Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning
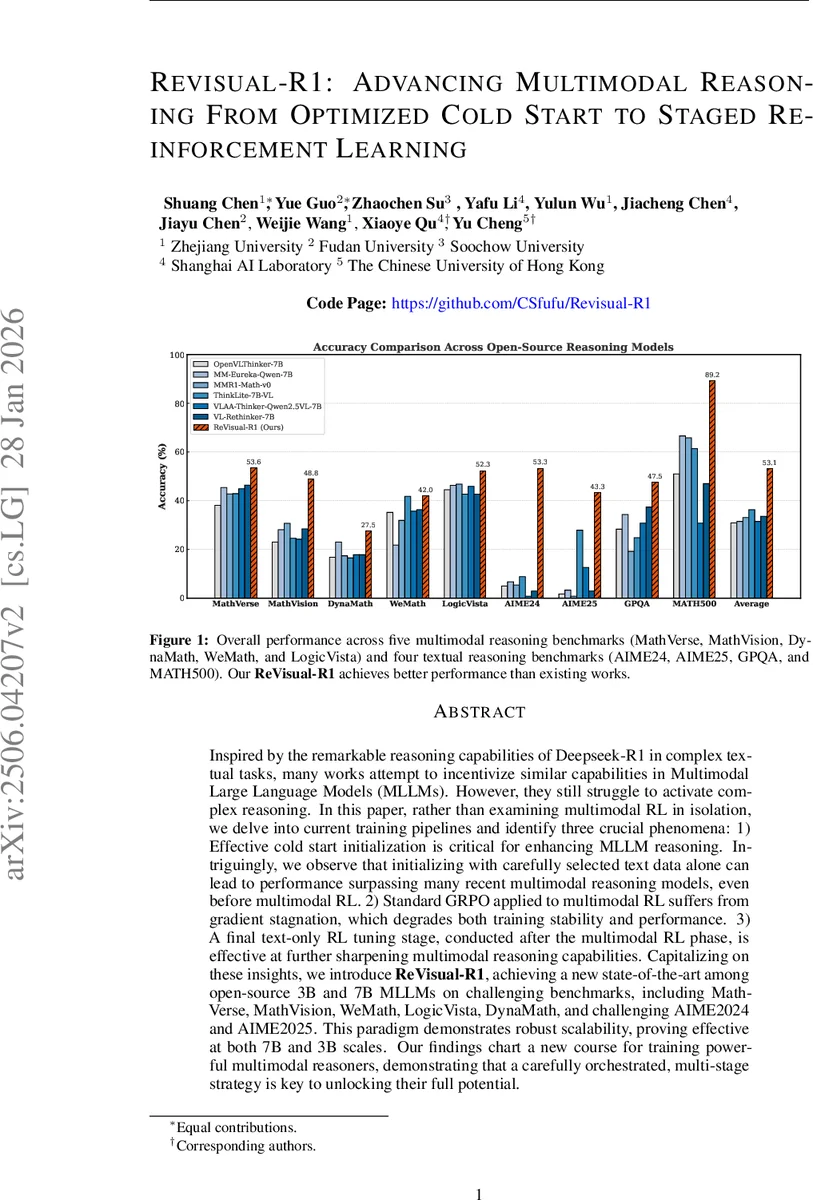
Inspired by the remarkable reasoning capabilities of Deepseek-R1 in complex textual tasks, many works attempt to incentivize similar capabilities in Multimodal Large Language Models (MLLMs) by directly applying reinforcement learning (RL). However, they still struggle to activate complex reasoning. In this paper, rather than examining multimodal RL in isolation, we delve into current training pipelines and identify three crucial phenomena: 1) Effective cold start initialization is critical for enhancing MLLM reasoning. Intriguingly, we find that initializing with carefully selected text data alone can lead to performance surpassing many recent multimodal reasoning models, even before multimodal RL. 2) Standard GRPO applied to multimodal RL suffers from gradient stagnation, which degrades training stability and performance. 3) Subsequent text-only RL training, following the multimodal RL phase, further enhances multimodal reasoning. This staged training approach effectively balances perceptual grounding and cognitive reasoning development. By incorporating the above insights and addressing multimodal RL issues, we introduce ReVisual-R1, achieving a new state-of-the-art among open-source 7B MLLMs on challenging benchmarks including MathVerse, MathVision, WeMath, LogicVista, DynaMath, and challenging AIME2024 and AIME2025.
