X-SAM: From Segment Anything to Any Segmentation
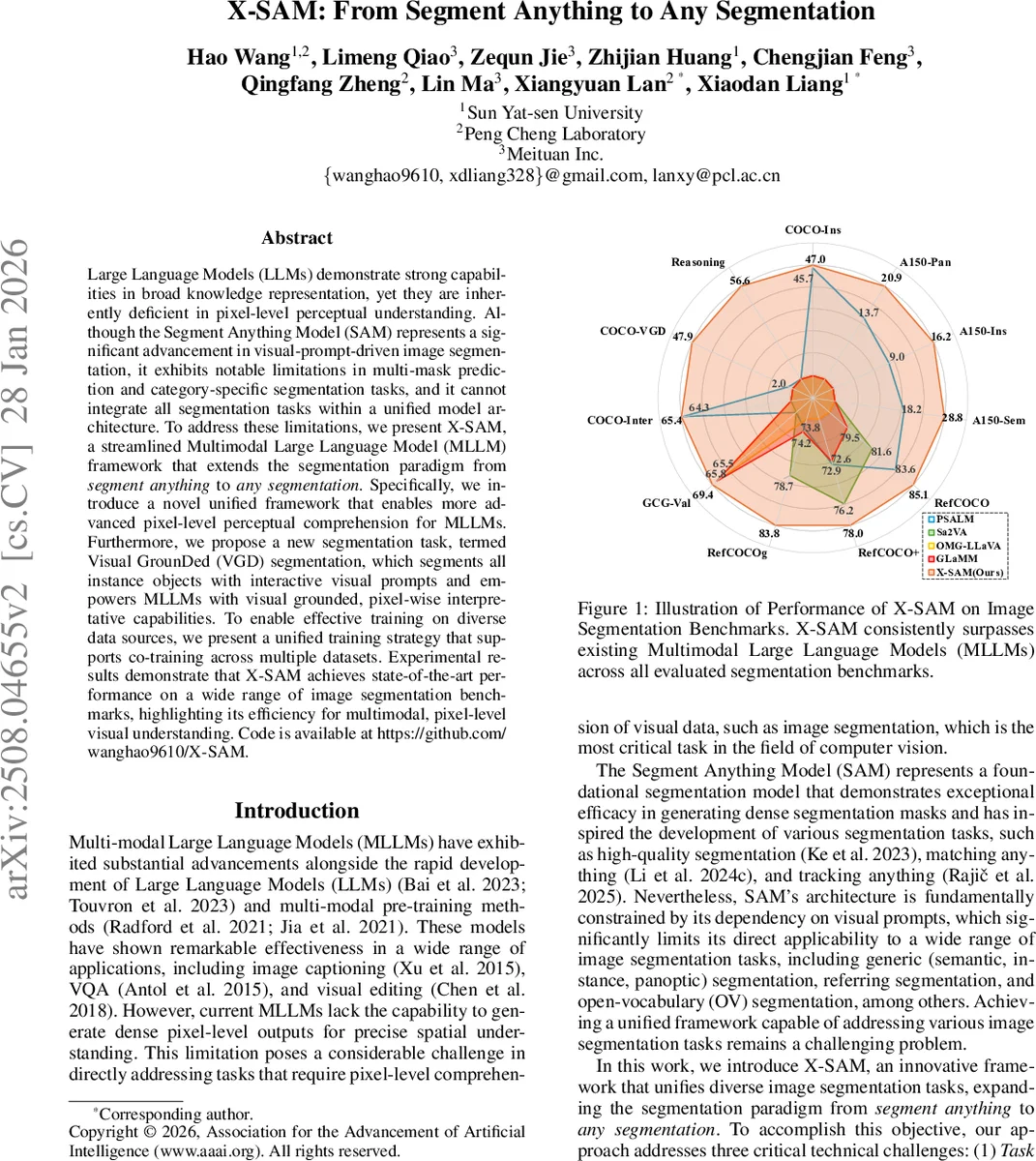
Large Language Models (LLMs) demonstrate strong capabilities in broad knowledge representation, yet they are inherently deficient in pixel-level perceptual understanding. Although the Segment Anything Model (SAM) represents a significant advancement in visual-prompt-driven image segmentation, it exhibits notable limitations in multi-mask prediction and category-specific segmentation tasks, and it cannot integrate all segmentation tasks within a unified model architecture. To address these limitations, we present X-SAM, a streamlined Multimodal Large Language Model (MLLM) framework that extends the segmentation paradigm from \textit{segment anything} to \textit{any segmentation}. Specifically, we introduce a novel unified framework that enables more advanced pixel-level perceptual comprehension for MLLMs. Furthermore, we propose a new segmentation task, termed Visual GrounDed (VGD) segmentation, which segments all instance objects with interactive visual prompts and empowers MLLMs with visual grounded, pixel-wise interpretative capabilities. To enable effective training on diverse data sources, we present a unified training strategy that supports co-training across multiple datasets. Experimental results demonstrate that X-SAM achieves state-of-the-art performance on a wide range of image segmentation benchmarks, highlighting its efficiency for multimodal, pixel-level visual understanding. Code is available at https://github.com/wanghao9610/X-SAM.
💡 Research Summary
X‑SAM proposes a unified multimodal large language model (MLLM) that extends the capabilities of the Segment Anything Model (SAM) from “segment anything” to “any segmentation”. The authors identify three core limitations of SAM: inability to handle multi‑mask and category‑specific tasks, lack of integration across diverse segmentation paradigms, and dependence on visual prompts alone. To overcome these, X‑SAM introduces a comprehensive framework that can process both textual and visual queries, enabling generic, instance, panoptic, referring, open‑vocabulary, reasoning, and a newly defined Visual Grounded (VGD) segmentation task.
The architecture consists of dual encoders (a SigLIP‑based image encoder for global features and a SAM‑L segmentation encoder for fine‑grained mask features), dual projectors that align the feature dimensions, a large language model, a segmentation connector, and a segmentation decoder. Input is unified into a single token sequence: textual prompts are wrapped with special <p> and </p> tokens, while visual prompts (points, scribbles, boxes) are represented by a <region> token. The model also introduces a <SEG> token in the output vocabulary to indicate where a mask should be generated. During inference, the LLM consumes the combined token stream, and the segmentation decoder uses the embeddings between <p> and </p> (or the region embedding) as conditioning signals to produce pixel‑wise masks.
The VGD task requires the model to segment all instances in an image based on interactive visual prompts, and it can operate across multiple images with a single prompt set. This task bridges the gap between purely visual prompting (as in SAM) and language‑guided segmentation, providing a more natural, user‑friendly interface.
Training is performed via a unified multi‑stage co‑training strategy. The authors combine over twenty segmentation datasets—including COCO‑Stuff, ADE20K, RefCOCO/RefCOCO+, and a custom VGD dataset—into a common format. Losses for mask prediction (Dice, BCE) and language generation are jointly optimized, allowing a single set of parameters to handle all tasks without task‑specific fine‑tuning.
Empirical results show that X‑SAM achieves state‑of‑the‑art performance across all evaluated benchmarks. For VGD it reaches 85.1 % mIoU, surpassing prior interactive segmentation methods. In generic, instance, and panoptic segmentation it also outperforms strong baselines such as Mask2Former, SEEM, and other MLLM‑based approaches, while maintaining comparable inference speed and model size (7–13 B parameters). The unified framework demonstrates that a single MLLM can serve as a universal segmentation engine.
Limitations include dependence on the quality of visual prompts (noisy points degrade mask quality), the computational cost of large LLMs, and ambiguous behavior when textual and visual cues conflict. Future work is suggested on prompt refinement, efficient LLM distillation, and mechanisms for multimodal consistency.
In summary, X‑SAM presents a novel, unified architecture that brings dense pixel‑level understanding to large language models, introduces the VGD segmentation paradigm, and sets a new baseline for “any segmentation” in a single, end‑to‑end trainable model.
Comments & Academic Discussion
Loading comments...
Leave a Comment