Byte Pair Encoding for Efficient Time Series Forecasting
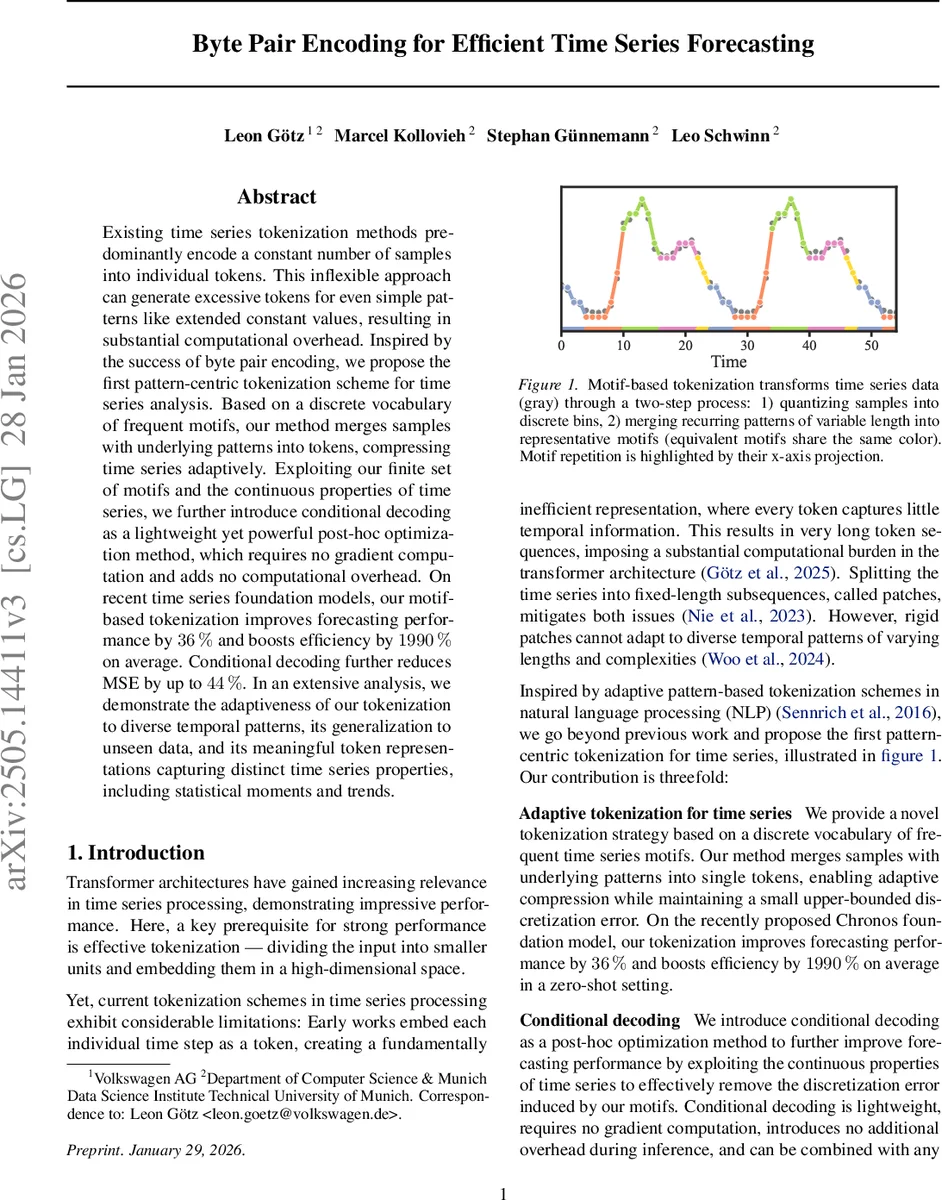
Existing time series tokenization methods predominantly encode a constant number of samples into individual tokens. This inflexible approach can generate excessive tokens for even simple patterns like extended constant values, resulting in substantial computational overhead. Inspired by the success of byte pair encoding, we propose the first pattern-centric tokenization scheme for time series analysis. Based on a discrete vocabulary of frequent motifs, our method merges samples with underlying patterns into tokens, compressing time series adaptively. Exploiting our finite set of motifs and the continuous properties of time series, we further introduce conditional decoding as a lightweight yet powerful post-hoc optimization method, which requires no gradient computation and adds no computational overhead. On recent time series foundation models, our motif-based tokenization improves forecasting performance by 36% and boosts efficiency by 1990% on average. Conditional decoding further reduces MSE by up to 44%. In an extensive analysis, we demonstrate the adaptiveness of our tokenization to diverse temporal patterns, its generalization to unseen data, and its meaningful token representations capturing distinct time series properties, including statistical moments and trends.
💡 Research Summary
The paper addresses a fundamental bottleneck in modern time‑series forecasting models: the tokenization strategy. Existing approaches either assign a token to each individual sample or split the series into fixed‑length patches. Both methods produce excessively long token sequences for long series and cannot adapt to the diverse temporal patterns that naturally occur in real‑world data. Inspired by byte‑pair encoding (BPE) from natural‑language processing, the authors propose a pattern‑centric tokenization pipeline that first quantizes raw values into a discrete alphabet and then iteratively merges the most frequent adjacent symbols into “motifs”. These motifs constitute a vocabulary of variable‑length tokens that directly capture recurring patterns such as trends, seasonality, or abrupt changes.
The quantization step uses M equiprobable bins (uniform, Gaussian, or data‑driven) and provides an analytically bounded maximum error δmax. The motif extraction proceeds by repeatedly finding the most frequent symbol pair in the quantized corpus, assigning it a new token ID, and adding it to the vocabulary Ψ until the frequency of new tokens falls below a user‑defined threshold pmin. This process yields a compact vocabulary (≈1.3–2.4 k tokens) and compression ratios ranging from 2.08 to 4.06, while preserving enough occurrences of each motif for effective learning.
To mitigate the discretization loss inherent in any quantization‑based scheme, the authors introduce conditional decoding. Assuming a first‑order Markov dependency, they compute optimal real‑valued reconstructions ω̂j,k for each symbol j conditioned on its predecessor k by averaging the corresponding raw samples in the training set. This yields a lightweight, gradient‑free post‑processing step that adds only M² parameters and incurs no extra inference cost.
The methodology is evaluated on the Chronos foundation model, a large‑scale transformer trained on 11 M time series (≈11 B samples). Three tokenizers with low, medium, and high compression settings are built from 100 k randomly selected series. Zero‑shot forecasting performance is measured on five benchmark datasets (ETTh1, ETTm1, Weather, Electricity, Traffic) and compared against the original sample‑based tokenizer and a patch‑based baseline (non‑overlapping patches of length 4 and 8). Results show that motif‑based tokenization improves mean squared error (MSE) by an average of 36 % and reduces computational load by roughly 1990 % (due to shorter token sequences). When conditional decoding is applied on top of the high‑compression tokenizer, MSE drops an additional 44 %.
Key contributions include: (1) a data‑driven, adaptive tokenization that captures intrinsic temporal motifs; (2) substantial reductions in sequence length and memory footprint, enabling longer context windows for transformer models; (3) a novel conditional decoding scheme that analytically corrects quantization error without extra training; (4) extensive empirical validation demonstrating superior zero‑shot performance across diverse time‑series domains.
Limitations are acknowledged: building the motif vocabulary requires a full pass over a large corpus, which may be costly for continuously evolving streams; rare patterns below the pmin threshold remain unrepresented; and the current conditional decoding relies on a first‑order Markov assumption, which may be insufficient for multivariate series with complex dependencies. Future work could explore dynamic vocabulary updates, multivariate motif extraction, higher‑order conditional decoding (e.g., neural decoders), and real‑time deployment scenarios. Overall, the paper presents a compelling, practically viable approach to make time‑series transformers more efficient and accurate by rethinking how raw data are tokenized.
Comments & Academic Discussion
Loading comments...
Leave a Comment