MADE: Benchmark Environments for Closed-Loop Materials Discovery
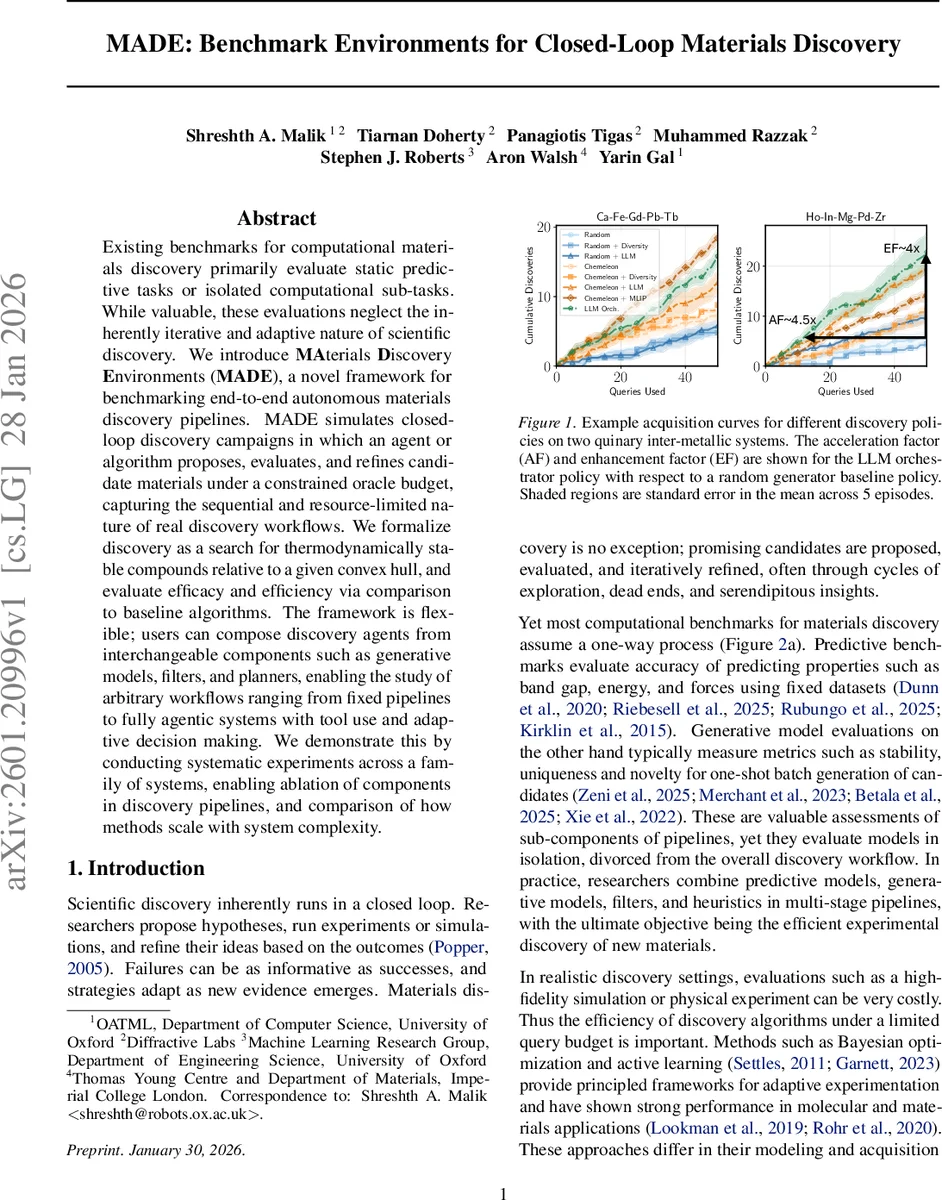
Existing benchmarks for computational materials discovery primarily evaluate static predictive tasks or isolated computational sub-tasks. While valuable, these evaluations neglect the inherently iterative and adaptive nature of scientific discovery. We introduce MAterials Discovery Environments (MADE), a novel framework for benchmarking end-to-end autonomous materials discovery pipelines. MADE simulates closed-loop discovery campaigns in which an agent or algorithm proposes, evaluates, and refines candidate materials under a constrained oracle budget, capturing the sequential and resource-limited nature of real discovery workflows. We formalize discovery as a search for thermodynamically stable compounds relative to a given convex hull, and evaluate efficacy and efficiency via comparison to baseline algorithms. The framework is flexible; users can compose discovery agents from interchangeable components such as generative models, filters, and planners, enabling the study of arbitrary workflows ranging from fixed pipelines to fully agentic systems with tool use and adaptive decision making. We demonstrate this by conducting systematic experiments across a family of systems, enabling ablation of components in discovery pipelines, and comparison of how methods scale with system complexity.
💡 Research Summary
The paper introduces MADE (Materials Discovery Environments), a benchmark framework designed to evaluate end‑to‑end autonomous materials discovery pipelines in a closed‑loop setting. Existing benchmarks in computational materials science typically focus on static prediction tasks (e.g., band‑gap regression) or one‑shot generative evaluations, ignoring the iterative hypothesis‑generation, experiment, and learning cycle that characterizes real scientific discovery. MADE fills this gap by simulating a sequential decision‑making process where an agent proposes candidate compounds, receives feedback from an oracle (formation energy per atom), updates its internal state, and repeats until a predefined query budget is exhausted.
Problem formulation
The search space S consists of all chemically valid compositions and crystal structures for a given system. An initial set H₀ of known materials (e.g., from the Materials Project) seeds the environment. At each iteration t ≤ B (budget), the policy π selects a new structure sₜ based on the history of (structure, energy) pairs observed so far. The oracle O returns the formation energy Eₜ = O(sₜ). After each query the convex hull of the accumulated set Hₜ is recomputed; any material whose energy above the hull Δ_hull(s, Hₜ) ≤ ε is deemed thermodynamically stable. The objective is to maximize the number of new stable materials discovered within B queries.
Metrics
MADE defines both absolute and relative performance measures. The absolute metric mSUN quantifies the fraction of proposals that are (i) stable, (ii) unique (no duplicate composition/structure), and (iii) novel relative to H₀. AUDC (Area Under the Discovery Curve) integrates the cumulative mSUN count over the budget, normalizing to a maximum of 1, thereby capturing both speed and total yield. Relative metrics compare any policy to a baseline (typically random search). Acceleration Factor (AF) measures how many fewer queries a policy needs to reach a fixed number k of discoveries, while Enhancement Factor (EF) measures the multiplicative gain in discoveries after a fixed number of queries. Additional extensible metrics (e.g., compositional diversity, structural diversity) can be added for multi‑objective studies.
Modular pipeline vs. agentic systems
MADE’s architecture is deliberately composable. A traditional pipeline is broken into four interchangeable modules:
- Planner – decides which compositions to explore (random, diversity‑driven, Bayesian optimization, LLM‑based).
- Generator – creates candidate crystal structures (AIRSS, diffusion models, mutation operators).
- Filter – discards chemically invalid or redundant candidates (SMACT, pymatgen StructureMatcher, geometric constraints).
- Selector – ranks the filtered set for final query (heuristics, surrogate MLIPs, LLM scoring).
An “agentic” system can replace the planner and selector with a large language model (LLM) that orchestrates the entire workflow, optionally invoking external tools (e.g., an MLIP) as needed. This design mirrors recent advances in LLM‑driven scientific agents that can plan, reason, and call APIs.
Experimental setup
The authors evaluate eight policies across five chemical systems of increasing complexity (binary oxides → quinary inter‑metallics) with a budget of B = 50 oracle calls per episode and ten episodes per configuration. Policies include:
- Random (baseline)
- Random + Diversity (adds a diversity‑biased planner)
- Random + LLM (LLM used only for selection)
- Chemeleon (LLM‑based planner + selector)
- Chemeleon + Diversity
- Chemeleon + LLM (LLM also guides composition choice)
- Chemeleon + MLIP (MLIP used as a surrogate selector)
- LLM Orchestrator (full end‑to‑end LLM control)
Performance is reported in terms of Discovery Performance (number of new stable compounds), Discovery Diversity (composition and structure diversity), and the three core metrics (AF, EF, AUDC).
Key findings
- Baseline vs. diversity – Adding a simple diversity‑driven planner yields modest gains (≈10 % higher mSUN, slight AF improvement).
- LLM impact – LLM‑enhanced policies (Chemeleon variants) dramatically outperform random baselines, especially in higher‑dimensional systems. AF values reach 4–6× and EF values 3–5×, indicating that LLMs can effectively prioritize promising regions of the combinatorial space.
- Surrogate MLIP – When an MLIP is used as a selector (Chemeleon + MLIP), discovery speed peaks (AF ≈ 19× in the hardest system), but this comes at the cost of additional computational overhead and reliance on the surrogate’s fidelity.
- Full LLM orchestration – The LLM Orchestrator, which plans, generates, filters, and selects using language‑model reasoning, achieves comparable AF/EF to the best Chemeleon + MLIP configuration while maintaining a simpler pipeline.
- Scalability – As chemical complexity grows, the advantage of adaptive/agentic methods widens, confirming the authors’ hypothesis that static pipelines become inefficient in large, discrete search spaces.
Contributions
- Introduction of MADE, the first benchmark that explicitly models closed‑loop materials discovery with budgeted oracle queries.
- Formalization of discovery‑centric metrics (mSUN, AUDC, AF, EF) that enable fair cross‑system comparisons.
- Comprehensive empirical study that ablates the contribution of each pipeline component and demonstrates the superiority of LLM‑driven and surrogate‑enhanced strategies in complex search spaces.
Implications and future work
MADE provides a shared testbed for the community to develop, compare, and improve autonomous discovery algorithms. Because the environment abstracts the oracle, researchers can later replace the fast MLIP with high‑fidelity DFT or even wet‑lab experiments, enabling a seamless transition from simulation to real‑world discovery campaigns. Future extensions could incorporate multi‑objective optimization (e.g., simultaneously targeting stability, conductivity, and toxicity), richer toolkits (e.g., quantum chemistry packages), and systematic studies of LLM prompt engineering and interpretability in scientific contexts.
In summary, MADE bridges a critical gap between isolated model evaluation and realistic, iterative materials discovery, showing that adaptive, agentic approaches—particularly those leveraging large language models and surrogate potentials—substantially accelerate the identification of novel stable compounds under realistic resource constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment