One-Shot Federated Learning with Classifier-Free Diffusion Models
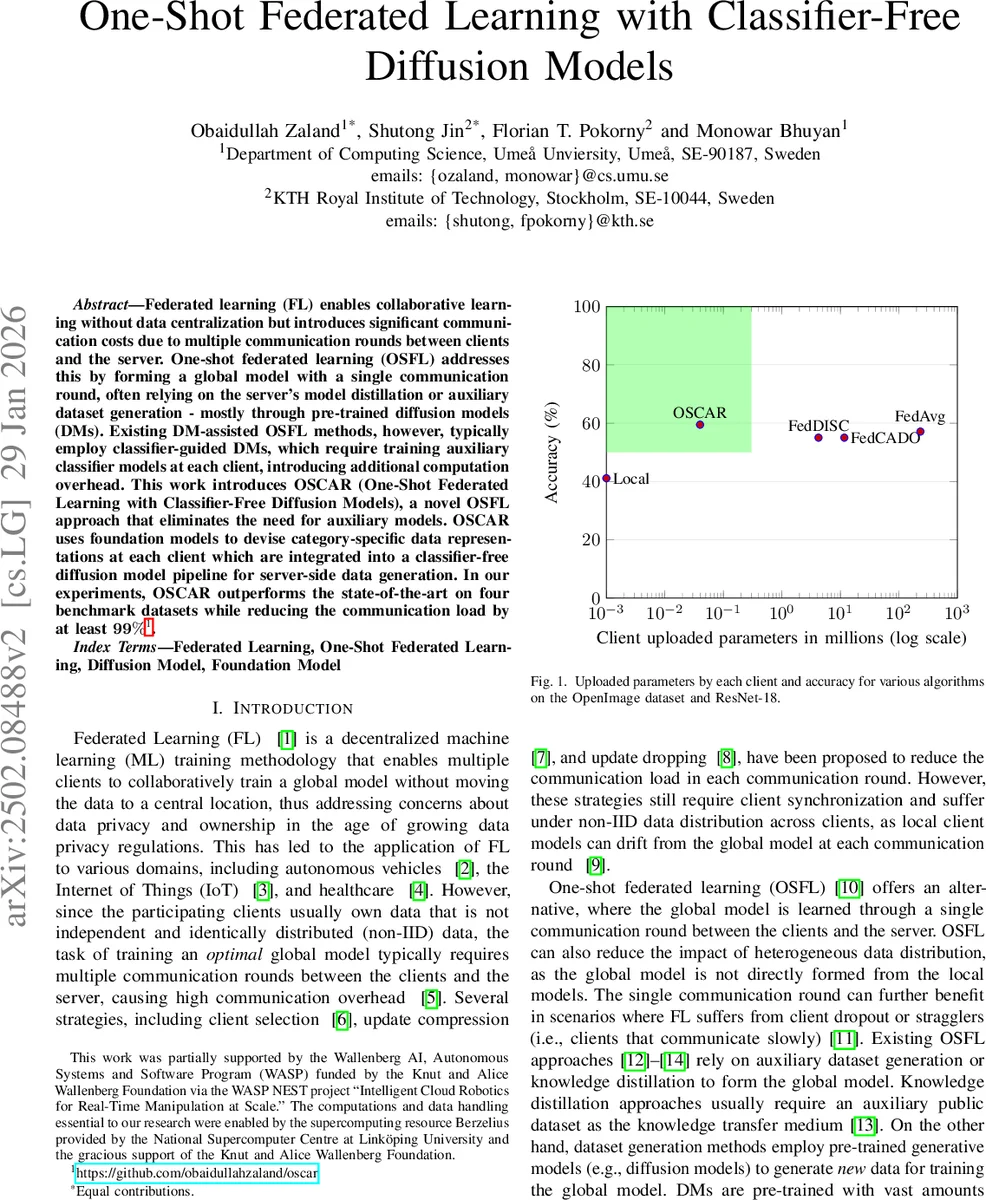
Federated learning (FL) enables collaborative learning without data centralization but introduces significant communication costs due to multiple communication rounds between clients and the server. One-shot federated learning (OSFL) addresses this by forming a global model with a single communication round, often relying on the server’s model distillation or auxiliary dataset generation - mostly through pre-trained diffusion models (DMs). Existing DM-assisted OSFL methods, however, typically employ classifier-guided DMs, which require training auxiliary classifier models at each client, introducing additional computation overhead. This work introduces OSCAR (One-Shot Federated Learning with Classifier-Free Diffusion Models), a novel OSFL approach that eliminates the need for auxiliary models. OSCAR uses foundation models to devise category-specific data representations at each client which are integrated into a classifier-free diffusion model pipeline for server-side data generation. In our experiments, OSCAR outperforms the state-of-the-art on four benchmark datasets while reducing the communication load by at least 99%.
💡 Research Summary
One‑Shot Federated Learning (OSFL) aims to build a global model with a single communication round, thereby eliminating the heavy communication overhead that plagues conventional federated learning (FL) when data are distributed across many clients. Existing OSFL approaches that rely on diffusion models (DMs) typically use classifier‑guided diffusion, which requires each client to train an auxiliary classifier on its private data and transmit the classifier parameters to the server. This extra training step adds computational cost on resource‑constrained devices and inflates the communication payload.
The paper introduces OSCAR (One‑Shot Federated Learning with Classifier‑Free Diffusion Models), a novel OSFL framework that completely removes the need for client‑side classifiers. OSCAR leverages large pre‑trained foundation models—specifically a vision‑language model (BLIP) for caption generation and the CLIP text encoder for embedding those captions— to produce category‑specific textual embeddings for each client’s local images. For a given class c, each client computes embeddings y_{c,n}=CLIP_{text}(BLIP(x_{c,n})) for all its N_c images, then averages them to obtain a compact representation \bar{y}c = (1/N_c) Σ_n y{c,n}. This averaging reduces the client upload to a few hundred floating‑point numbers per class, a reduction of more than 99 % compared with transmitting full classifier weights.
The server receives the set of averaged embeddings from all R clients and uses a pre‑trained classifier‑free diffusion model (Stable Diffusion) to synthesize data. In a classifier‑free setting, the reverse diffusion step combines the conditional score ε_θ(x_t, t, \bar{y}_c) with the unconditional score ε_θ(x_t, t, ∅) as ˆε_t = (1+s)·ε_θ(x_t, t, \bar{y}c) – s·ε_θ(x_t, t, ∅), where s (guidance scale) is fixed at 7.5 and the diffusion process runs for T=50 timesteps. For each class representation the server generates ten synthetic images, yielding a global synthetic dataset D{syn} of size 10·|R|·C. This dataset reflects the heterogeneous data distribution across clients because each class’s conditioning vector originates from a specific client’s local data.
With D_{syn} in hand, the server trains a centralized classifier—ResNet‑18 in the main experiments—on the synthetic images. After training, the global model is broadcast back to all clients for inference. No further client‑side training is required, and the entire learning pipeline completes after a single upload from each client.
The authors evaluate OSCAR on four benchmark datasets: NICO++ (both “Common” and “Unique” domain splits), a 90‑class subset of DomainNet, and a 120‑class subset of OpenImage. Data are partitioned among six clients in a non‑IID fashion, each client holding a single domain per class (or a single class per domain for OpenImage). Baselines include local training, traditional FL algorithms (FedAvg, FedProx, FedDyn), and two state‑of‑the‑art DM‑assisted OSFL methods (FedCADO and FedDISC). Accuracy is measured as top‑1 classification rate on the original test sets, both overall and per‑domain.
Results show that OSCAR consistently outperforms all baselines. On NICO++ Common and Unique, OSCAR improves top‑1 accuracy by 2–4 percentage points over FedCADO and FedDISC. Similar gains are observed on OpenImage. For DomainNet, OSCAR matches or exceeds the baselines on most domains, with a slight dip on the sketch and clipart domains where textual caption quality is lower. Importantly, the communication cost per client drops from millions of parameters (typical for classifier‑guided methods) to a few hundred numbers, achieving a >99 % reduction. The authors also test alternative backbones (EfficientNet‑B0, ViT‑Base) and find that the synthetic data generated by OSCAR can benefit stronger models, suggesting that the data quality is not limited to ResNet‑18.
Key contributions of the paper are: (1) a fully classifier‑free OSFL pipeline that eliminates client‑side classifier training; (2) the novel use of foundation models (BLIP, CLIP) to produce compact, semantically rich conditioning vectors for diffusion generation; (3) demonstration that a single communication round suffices to capture heterogeneous client distributions via synthetic data; and (4) empirical evidence of superior accuracy and massive communication savings across diverse vision benchmarks.
The paper also discusses limitations. Text caption generation may be less reliable for abstract visual domains (e.g., sketches), which can affect the quality of the conditioning embeddings and thus the generated images. The current implementation freezes the foundation and diffusion models; fine‑tuning them on domain‑specific data could further improve synthesis. Moreover, the number of synthetic samples per class (fixed at ten) and the guidance hyper‑parameters were not exhaustively optimized, leaving room for performance gains through dynamic sampling strategies.
Future work suggested includes: (a) adaptive prompt engineering to improve caption quality for challenging domains; (b) dynamic adjustment of guidance scale and diffusion timesteps based on embedding uncertainty; (c) integrating large language models to enrich textual conditioning; (d) applying differential privacy to the transmitted embeddings to protect any residual sensitive information; and (e) scaling the approach to larger numbers of clients and classes, possibly with hierarchical aggregation of embeddings.
In summary, OSCAR presents a compelling, privacy‑preserving, and communication‑efficient solution for one‑shot federated learning by marrying foundation models with classifier‑free diffusion. It achieves state‑of‑the‑art performance while slashing client upload size by orders of magnitude, opening a practical path for federated learning in bandwidth‑constrained or highly heterogeneous environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment