DART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
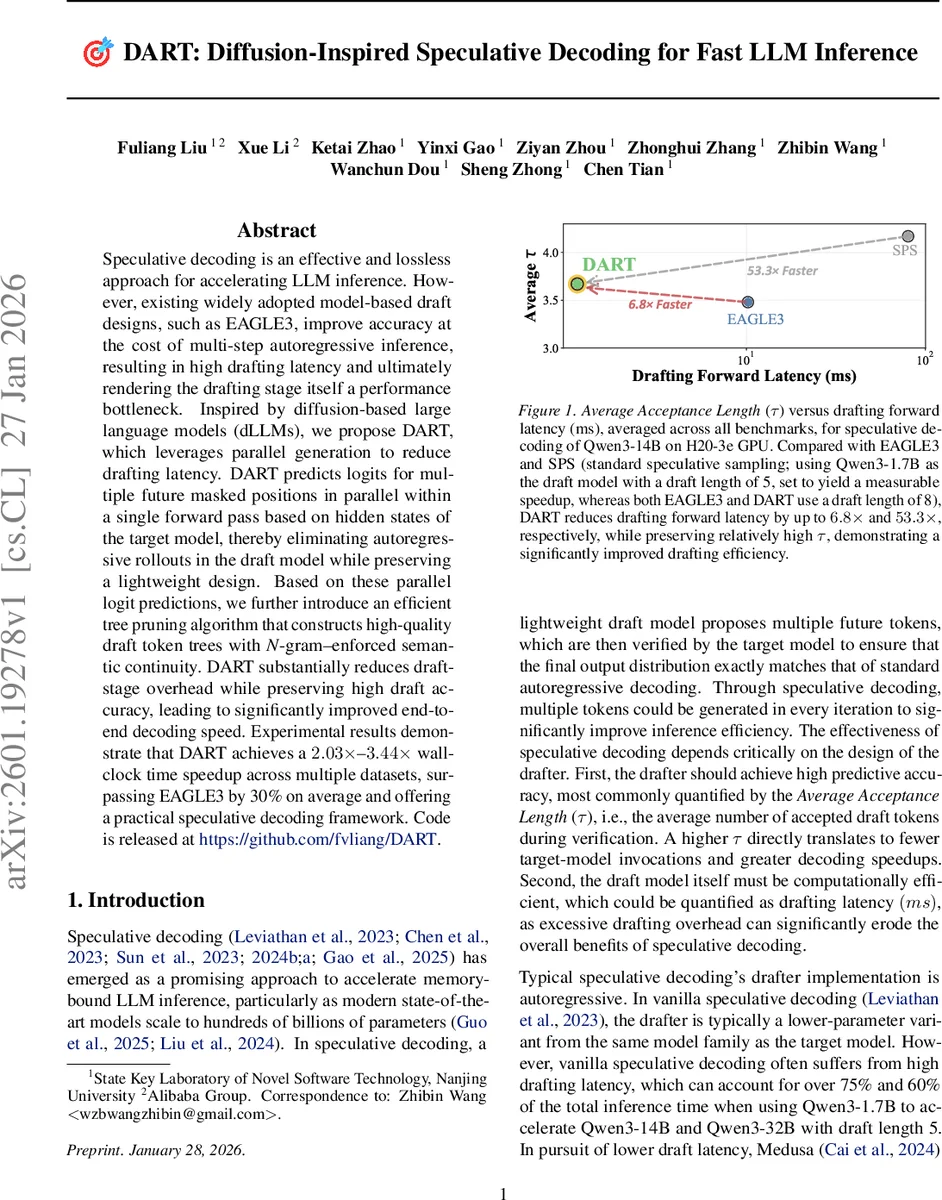
Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x–3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.
💡 Research Summary
The paper introduces DART, a novel speculative decoding framework that dramatically reduces the drafting latency that has become the primary bottleneck in existing speculative decoding methods such as EAGLE3. Traditional speculative decoding works by first having a lightweight draft model generate a block of K future tokens autoregressively, then having the target model verify these tokens in parallel. While the verification step is fast, the draft model’s sequential generation consumes a substantial portion of total inference time (often 20‑40%).
DART draws inspiration from diffusion‑based large language models (dLLMs), which predict multiple masked positions in parallel, but adapts this idea to the strictly causal setting required for speculative decoding. The key technical insight is to reuse the hidden states of the target model (extracted from several intermediate layers) as the input to a single customized Transformer decoder layer that serves as the draft model. After concatenating these hidden representations and a shifted token embedding, DART appends a fixed‑length sequence of
A “shifted logits prediction” scheme is employed: the logit at each masked position predicts the next token rather than the token at the same position. This shift improves the accuracy of the first drafted token and allows supervision signals at every position during training. Because parallel logits generate an exponentially large combinatorial space of possible token continuations, DART introduces an efficient tree‑pruning algorithm that leverages an N‑gram continuity model. For each position, top‑k candidate tokens are selected, and the N‑gram model filters out sequences that would break local continuity, dramatically reducing the search space while preserving high‑quality drafts. The resulting draft token tree is then verified by the target model using a “Tree Attention” mechanism that checks all candidates in a single pass, preserving the exact rejection‑based acceptance guarantees of speculative decoding.
Experimental evaluation spans Qwen3 and LLaMA2 families (1.7B to 32B parameters) across diverse benchmarks, including code generation, general text, and dialogue. DART achieves a 2.03×‑3.44× speedup over standard autoregressive decoding and outperforms EAGLE3 by an average of 30%. Drafting forward latency is reduced by up to 6.8×, while the average acceptance length τ remains comparable or slightly higher than prior methods. Notably, on code‑centric workloads DART delivers up to a 65% additional acceleration under the same target model settings.
The contributions are threefold: (1) a lightweight diffusion‑style drafting component that eliminates autoregressive rollouts by predicting multiple future logits in parallel using only a single added layer; (2) a continuity‑aware N‑gram tree‑pruning strategy that efficiently navigates the exponential candidate space without sacrificing draft quality; (3) a comprehensive empirical demonstration that the reduced drafting overhead translates into substantial end‑to‑end inference speedups across multiple model scales and tasks.
Limitations include the dependence on the chosen draft length d (larger d increases pruning cost), reliance on the quality of the N‑gram model, and the tight coupling with the target model’s hidden states, which may hinder use cases where a fully independent draft model is desired. Future work is suggested on dynamic draft length adaptation, more expressive continuity models (e.g., Transformer‑based N‑gram), multi‑GPU scaling, and further pipeline optimizations.
In summary, DART successfully adapts the parallel generation paradigm of diffusion models to the causal constraints of speculative decoding, delivering a practical, high‑performance solution that overcomes the drafting latency bottleneck while maintaining exact output fidelity.
Comments & Academic Discussion
Loading comments...
Leave a Comment