Rotary Position Encodings for Graphs
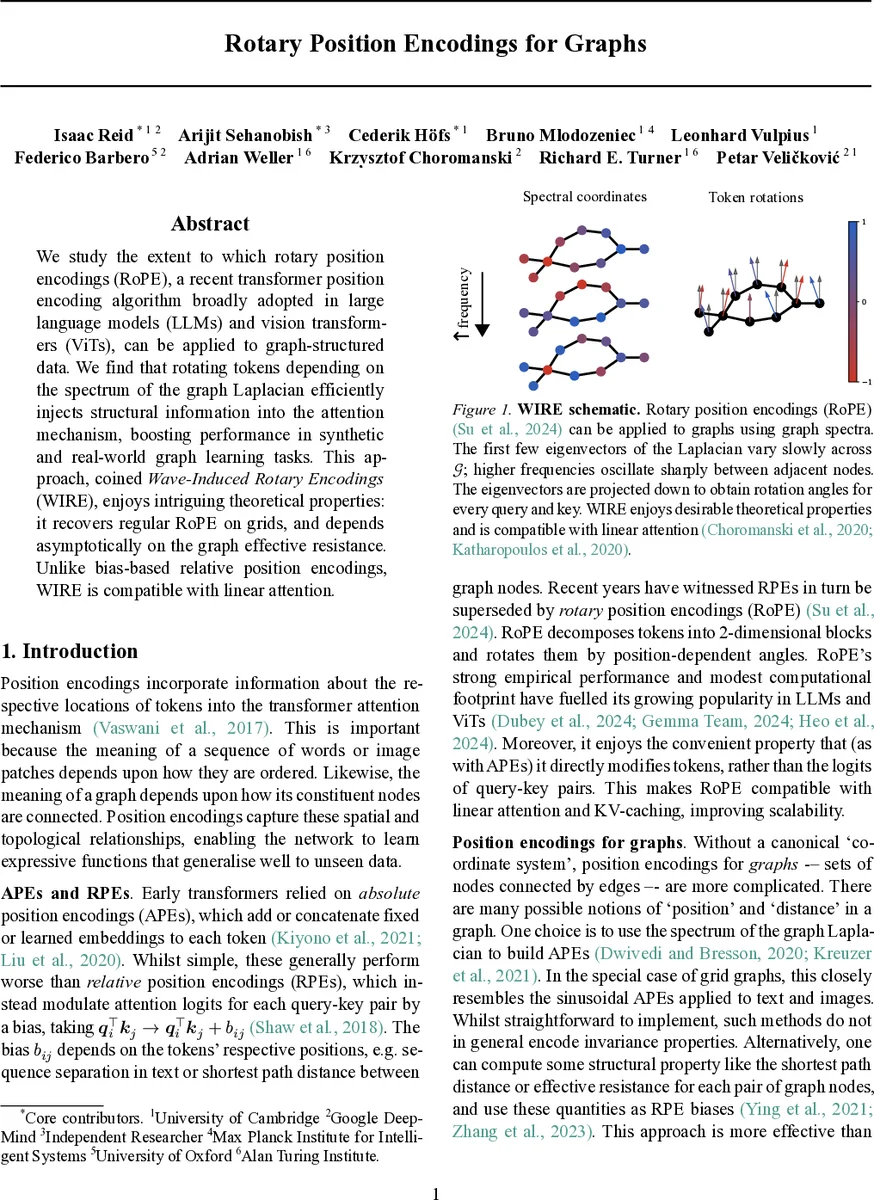
We study the extent to which rotary position encodings (RoPE), a recent transformer position encoding algorithm broadly adopted in large language models (LLMs) and vision transformers (ViTs), can be applied to graph-structured data. We find that rotating tokens depending on the spectrum of the graph Laplacian efficiently injects structural information into the attention mechanism, boosting performance in synthetic and real-world graph learning tasks. This approach, coined Wave-Induced Rotary Encodings (WIRE), enjoys intriguing theoretical properties: it recovers regular RoPE on grids, and depends asymptotically on the graph effective resistance. Unlike bias-based relative position encodings, WIRE is compatible with linear attention.
💡 Research Summary
The paper introduces Wave‑Induced Rotary Encodings (WIRE), a novel positional encoding scheme that adapts the Rotary Position Encoding (RoPE) technique—originally designed for sequences and images—to graph‑structured data. The authors observe that RoPE works by rotating token embeddings in 2‑dimensional subspaces according to position‑dependent angles, which are derived from simple sinusoidal frequencies. To bring this idea to graphs, they replace the linear position index with spectral coordinates obtained from the graph Laplacian.
The method proceeds as follows: (1) compute the smallest k eigenvectors of the graph Laplacian (exactly or via an iterative approximation such as Lanczos); (2) treat the values of these eigenvectors at each node as a low‑dimensional coordinate vector; (3) apply the standard RoPE rotation to each 2‑dimensional block of the token embedding, using angles defined as the product of a learnable (or fixed) frequency ω and the corresponding spectral coordinate. Because the rotation is applied directly to the query and key vectors, the resulting attention scores automatically incorporate structural information without needing an explicit bias term. This makes WIRE compatible with linear‑attention mechanisms, which rely on kernel‑style decompositions of the attention matrix.
Theoretical contributions are threefold. First, the authors prove that WIRE is permutation‑equivariant: reordering the nodes merely permutes rows and columns of the Laplacian, and the eigenvectors transform accordingly, up to sign flips and rotations within degenerate eigenspaces. This mirrors the well‑known gauge ambiguity in spectral graph methods and can be mitigated by simple post‑processing (sign‑normalisation, maximal‑axis projection) or left for the model to learn. Second, they show that on grid graphs (paths, 2‑D lattices, 3‑D lattices) the Laplacian eigenvectors are essentially sinusoidal functions. Consequently, applying WIRE to a grid reproduces exactly the original RoPE used in language models and Vision Transformers. This establishes that RoPE is a special case of WIRE, providing a sanity check and linking the new method to its successful predecessors. Third, they demonstrate that when higher‑frequency eigenvectors are included, the rotation angles become proportional to the graph’s effective resistance between nodes. Effective resistance is a continuous analogue of shortest‑path distance, so WIRE implicitly down‑weights attention between distant nodes without explicitly constructing a distance matrix.
Empirically, the authors evaluate WIRE on three fronts. (a) Synthetic tasks that stress spectral awareness (e.g., community detection, graph signal denoising) show that WIRE‑augmented transformers converge faster and achieve higher accuracy than absolute‑position encodings, relative‑position bias methods, and the Graphormer baseline. (b) Point‑cloud classification and 3‑D object recognition experiments demonstrate that WIRE works seamlessly with linear attention, reducing memory consumption by up to 70 % while preserving performance comparable to full‑softmax attention. (c) Large‑scale real‑world benchmarks (OGB‑MolPCBA, OGB‑Arxiv, Cora, PubMed) reveal consistent gains of 1–3 percentage points in ROC‑AUC or classification accuracy over strong baselines, even when the eigenvectors are approximated rather than computed exactly. Parameter analysis shows that the only additional learnable parameters are the frequencies ω, typically d/2 per layer (d being the token dimension), amounting to less than 0.1 % of the total model size. Sharing ω across layers or fixing them to an exponential decay schedule incurs negligible performance loss, highlighting the method’s efficiency.
The paper also discusses practical considerations. Computing the full spectrum can be costly for very large or dynamic graphs; however, the authors note that a modest number of eigenvectors (e.g., k ≈ 10–20) already captures most of the structural signal needed for the tasks examined. They suggest future work on dynamic spectral updates, meta‑learning of ω, and extensions to hypergraphs or heterogeneous networks.
In summary, WIRE provides a principled, theoretically grounded, and empirically validated way to bring the benefits of RoPE to graph neural networks. By leveraging Laplacian eigenvectors, it injects multi‑scale structural cues directly into token embeddings, remains compatible with scalable linear‑attention architectures, and requires only a tiny overhead of learnable frequencies. This work bridges a gap between spectral graph methods and modern transformer designs, offering a compelling alternative to bias‑based relative position encodings that often suffer from quadratic memory costs.
Comments & Academic Discussion
Loading comments...
Leave a Comment