💡 Research Summary
The paper tackles the persistent difficulty of endowing Multimodal Large Language Models (MLLMs) with deep reasoning capabilities comparable to those achieved by text‑only models such as DeepSeek‑R1 through reinforcement learning (RL). By dissecting the full training pipeline, the authors identify three critical shortcomings that have limited prior attempts: (1) inadequate cold‑start initialization, (2) gradient stagnation in the commonly used Group Relative Policy Optimization (GRPO) algorithm, and (3) the lack of a post‑RL polishing stage that reinforces language reasoning without eroding visual grounding.
First, the authors demonstrate that a cold‑start phase built exclusively from high‑difficulty textual reasoning data (e.g., DeepMath, OpenR1‑Math) dramatically improves the model’s internal chain‑of‑thought and self‑reflective abilities. Experiments show that even before any multimodal RL, a model fine‑tuned on such text‑only data outperforms models that were cold‑started on multimodal image‑text pairs, achieving absolute gains of 5–12 percentage points across multimodal benchmarks. This finding suggests that the complexity of the reasoning patterns, not the modality of the data, is the key driver for initializing a strong reasoning engine.
Second, the paper uncovers a “gradient stagnation” problem inherent to GRPO when applied to multimodal tasks with sparse binary rewards. Because GRPO computes a relative advantage within each group, if all samples in a group receive the same reward (all correct or all incorrect), the advantage collapses to near zero, yielding vanishing policy gradients and halting learning. To remedy this, the authors propose Prioritized Advantage Distillation (PAD). PAD first computes the absolute advantage for each generated sequence, filters out samples whose advantage magnitude falls below a threshold, and then re‑weights the remaining high‑signal samples before applying the GRPO update. This selective focus restores gradient flow, stabilizes training, and yields a 3–7 % absolute improvement on the multimodal RL stage.
Third, after the multimodal RL phase, the authors introduce a text‑only RL fine‑tuning stage. This “polishing” step refines the model’s linguistic expression and logical consistency while preserving the visual grounding learned earlier. Empirically, adding this stage further boosts performance on high‑stakes math competitions such as AIME 2024/2025, GPQA, and Math‑500, bringing the 7‑billion‑parameter ReVisual‑R1 to state‑of‑the‑art results that rival or surpass larger proprietary models.
To support the new curriculum, the authors curate a large, high‑quality dataset named GRAMMAR. GRAMMAR contains 283 K diverse textual reasoning examples for the cold‑start phase and an additional 31 K textual plus 21 K multimodal examples annotated with verifiable ground truth for RL. Data curation involves multi‑stage filtering, difficulty grading using larger LLMs (Qwen2.5‑VL‑32B), embedding‑based clustering (NV‑Embedding‑V2 + HDBSCAN), and balanced sampling across topics and difficulty levels.
The complete training pipeline—(1) text‑centric cold‑start, (2) PAD‑enhanced GRPO multimodal RL, (3) text‑only RL—constitutes the Staged Reinforcement Optimization (SRO) framework. Implemented on a 7 B parameter backbone (Qwen2.5‑VL‑7B‑Instruct), the resulting ReVisual‑R1 achieves the highest reported accuracies on five multimodal reasoning benchmarks (MathVerse, MathVision, WeMath, LogicVista, DynaMath) and four textual reasoning benchmarks (AIME 2024/25, GPQA, Math‑500). The approach also scales down to a 3 B model with comparable relative gains, indicating robustness to model size.
In summary, the paper makes three substantive contributions: (i) it highlights the overlooked importance of high‑difficulty textual data for cold‑start reasoning in MLLMs; (ii) it diagnoses and resolves gradient stagnation in GRPO via PAD; and (iii) it proposes a three‑stage SRO curriculum that synergistically combines visual grounding and language reasoning. The resulting open‑source ReVisual‑R1 sets a new performance baseline for multimodal reasoning and provides a clear roadmap for future research in multimodal AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment