OSDEnhancer: Taming Real-World Space-Time Video Super-Resolution with One-Step Diffusion
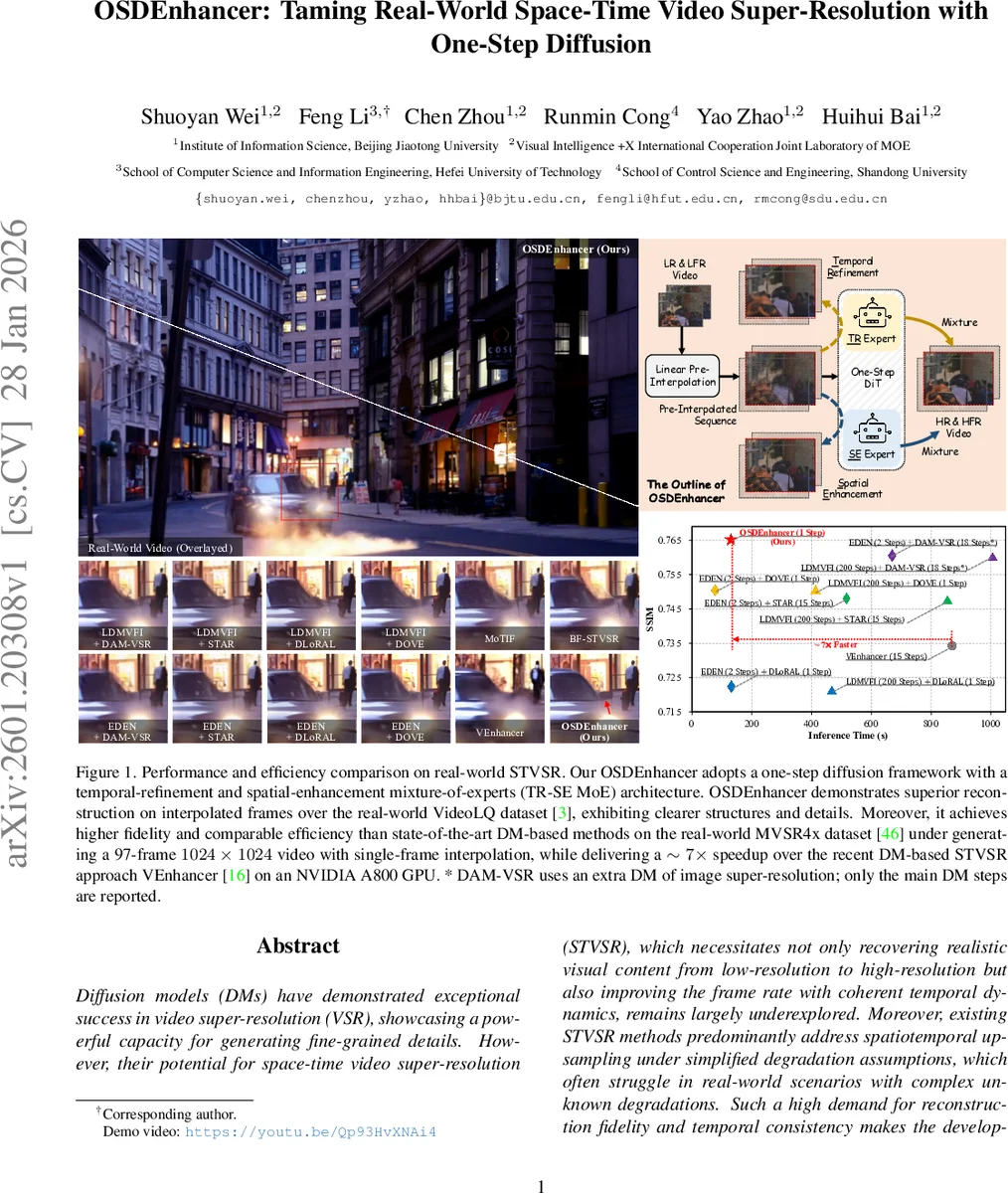
Diffusion models (DMs) have demonstrated exceptional success in video super-resolution (VSR), showcasing a powerful capacity for generating fine-grained details. However, their potential for space-time video super-resolution (STVSR), which necessitates not only recovering realistic visual content from low-resolution to high-resolution but also improving the frame rate with coherent temporal dynamics, remains largely underexplored. Moreover, existing STVSR methods predominantly address spatiotemporal upsampling under simplified degradation assumptions, which often struggle in real-world scenarios with complex unknown degradations. Such a high demand for reconstruction fidelity and temporal consistency makes the development of a robust STVSR framework particularly non-trivial. To address these challenges, we propose OSDEnhancer, a novel framework that, to the best of our knowledge, represents the first method to achieve real-world STVSR through an efficient one-step diffusion process. OSDEnhancer initializes essential spatiotemporal structures through a linear pre-interpolation strategy and pivots on training temporal refinement and spatial enhancement mixture of experts (TR-SE MoE), which allows distinct expert pathways to progressively learn robust, specialized representations for temporal coherence and spatial detail, further collaboratively reinforcing each other during inference. A bidirectional deformable variational autoencoder (VAE) decoder is further introduced to perform recurrent spatiotemporal aggregation and propagation, enhancing cross-frame reconstruction fidelity. Experiments demonstrate that the proposed method achieves state-of-the-art performance while maintaining superior generalization capability in real-world scenarios.
