Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
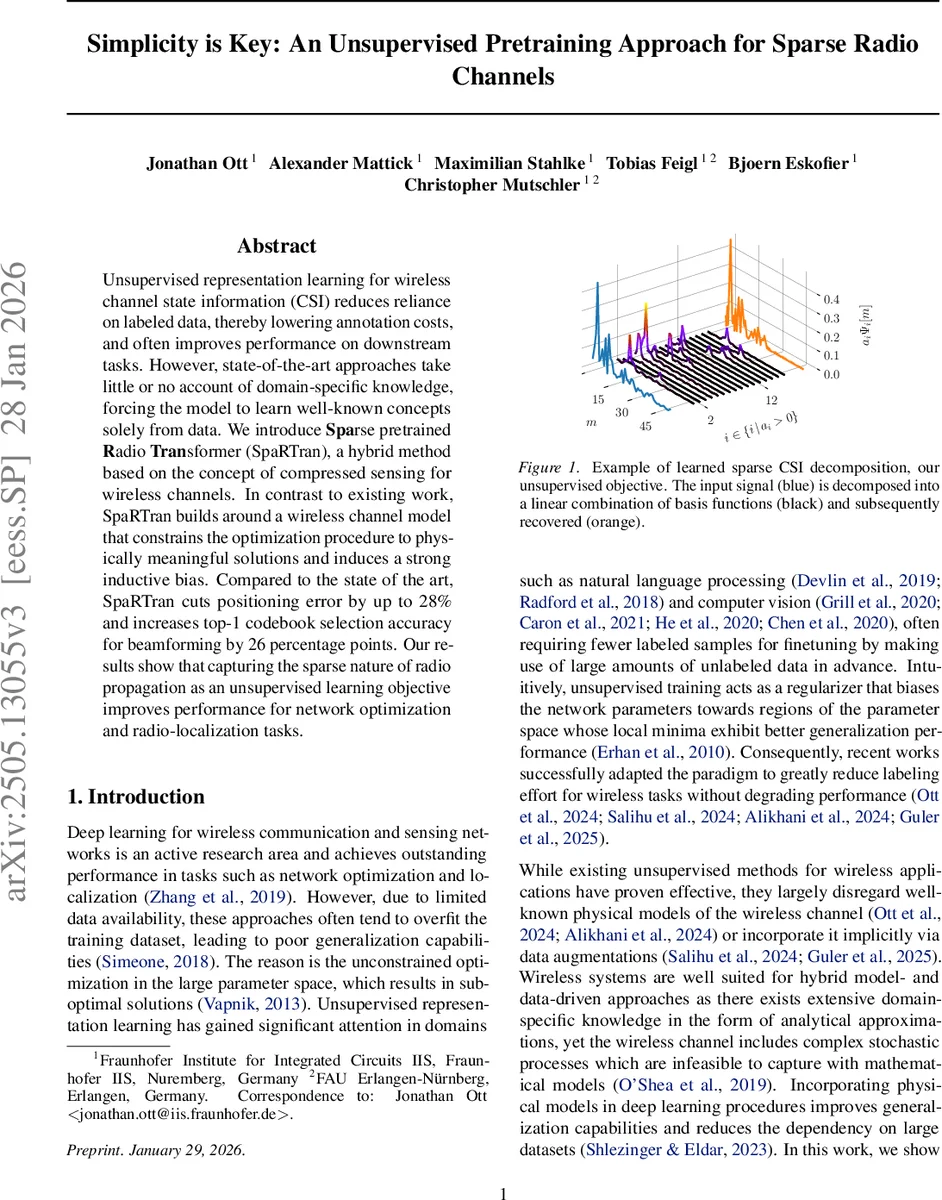
Unsupervised representation learning for wireless channel state information (CSI)reduces reliance on labeled data, thereby lowering annotation costs, and often improves performance on downstream tasks. However, state-of-the-art approaches take little or no account of domain-specific knowledge, forcing the model to learn well-known concepts solely from data. We introduce Sparse pretrained Radio Transformer (SpaRTran), a hybrid method based on the concept of compressed sensing for wireless channels. In contrast to existing work, SpaRTran builds around a wireless channel model that constrains the optimization procedure to physically meaningful solutions and induces a strong inductive bias. Compared to the state of the art, SpaRTran cuts positioning error by up to 28% and increases top-1 codebook selection accuracy for beamforming by 26 percentage points. Our results show that capturing the sparse nature of radio propagation as an unsupervised learning objective improves performance for network optimization and radio-localization tasks.
💡 Research Summary
This paper introduces SpaRTran, a novel unsupervised pre‑training framework for wireless channel state information (CSI) that explicitly exploits the inherent sparsity of radio propagation. Starting from the physical model of a multipath channel, the authors express the discrete‑time channel impulse response as a linear combination of a large over‑complete dictionary Ψ and a sparse coefficient vector a. The sparsity assumption (only a few active paths) leads to a compressed‑sensing formulation: recover a by minimizing the ℓ0 norm under an ℓ2 reconstruction constraint.
To embed this model into deep learning, SpaRTran uses a lightweight, single‑layer Transformer encoder (512‑dimensional latent space, 8 attention heads) that processes non‑overlapping patches of three consecutive CIR samples (9‑dimensional tokens). The encoder outputs a latent vector z, which is fed to a “sparse reconstruction head”. This head contains three sub‑modules: (i) f_gate, a binary gating network that selects which dictionary atoms are active; (ii) f_coeff, which predicts the magnitude of the selected coefficients; and (iii) f_phase, which predicts the phase of each complex coefficient. By separating atom selection from magnitude estimation, the method approximates an ℓ0 penalty more faithfully than the usual ℓ1 relaxation. The final complex coefficients are assembled as (\hat a = \hat x , e^{-i, f_{\text{phase}}(z)}).
The loss function combines three terms: a reconstruction loss (| \tilde h - \Psi \hat a|2^2), an ℓ1 sparsity penalty on the binary gate output, and an auxiliary loss that reconstructs the signal using the pre‑gating values (\rho{\text{gate}}) with a frozen dictionary. This auxiliary term forces the gating network to learn meaningful atom selections despite the non‑differentiable binarization. Leaky ReLU activations replace standard ReLU to avoid dead‑neuron issues in the gating and coefficient pathways.
Two dictionary strategies are supported. When system bandwidth and sampling rate are known, a fixed dictionary of shifted sinc functions can be constructed analytically. When such parameters are unknown or when training on heterogeneous crowd‑sourced data, the dictionary is treated as a set of learnable parameters (\hat \Psi), normalized to unit norm, and jointly optimized with the rest of the network. The authors acknowledge that learning an unrestricted dictionary makes the underlying optimization NP‑hard and reduces the model‑driven regularization effect.
During fine‑tuning, representations for each individual Tx‑Rx link are concatenated to form a global CSI vector. A 1‑D ResNet‑style head (multiple residual blocks with increasing channel width and receptive field, global average pooling, and a final fully connected layer) maps the concatenated latent features to task‑specific outputs such as position coordinates or beam‑codebook indices. This design preserves the link‑level sparsity learned during pre‑training while allowing downstream tasks to exploit inter‑link correlations.
Experimental evaluation on realistic positioning and beam‑management benchmarks shows that SpaRTran reduces average positioning error by up to 28 % and improves top‑1 beam‑codebook selection accuracy by 26 percentage points compared with state‑of‑the‑art self‑supervised methods. Notably, the approach is system‑agnostic: it operates on single‑link inputs, making the learned representations independent of antenna count or array geometry. The single‑layer Transformer also keeps computational overhead low, supporting real‑time deployment.
In summary, the paper’s key contributions are: (1) a physics‑informed inductive bias that integrates compressed‑sensing theory into the architecture and loss; (2) a novel sparse reconstruction head that approximates ℓ0 sparsity via gating and phase generation; (3) flexibility between fixed analytical and learnable dictionaries; and (4) demonstration that such hybrid model‑and‑data learning dramatically improves downstream wireless tasks while requiring far fewer labeled samples. SpaRTran thus establishes a compelling blueprint for future foundation models in wireless communications that respect the underlying signal physics.
Comments & Academic Discussion
Loading comments...
Leave a Comment