On the Effectiveness of LLM-Specific Fine-Tuning for Detecting AI-Generated Text
The rapid progress of large language models has enabled the generation of text that closely resembles human writing, creating challenges for authenticity verification in education, publishing, and digital security. Detecting AI-generated text has therefore become a crucial technical and ethical issue. This paper presents a comprehensive study of AI-generated text detection based on large-scale corpora and novel training strategies. We introduce a 1-billion-token corpus of human-authored texts spanning multiple genres and a 1.9-billion-token corpus of AI-generated texts produced by prompting a variety of LLMs across diverse domains. Using these resources, we develop and evaluate numerous detection models and propose two novel training paradigms: Per LLM and Per LLM family fine-tuning. Across a 100-million-token benchmark covering 21 large language models, our best fine-tuned detector achieves up to $99.6%$ token-level accuracy, substantially outperforming existing open-source baselines.
💡 Research Summary
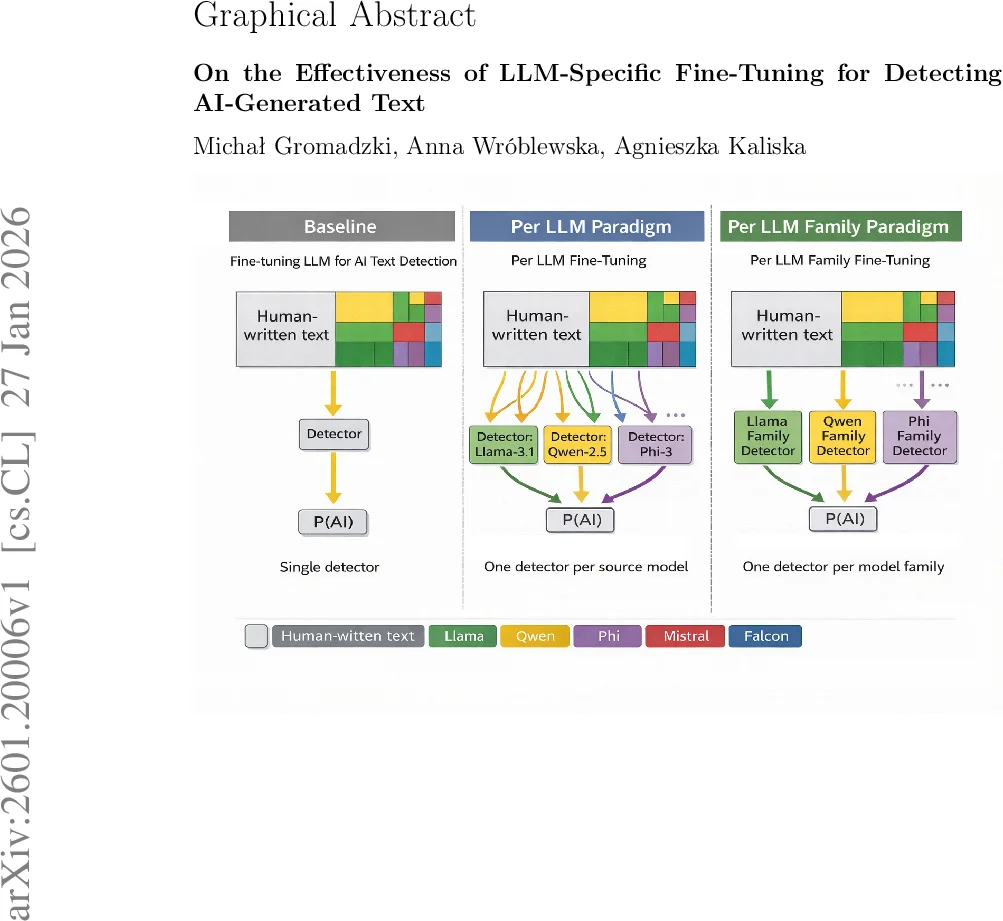
The paper addresses the growing need for reliable detection of AI‑generated text as large language models (LLMs) become capable of producing output that is virtually indistinguishable from human writing. The authors make four major contributions: (1) they assemble a 1‑trillion‑token corpus of human‑authored texts covering a wide variety of genres (blogs, essays, news articles, online discussions, creative writing, etc.); (2) they design a scalable pipeline to generate 1.9‑trillion‑token AI‑generated texts by prompting 21 distinct LLMs (including OpenAI GPT‑4, Meta Llama‑3/4, Microsoft Phi‑3/4, Mistral, Alibaba Qwen, among others) with four different sampling configurations (deterministic, balanced, creative, highly creative); (3) they introduce two novel fine‑tuning paradigms for detection: “Per LLM” (a separate detector trained on the outputs of each individual model) and “Per LLM Family” (a single detector trained on the combined outputs of models belonging to the same organization or family); and (4) they evaluate these detectors on a 100‑million‑token benchmark that spans all 21 LLMs, reporting token‑level accuracies up to 99.6 %.