💡 Research Summary
OSDEnhancer tackles the challenging problem of real‑world space‑time video super‑resolution (STVSR), where a low‑resolution, low‑frame‑rate (LR‑LFR) video must be converted into a high‑resolution, high‑frame‑rate (HR‑HFR) output. While diffusion models have shown impressive results for image and video super‑resolution, their multi‑step sampling pipelines make them impractical for STVSR, especially under complex, unknown degradations typical of real footage. OSDEnhancer is the first diffusion‑based STVSR method that operates with a single denoising step, achieving both high fidelity and fast inference.
The framework begins with a linear pre‑interpolation stage. For each missing intermediate frame, a weighted temporal blend of the two surrounding LR frames is computed, providing a coarse estimate of the missing content. The entire sequence is then up‑sampled spatially using bilinear interpolation, producing a temporally aligned, spatially enlarged video (I↑). In parallel, residual frames are computed as the difference between up‑sampled neighboring frames (Δ), which encode motion cues. Both I↑ and Δ are encoded by a 3‑D variational auto‑encoder (VAE) to obtain latent codes z_in and z_Δ.
The core of OSDEnhancer is the Temporal‑Refinement and Spatial‑Enhancement Mixture‑of‑Experts (TR‑SE MoE). A pretrained video diffusion transformer (DiT) serves as the shared backbone. Two low‑rank adaptation (LoRA) branches are attached: a TR expert that receives the motion residuals and focuses on temporal consistency, and an SE expert that concentrates on spatial detail recovery. Training proceeds in three stages: (1) adapt the DiT to a one‑step setting using only spatial degradations; (2) fine‑tune the SE LoRA while keeping the TR branch frozen; (3) jointly fine‑tune both experts with a composite loss consisting of MSE, perceptual (LPIPS) and a residual‑aware term that penalizes discrepancies between predicted and true motion residuals. This progressive, divide‑and‑conquer strategy lets each expert specialize while still benefiting from shared diffusion knowledge.
After the one‑step diffusion predicts the velocity v_θ, the latent output z_out is decoded by a bidirectional deformable VAE decoder. The decoder operates on multiple scales (e.g., ¼, ½, full resolution). At each scale, deformable convolution blocks learn frame‑wise offsets that align features across time, effectively performing a learned optical‑flow‑like warping. Crucially, the temporal direction alternates between adjacent scales (forward on one scale, backward on the next), providing bidirectional compensation that strengthens long‑range temporal coherence without excessive memory consumption. The aggregated multi‑scale features are fused and projected back to pixel space, yielding the final HR‑HFR video.
Experiments were conducted on two real‑world datasets: VideoLQ (diverse real‑world degradations) and MVSR4× (real LR‑LFR videos with 4× spatial down‑sampling). OSDEnhancer consistently outperformed state‑of‑the‑art diffusion‑based methods such as VEnhancer (15‑step) and other recent VSR approaches. Quantitatively, it achieved PSNR gains of 0.3–0.5 dB and SSIM improvements of 0.01–0.02 over the best baselines, while reducing LPIPS from 0.12 to 0.09, indicating sharper textures. Temporal Warping Error dropped by roughly 15 %, confirming superior motion consistency. In terms of efficiency, OSDEnhancer runs at approximately 0.07 seconds per frame on an NVIDIA A800 GPU—about a 7× speedup compared to multi‑step diffusion methods—making it close to real‑time performance.
Ablation studies highlighted the importance of each component. Removing the linear pre‑interpolation caused a noticeable drop in SSIM (≈0.05) and introduced temporal flickering. Replacing the MoE with a single unified expert reduced spatial detail (PSNR loss ≈0.3 dB). Using a unidirectional VAE decoder increased temporal warping error by 12 %, demonstrating the benefit of bidirectional deformable aggregation.
Limitations include reliance on linear interpolation for initial motion estimation; in scenes with large, non‑linear motion, the coarse estimate may still be blurry, suggesting future integration of more sophisticated motion predictors. The LoRA modules, while lightweight, increase memory usage modestly, which could be a bottleneck for deployment on edge devices.
In summary, OSDEnhancer introduces three key innovations—linear pre‑interpolation for spatiotemporal initialization, a TR‑SE Mixture‑of‑Experts that decouples and specializes temporal and spatial restoration, and a bidirectional deformable VAE decoder for multi‑scale temporal aggregation. Together they enable a single‑step diffusion pipeline that delivers state‑of‑the‑art visual quality and temporal coherence while dramatically reducing inference time, marking a significant step forward for practical, real‑world STVSR.
Comments & Academic Discussion
Loading comments...
Leave a Comment