WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
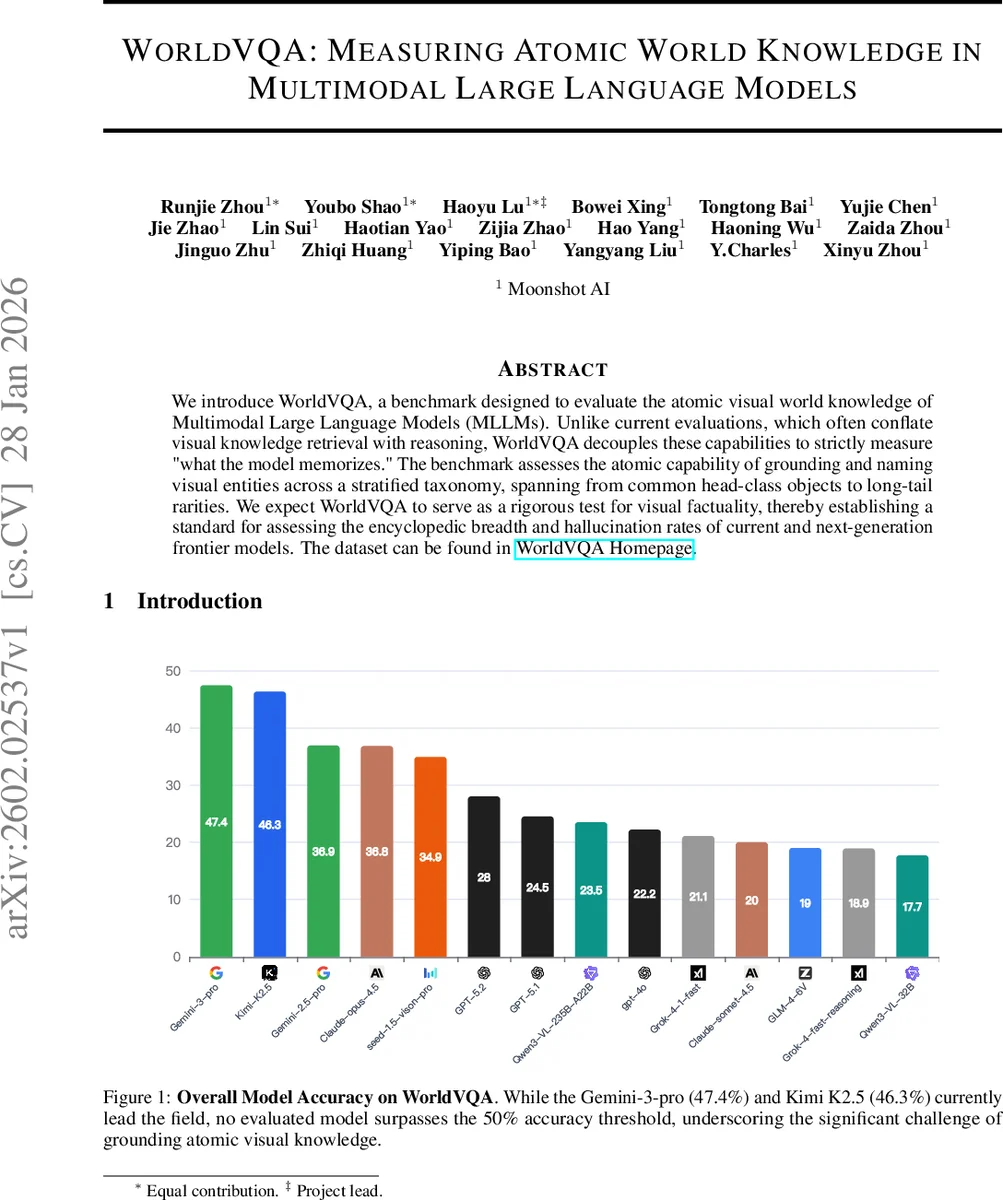
We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure “what the model memorizes.” The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
💡 Research Summary
WorldVQA introduces a novel benchmark specifically designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike existing visual‑question‑answering (VQA) datasets that intertwine visual perception with multi‑step reasoning, WorldVQA isolates the fundamental task of grounding and naming visual entities. By removing any reliance on OCR, arithmetic, or multi‑hop inference, each question requires a single‑hop answer that directly maps an image to its precise proper noun or taxonomic label.
The benchmark is organized around nine high‑level semantic categories—Nature & Environment, Locations & Architecture, Culture, Arts & Crafts, Objects & Products, Vehicles & Transportation, Entertainment, Media & Gaming, Brands & Logos, Sports & Gear, and Notable People. Within each category, the dataset balances “head‑class” high‑frequency concepts with long‑tail, low‑frequency entities, ensuring coverage of both common and obscure knowledge. A total of 3,500 image‑question‑answer (VQA) pairs are provided, split 64 % English and 36 % Chinese, and stratified into three difficulty tiers (Easy, Medium, Hard) based on performance of an ensemble of five frontier MLLMs.
Data collection follows a rigorous three‑stage pipeline. First, expert annotators compile seed entities and retrieve high‑quality, text‑free images from trusted web sources, adhering to strict visual reliability criteria (no watermarks, no overlay text, unambiguous visual cues). Second, a global balancing step caps region‑specific (Chinese) entities at 50 % per category and expands the set with additional worldwide entities using LLM‑in‑the‑loop searches. Third, visual duplication is eliminated by computing Instance‑level Semantic Content (ISC) embeddings and discarding any image with cosine similarity ≥ 0.95 to large public datasets such as LAION and Common Crawl; duplicate‑free images are then re‑collected from video screenshots to avoid pre‑training leakage.
Ground‑truth verification employs a dual‑gate mechanism. An automated audit uses few‑shot prompted Gemini‑3‑Pro to check visual clarity, semantic exclusivity, and contextual completeness for every triplet. Parallel human blind validation requires annotators, unaware of the gold label, to answer each question; any disagreement triggers manual review and removal. This two‑pronged approach guarantees high label fidelity and eliminates both semantic noise and visual ambiguity.
Evaluation metrics extend beyond raw accuracy. Correct Given Attempted (CGA) measures precision only on questions the model chooses to answer, thereby quantifying hallucination propensity when the model commits. The F‑score combines attempt rate and CGA into a harmonic mean, penalizing both over‑conservative refusals and overly aggressive guessing.
Experiments evaluate seven state‑of‑the‑art MLLMs (including Gemini‑3‑Pro, Kimi K2.5, GPT‑4V, etc.) under a unified prompting regime and identical inference settings. The best model, Gemini‑3‑Pro, achieves 47.4 % overall accuracy, with no model surpassing the 50 % threshold. Performance varies markedly across categories; the Nature and Culture domains exhibit the largest gaps compared to text‑only baselines, highlighting a deficiency in visual encyclopedic knowledge. Radar charts illustrate distinct “knowledge pits” where models consistently underperform, offering a diagnostic map for future research.
WorldVQA thus establishes a rigorous, high‑resolution probe of visual factuality and internal knowledge grounding in MLLMs. By decoupling perception from reasoning, it provides a clear signal of how well a model’s parameters encode a visual encyclopedia, enabling systematic tracking of hallucination rates and guiding the development of next‑generation multimodal systems that truly “see” and “know.”
Comments & Academic Discussion
Loading comments...
Leave a Comment