IOTA: Corrective Knowledge-Guided Prompt Learning via Black-White Box Framework
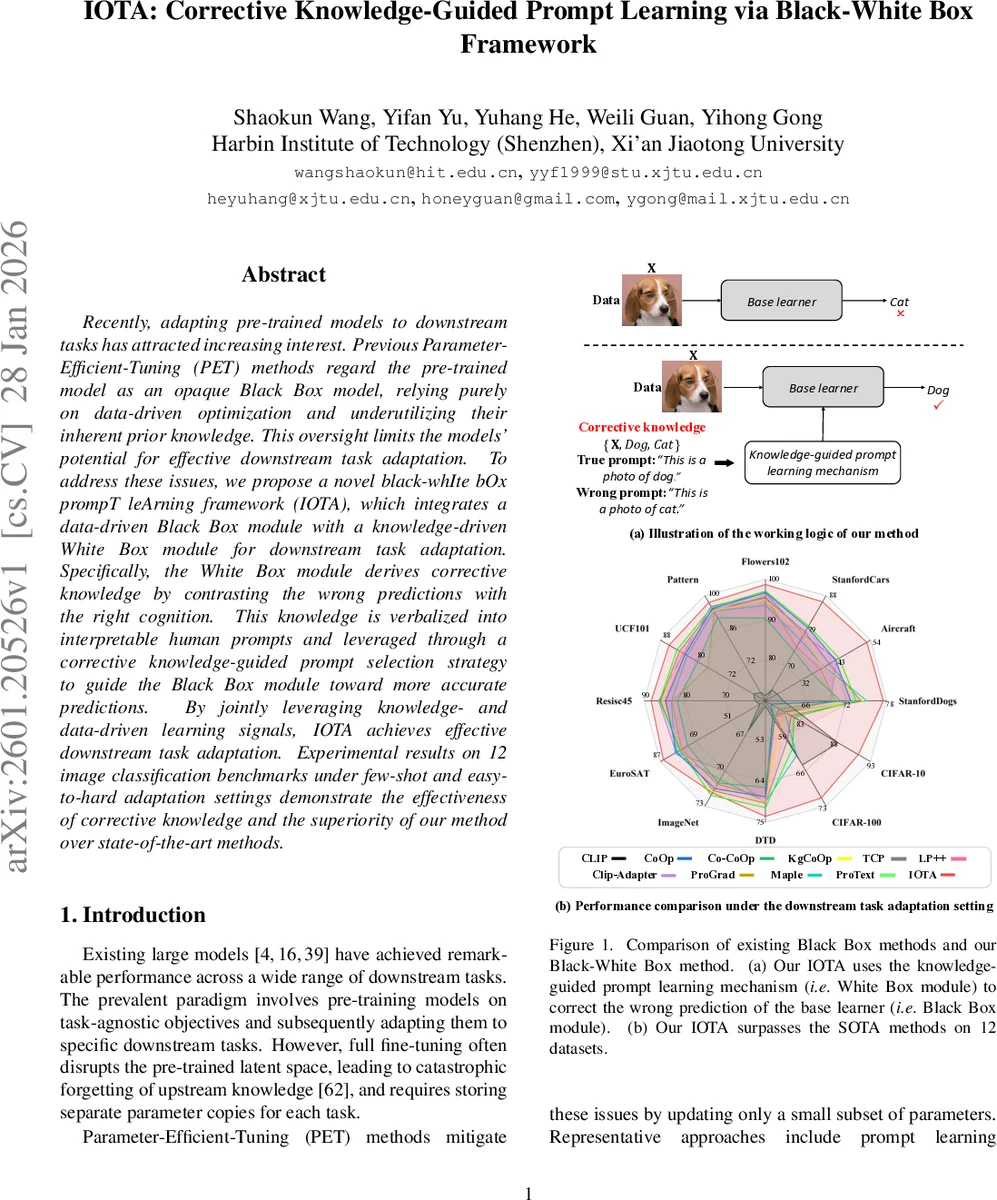
Recently, adapting pre-trained models to downstream tasks has attracted increasing interest. Previous Parameter-Efficient-Tuning (PET) methods regard the pre-trained model as an opaque Black Box model, relying purely on data-driven optimization and underutilizing their inherent prior knowledge. This oversight limits the models’ potential for effective downstream task adaptation. To address these issues, we propose a novel black-whIte bOx prompT leArning framework (IOTA), which integrates a data-driven Black Box module with a knowledge-driven White Box module for downstream task adaptation. Specifically, the White Box module derives corrective knowledge by contrasting the wrong predictions with the right cognition. This knowledge is verbalized into interpretable human prompts and leveraged through a corrective knowledge-guided prompt selection strategy to guide the Black Box module toward more accurate predictions. By jointly leveraging knowledge- and data-driven learning signals, IOTA achieves effective downstream task adaptation. Experimental results on 12 image classification benchmarks under few-shot and easy-to-hard adaptation settings demonstrate the effectiveness of corrective knowledge and the superiority of our method over state-of-the-art methods.
💡 Research Summary
The paper introduces IOTA, a novel framework that combines a data‑driven “Black Box” module with a knowledge‑driven “White Box” module to adapt large pre‑trained vision models to downstream classification tasks. The Black Box is a frozen Vision Transformer that provides stable image embeddings (the CLS token) without any parameter updates, preserving the rich upstream knowledge and avoiding catastrophic forgetting. The White Box extracts “corrective knowledge” by comparing the model’s prediction with the ground‑truth label for each sample, forming a triplet {X, A, B} where A is the true class and B is the predicted class. When A ≠ B, the method verbalizes this discrepancy into two natural‑language prompts: a true prompt (“This is a photo of a
Comments & Academic Discussion
Loading comments...
Leave a Comment