$π_ exttt{RL}$: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
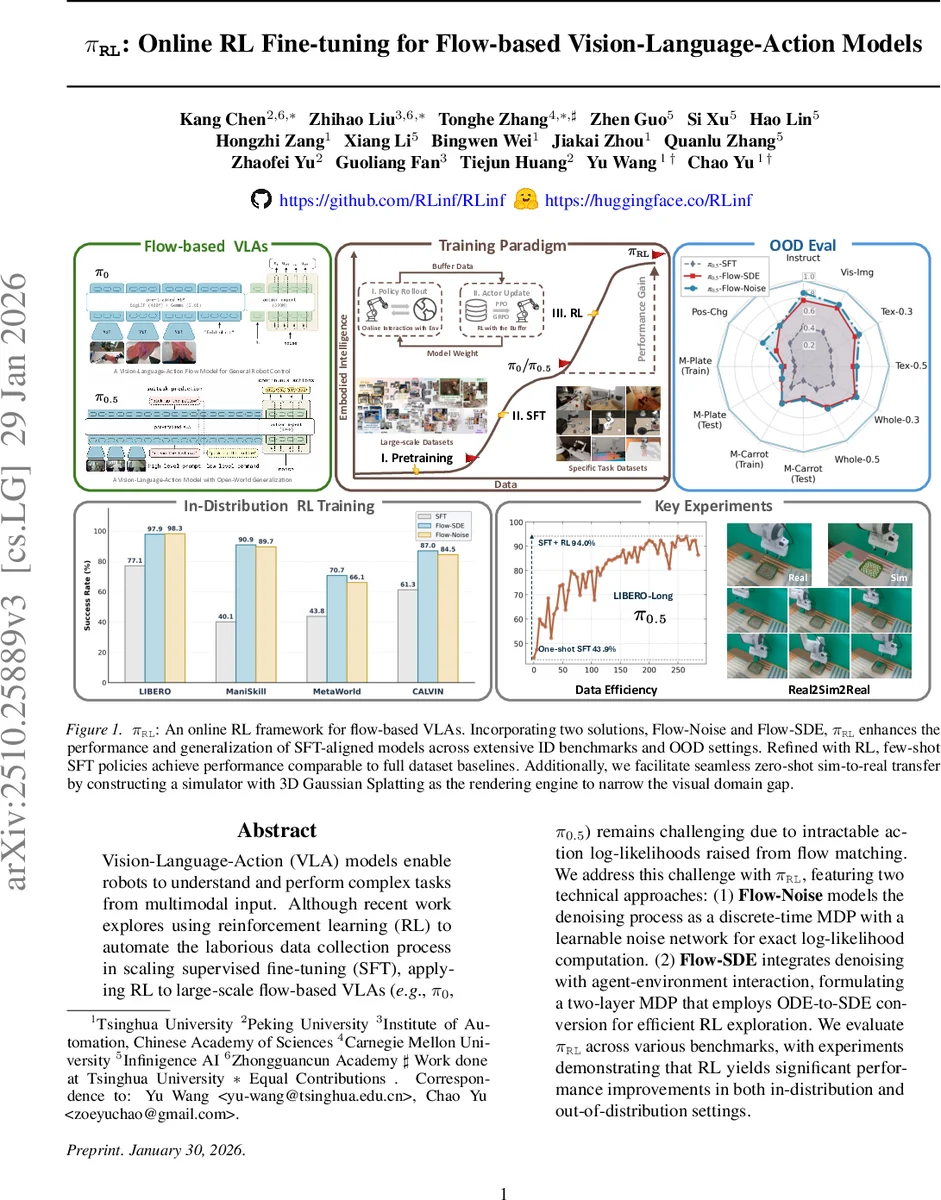
Vision-Language-Action (VLA) models enable robots to understand and perform complex tasks from multimodal input. Although recent work explores using reinforcement learning (RL) to automate the laborious data collection process in scaling supervised fine-tuning (SFT), applying RL to large-scale flow-based VLAs (\eg, $π_0$, $π_{0.5}$) remains challenging due to intractable action log-likelihoods raised from flow matching. We address this challenge with $π_{\texttt{RL}}$, featuring two technical approaches: (1) \textbf{Flow-Noise} models the denoising process as a discrete-time MDP with a learnable noise network for exact log-likelihood computation. (2) \textbf{Flow-SDE} integrates denoising with agent-environment interaction, formulating a two-layer MDP that employs ODE-to-SDE conversion for efficient RL exploration. We evaluate $π_{\texttt{RL}}$ across various benchmarks, with experiments demonstrating that RL yields significant performance improvements in both in-distribution and out-of-distribution settings.
💡 Research Summary
The paper introduces π_RL, a framework for online reinforcement‑learning (RL) fine‑tuning of flow‑based Vision‑Language‑Action (VLA) models such as π₀ and π₀.₅. Traditional VLA training follows a pre‑training → supervised fine‑tuning (SFT) pipeline, which relies heavily on large amounts of high‑quality human demonstrations. While recent works have added RL to autoregressive VLA models to improve performance and generalization, these methods cannot be applied to flow‑based models because the action generation process is deterministic and its log‑likelihood is intractable.
π_RL tackles this core obstacle with two complementary techniques.
- Flow‑Noise: The denoising stage of conditional flow matching is reformulated as a discrete‑time Markov decision process (MDP). A learnable noise network θ′ injects Gaussian noise at each denoising step, yielding a transition distribution
p(A_{τ+δ}|A_{τ}) = N(μ_{τ}, Σ_{τ}) with μ_{τ}=A_{τ}+v_{τ}·δ and Σ_{τ}=diag(σ_{θ′}²(A_{τ},o)).
Because the entire denoising trajectory (A₀,…,A₁) is now a sequence of tractable Gaussian transitions, the exact log‑probability log π(A|o)=∑{k}log π(A{τ_{k+1}}|A_{τ_{k}},o) can be computed. This enables direct use of the standard policy‑gradient objective ∇θJ = E
Comments & Academic Discussion
Loading comments...
Leave a Comment