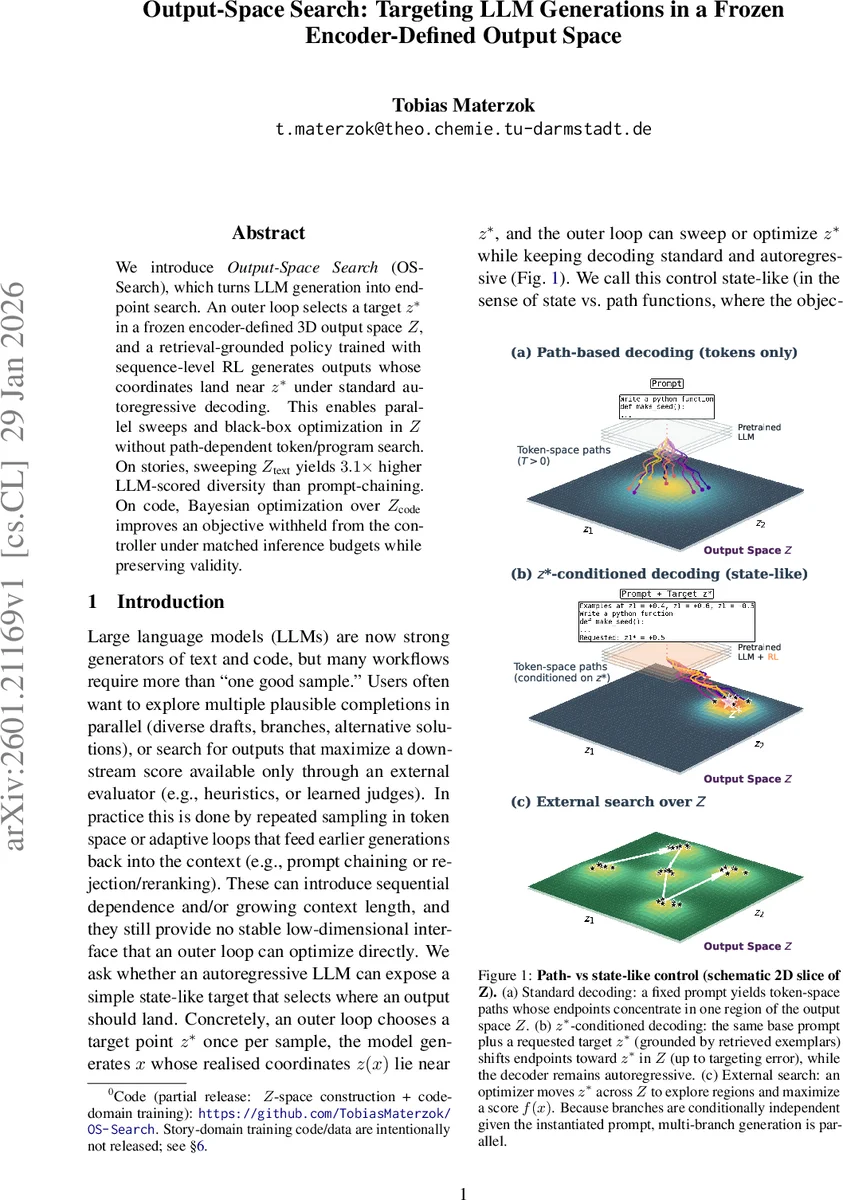
We introduce Output-Space Search (OS-Search), which turns LLM generation into endpoint search. An outer loop selects a target z* in a frozen encoder-defined 3D output space Z, and a retrieval-grounded policy trained with sequence-level RL generates outputs whose coordinates land near z* under standard autoregressive decoding. This enables parallel sweeps and black-box optimization in Z without path-dependent token/program search. On stories, sweeping Z (text) yields 3.1x higher LLM-scored diversity than prompt-chaining. On code, Bayesian optimization over Z (code) improves an objective withheld from the controller under matched inference budgets while preserving validity.
💡 Research Summary
The paper introduces Output‑Space Search (OS‑Search), a novel framework that reframes large language model (LLM) generation as an endpoint‑search problem in a frozen, encoder‑defined low‑dimensional output space Z (ℝ³). Instead of manipulating token‑level sampling or applying decoding‑time guidance, an outer loop selects a target point z* in Z, and a retrieval‑grounded policy conditioned on (p, z*) generates text or code whose embedding coordinates z(x) lie close to z*. The output space Z is built once per domain by applying PCA and a Varimax rotation to embeddings from a frozen encoder E, followed by a linear projection U; for story experiments an additional anchor aligns the first axis to a default style. During inference, the prompt includes the base prompt p, the numeric target z*, and three exemplars retrieved from a nearest‑neighbor index (two near z* and one near –z*), providing concrete grounding for the otherwise abstract coordinates.
The policy is fine‑tuned from Qwen‑3‑1.7B using QLoRA adapters and trained with group‑relative policy optimization (GRPO) together with sequence‑level corrections (GSPO). The reward combines three terms: (1) a hard validity gate R_format (ensuring coherent text or syntactically correct, executable code), (2) a distance reward R_dist that grows as z(x) approaches z* on the constrained axes, and (3) an honesty reward R_hon that penalizes mismatch between the model’s self‑reported coordinates ˆz and the true embedding z(x). This design forces the model to hit the target, remain valid, and accurately report its own position.
After training, the controller defines a black‑box mapping F: (p, z*) → x that can be used for two purposes. In the story domain, sweeping a grid or random set of z* values yields many conditionally independent branches that can be generated in parallel, achieving a 3.1× increase in LLM‑scored diversity compared to traditional prompt‑chaining. In the code domain, the authors embed the controller within a Bayesian optimization loop: a Gaussian‑process surrogate proposes z* candidates, the policy samples K candidates per z*, and the best is evaluated by a hidden objective f (e.g., performance of the generated program). This outer‑loop optimization improves the withheld objective while preserving 100 % validity of the generated programs.
OS‑Search thus provides a low‑dimensional, stable, user‑facing control interface that decouples the outer search from the inner autoregressive decoding, enabling embarrassingly parallel generation and black‑box optimization without path‑dependent token manipulation. Limitations include reliance on a fixed encoder (requiring re‑construction if the encoder changes) and the current choice of d_z = 3, which may be insufficient for more complex control demands. Nonetheless, the work demonstrates that treating LLM output as a coordinate in a frozen space opens a new paradigm for controllable generation, multi‑branch diversity, and external objective optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment