DBellQuant: Breaking the Bell with Double-Bell Transformation for LLMs Post Training Binarization
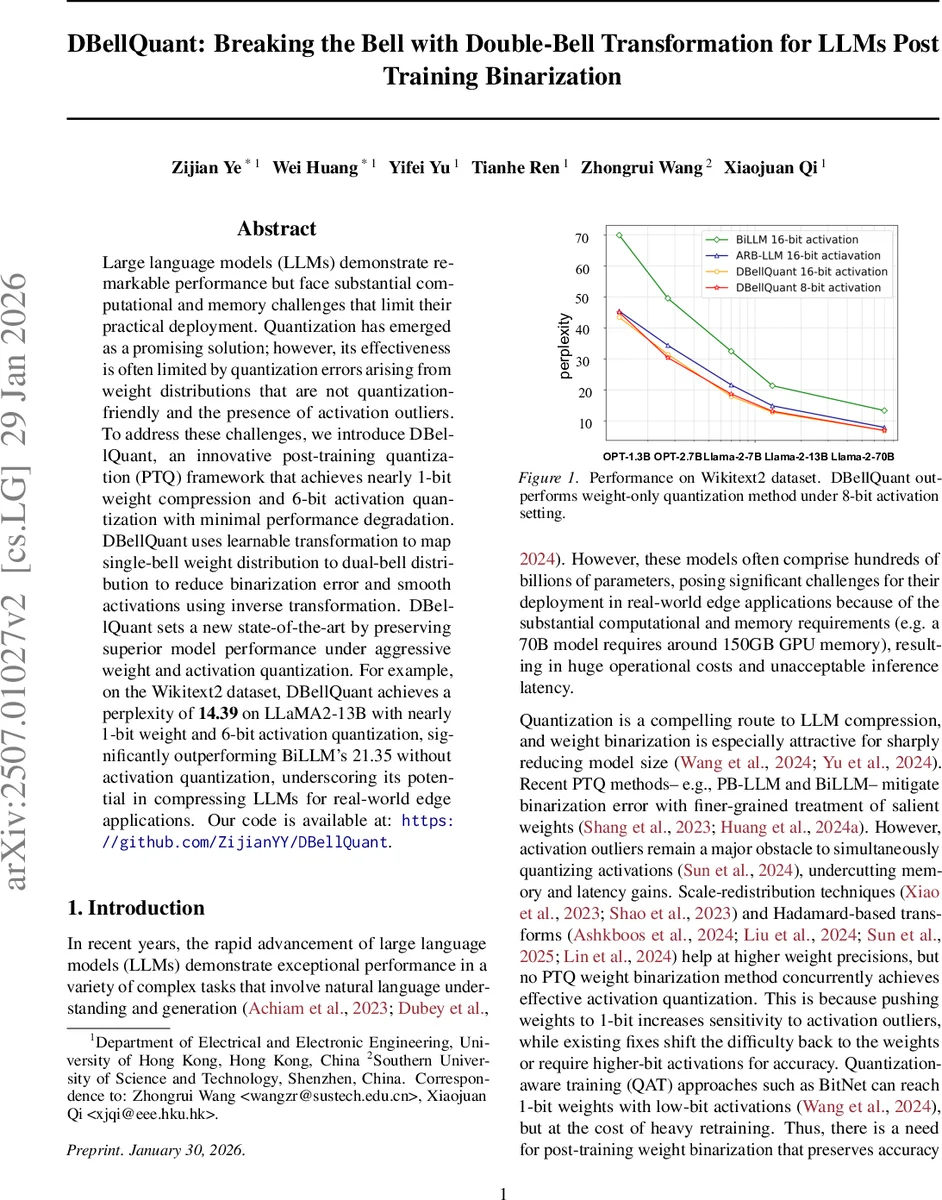
Large language models (LLMs) demonstrate remarkable performance but face substantial computational and memory challenges that limit their practical deployment. Quantization has emerged as a promising solution; however, its effectiveness is often limited by quantization errors arising from weight distributions that are not quantization-friendly and the presence of activation outliers. To address these challenges, we introduce DBellQuant, an innovative post-training quantization (PTQ) framework that achieves nearly 1-bit weight compression and 6-bit activation quantization with minimal performance degradation. DBellQuant uses Learnable Transformation for Dual-Bell (LTDB) algorithm, which transforms single-bell weight distributions into dual-bell forms to reduce binarization errors and applies inverse transformations to smooth activations. DBellQuant sets a new state-of-the-art by preserving superior model performance under aggressive weight and activation quantization. For example, on the Wikitext2 dataset, DBellQuant achieves a perplexity of 14.39 on LLaMA2-13B with 6-bit activation quantization, significantly outperforming BiLLM’s 21.35 without activation quantization, underscoring its potential in compressing LLMs for real-world applications.
💡 Research Summary
DBellQuant introduces a novel post‑training quantization (PTQ) framework that simultaneously achieves near‑1‑bit weight compression and 6‑bit activation quantization for large language models (LLMs) with only marginal performance loss. The core insight is that the typical unimodal (single‑bell) weight distribution of LLMs is poorly suited for binary quantization, because mapping a single Gaussian peak onto the binary levels (‑1, +1) creates substantial overlap and quantization error. In contrast, a bimodal (dual‑bell) distribution—essentially a mixture of two Gaussians—aligns naturally with the two binary levels, dramatically reducing binarization error.
To convert the weight distribution, the authors propose the Learnable Transformation for Dual‑Bell (LTDB) algorithm. Rather than learning a full‑size auxiliary matrix T (which would be computationally prohibitive for matrices of size 4096 × 4096), they reduce T to a 1 × C element‑wise scaling vector. The transformed weights are obtained by element‑wise multiplication W′ = T ⊙ W, while the inverse scaling T⁻¹ is applied to the input activations X (i.e., X′ = X ⊙ T⁻¹). This equivariant transformation guarantees that the overall linear operation X W remains unchanged, preserving model semantics.
Initialization of T is “activation‑aware”: each channel’s scaling factor is set according to the ratio of the maximum absolute activation value to the maximum absolute weight value (Equation 4). This scheme automatically amplifies small‑magnitude weights and attenuates large‑magnitude weights, pushing the weight values toward two symmetric clusters. Simultaneously, because the same scaling is applied inversely to activations, outlier activations are compressed, yielding a narrower activation distribution that is far more amenable to low‑bit quantization.
Theoretical support is provided via Theorem 1, which proves that for any weight matrix whose channels follow a single‑bell Gaussian distribution, there exists a learnable matrix T that can transform each channel into a mixture of two Gaussians (dual‑bell). The proof is detailed in the appendix. The authors also define a Dual‑Target Minimum Deviation loss that explicitly encourages the transformed weights to cluster around the two modes and serves as an early‑stopping criterion for the LTDB optimization.
Empirically, DBellQuant is evaluated on several state‑of‑the‑art LLMs, including LLaMA‑2‑13B, LLaMA‑2‑7B, and OPT‑1.3B, using the Wikitext‑2 benchmark. With 1‑bit weights and 6‑bit activations, LLaMA‑2‑13B achieves a perplexity of 14.39, outperforming BiLLM (21.35) which does not even quantize activations. LLaMA‑2‑7B reaches perplexities of 21.69 (6‑bit) and 23.04 (4‑bit), again surpassing prior PTQ methods such as PB‑LLM and SmoothQuant. Memory consumption drops dramatically; a 70‑billion‑parameter model that normally requires ~150 GB of GPU memory can be run with under 20 GB after DBellQuant compression.
Compared to existing PTQ techniques, DBellQuant uniquely addresses both weight binarization and activation outliers within a single, lightweight transformation, without any retraining or fine‑tuning. Prior works either focus on weight‑only quantization, rely on scaling‑factor redistribution that merely shifts difficulty from activations to weights, or require quantization‑aware training (QAT) that is computationally expensive. DBellQuant’s element‑wise scaling vector introduces negligible overhead, is easily fused into existing LayerNorm and linear layers, and can be applied to any pretrained LLM in a few minutes.
In summary, DBellQuant demonstrates that (1) a learnable, low‑dimensional transformation can reshape weight distributions into a dual‑bell form optimal for binary quantization, (2) the inverse transformation simultaneously smooths activation distributions, enabling 6‑bit (or even 4‑bit) activation quantization, and (3) this combined strategy yields state‑of‑the‑art PTQ performance across multiple LLM families. The work opens a promising direction for ultra‑compact LLM deployment on edge devices, and future research may explore regularization of the scaling vector, extension to mixed‑precision schemes, and real‑world latency benchmarks on commodity hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment