GEPO: Group Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning
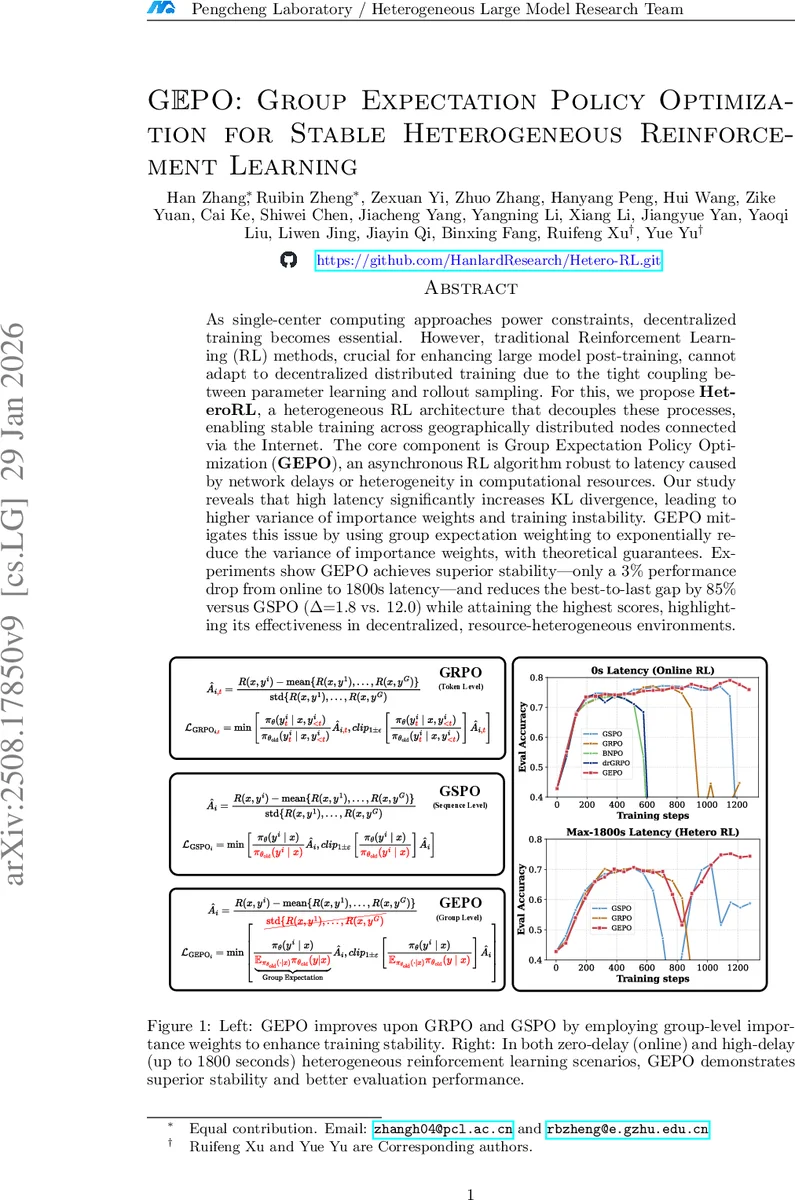
As single-center computing approaches power constraints, decentralized training becomes essential. However, traditional Reinforcement Learning (RL) methods, crucial for enhancing large model post-training, cannot adapt to decentralized distributed training due to the tight coupling between parameter learning and rollout sampling. For this, we propose HeteroRL, a heterogeneous RL architecture that decouples these processes, enabling stable training across geographically distributed nodes connected via the Internet. The core component is Group Expectation Policy Optimization (GEPO), an asynchronous RL algorithm robust to latency caused by network delays or heterogeneity in computational resources. Our study reveals that high latency significantly increases KL divergence, leading to higher variance of importance weights and training instability. GEPO mitigates this issue by using group expectation weighting to exponentially reduce the variance of importance weights, with theoretical guarantees. Experiments show GEPO achieves superior stability - only a 3% performance drop from online to 1800s latency-and reduces the best-to-last gap by 85% versus GSPO (1.8 vs. 12.0) while attaining the highest scores, highlighting its effectiveness in decentralized, resource-heterogeneous environments.
💡 Research Summary
The paper addresses a pressing problem in modern AI: how to perform reinforcement‑learning (RL) fine‑tuning of large language models (LLMs) when the training infrastructure is geographically distributed, heterogeneous, and subject to high network latency. Traditional RL pipelines tightly couple rollout generation with parameter updates, assuming low‑latency, homogeneous clusters. In a real‑world setting where some nodes run on GPUs, others on ASICs, and communication traverses the public Internet, this coupling leads to two major bottlenecks. First, slower nodes cause idle time on faster hardware, dramatically reducing overall throughput. Second, the delay between when a policy generates a trajectory and when the learner updates the parameters creates policy staleness (τ), which inflates the KL divergence between the “stale” policy (π θ_k) and the current policy (π θ_{k+τ}). High KL divergence, in turn, blows up the variance of importance‑sampling weights, destabilising training and often causing reward collapse.
To solve these issues, the authors propose HeteroRL, an asynchronous RL framework that decouples rollout sampling from learning. Sampler nodes continuously generate groups of responses for each prompt without waiting for the learner. Learner nodes consume these groups from a queue and perform gradient updates at their own pace. Communication is limited to occasional checkpoint exchanges and batch transfers, making the system tolerant to arbitrary delays, even up to 1800 seconds.
The core algorithmic contribution is Group Expectation Policy Optimization (GEPO). GEPO replaces the conventional token‑level importance weight p(y|x)/q(y|x) with a group‑level weight:
w_GEIW(y|x) = p(y|x) · E_q
Comments & Academic Discussion
Loading comments...
Leave a Comment