Data Construction
Human data were drawn from ten publicly available datasets, cleaned for length, deduplicated, and aggregated into a unified corpus of roughly 1 trillion tokens. For AI‑generated data, each human sample was turned into a prompt using a three‑message template (system instruction, task description, and response starter). The prompt was fed to each LLM, and one of four preset sampling parameter sets (temperature, top‑p, top‑k) was randomly assigned per batch to increase stylistic diversity. After generation, a post‑processing step removed excessive whitespace, duplicated phrases, and other artefacts, especially from lower‑capacity models run at high temperature. The resulting AI corpus totals 1.9 trillion tokens, evenly distributed across the 21 models.
Experimental Datasets
From the full corpus, the authors extracted samples ≤ 8192 tokens, then applied token‑balanced sampling to create binary classification datasets (human vs. AI) that preserve the original genre and model distribution. The validation split contains roughly 30 % of the training tokens, ensuring that each genre and model family is proportionally represented.
Detection Models and Fine‑Tuning Strategies
All detectors are based on a RoBERTa‑large transformer classifier. In the “Per LLM” approach, a distinct model is fine‑tuned on the outputs of a single LLM, allowing it to capture model‑specific statistical signatures (e.g., token‑frequency quirks, repetition patterns). In the “Per LLM Family” approach, the outputs of all models belonging to the same organization (e.g., all Meta Llama variants) are merged, and a single detector is fine‑tuned on this combined set. This reduces the total number of detectors while still leveraging family‑level regularities. Training used AdamW, a learning rate of 2e‑5, batch size 64, and three epochs. Evaluation metrics include token‑level accuracy and document‑level F1.
Results
- Per LLM detectors achieve token‑level accuracies ranging from 99.2 % to 99.6 % across the 21 models.
- Per LLM Family detectors achieve a slightly lower but still impressive 98.7 % average accuracy, demonstrating strong cross‑model generalization within families.
- Both approaches substantially outperform open‑source baselines such as DetectGPT and Fast‑DetectGPT, which lag by 7–12 percentage points on the same benchmark.
- Performance remains stable across genres (short tweets, long news articles, Reddit comments) and is robust to the four sampling configurations, indicating that the detectors are not over‑fitted to a single generation style.
- Error analysis reveals that high‑temperature generations from smaller models sometimes contain repetitive or whitespace‑heavy artefacts that survive post‑processing and cause false negatives. Conversely, some human texts that are highly formal or template‑like can be mistakenly flagged as AI‑generated.
Limitations and Future Work
The study relies on a fixed prompt template that enforces a one‑to‑one mapping between human samples and generated counterparts; extending the approach to truly free‑form inputs will require additional research. The detectors are trained on a static set of 21 LLMs; as new models emerge, continual fine‑tuning or meta‑learning strategies will be needed. While token‑level accuracy is high, practical deployment will likely demand document‑level confidence scores and user‑friendly interfaces. Finally, the authors acknowledge the arms‑race nature of detection versus adversarial evasion (paraphrasing, translation, style transfer) and suggest that future work should integrate robustness testing and possibly watermarking techniques.
Conclusion
By constructing unprecedentedly large, balanced corpora of human and AI‑generated text and by demonstrating that model‑specific and family‑specific fine‑tuning dramatically improve detection performance, the paper provides a solid empirical foundation for next‑generation AI‑text detectors. The public release of the datasets and code further encourages reproducibility and rapid adoption in both academic and industry settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment