Length-Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction
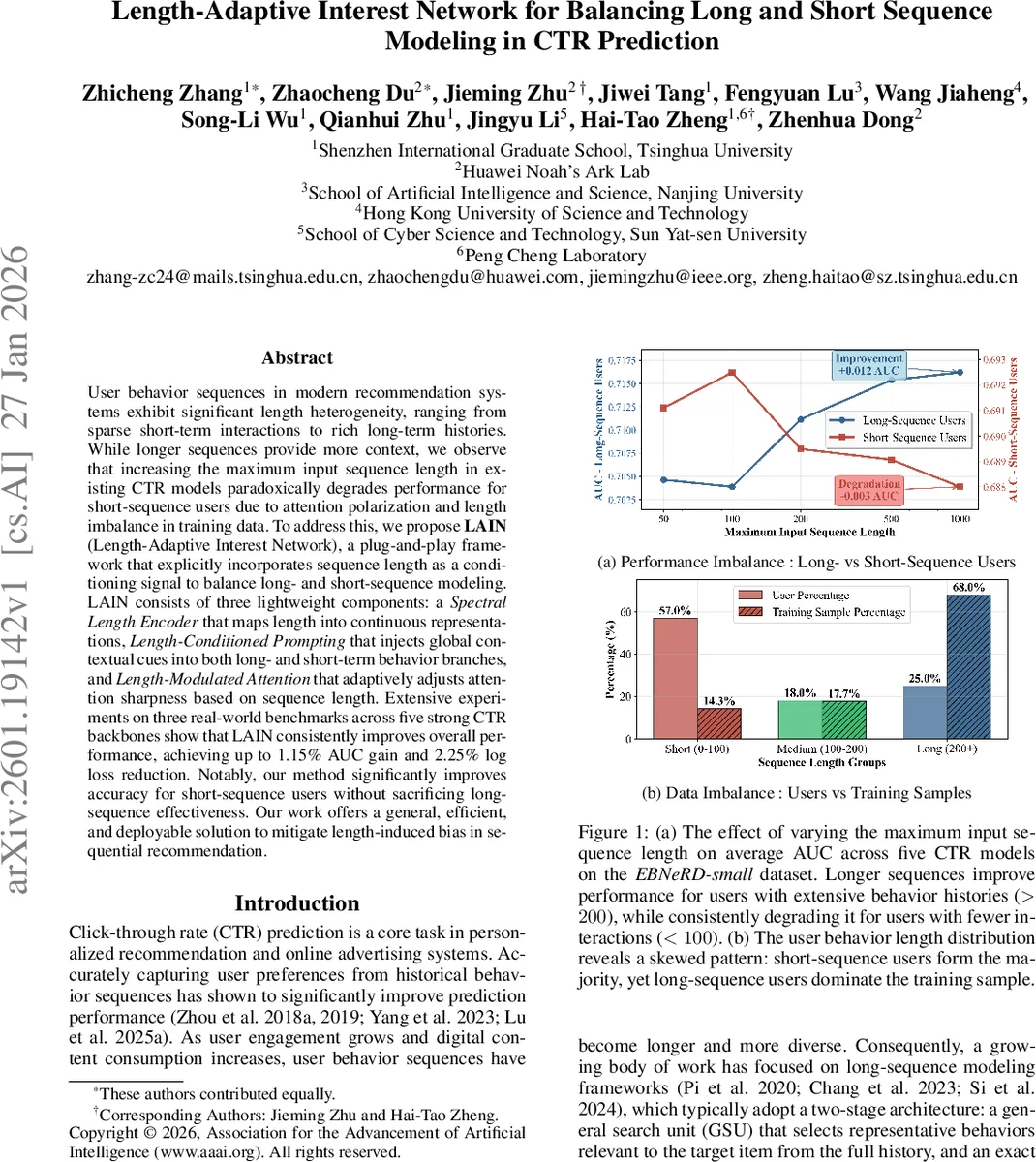
User behavior sequences in modern recommendation systems exhibit significant length heterogeneity, ranging from sparse short-term interactions to rich long-term histories. While longer sequences provide more context, we observe that increasing the maximum input sequence length in existing CTR models paradoxically degrades performance for short-sequence users due to attention polarization and length imbalance in training data. To address this, we propose LAIN(Length-Adaptive Interest Network), a plug-and-play framework that explicitly incorporates sequence length as a conditioning signal to balance long- and short-sequence modeling. LAIN consists of three lightweight components: a Spectral Length Encoder that maps length into continuous representations, Length-Conditioned Prompting that injects global contextual cues into both long- and short-term behavior branches, and Length-Modulated Attention that adaptively adjusts attention sharpness based on sequence length. Extensive experiments on three real-world benchmarks across five strong CTR backbones show that LAIN consistently improves overall performance, achieving up to 1.15% AUC gain and 2.25% log loss reduction. Notably, our method significantly improves accuracy for short-sequence users without sacrificing longsequence effectiveness. Our work offers a general, efficient, and deployable solution to mitigate length-induced bias in sequential recommendation.
💡 Research Summary
Click‑through‑rate (CTR) prediction is a cornerstone of modern recommendation and advertising systems, where user behavior sequences are leveraged to infer preferences. Existing state‑of‑the‑art CTR models typically adopt a two‑stage architecture (General Search Unit + Exact Search Unit) that can ingest very long histories. While extending the maximum input length benefits users with rich histories, the authors empirically discover a paradox: performance for short‑sequence users (who constitute the majority) consistently degrades as the maximum length grows. This “length imbalance” stems from two intertwined phenomena. First, attention polarization: softmax‑based attention becomes increasingly peaked with longer inputs, concentrating weight on a few salient items. In short sequences the limited number of tokens forces the model to over‑focus on one or two items, effectively discarding useful signals. Second, length signal deficiency: current models treat the behavior sequence as a homogeneous set and never expose the raw length to the network, despite length being a strong proxy for user activity level, interest diversity, and behavioral stability. Consequently, gradient signals from long‑history users (who dominate the training sample) conflict with those from short‑history users, leading to sub‑optimal generalization.
To remedy this, the paper proposes Length‑Adaptive Interest Network (LAIN), a lightweight plug‑and‑play framework that injects explicit length awareness into any CTR backbone. LAIN comprises three modules:
-
Spectral Length Encoder (SLE) maps the raw integer length L into a dense embedding h_len using trainable Fourier bases (sin / cos functions with learnable coefficients). This yields a smooth, periodic representation that can be differentiated and easily combined with other embeddings.
-
Length‑Conditioned Prompting (LCP) generates a set of soft prompt tokens P(L) conditioned on h_len. These tokens are prepended to the behavior sequence, providing a global, length‑specific context. For short sequences the prompt supplies additional signal; for long sequences it acts as a complementary global cue.
-
Length‑Modulated Attention (LMA) adjusts the sharpness of the attention distribution by scaling the softmax temperature τ(L) = τ₀ / (1 + α·L). Thus, short sequences receive a higher temperature (smoother attention), while long sequences receive a lower temperature (sharper focus). Moreover, the key and query vectors are augmented with h_len, directly injecting length information into the similarity computation.
The overall parameter set is split into shared weights θ_shared and length‑specific prompt weights θ_prompt(L), enabling the loss to back‑propagate distinct gradients for different length groups and thereby reducing gradient interference.
Experimental validation spans three public benchmarks (EBNeRD‑small, Amazon‑Books, Taobao‑Ads) and five strong CTR backbones (DIN, DIEN, SIM, ET‑A, TWIN). LAIN is added as a module without altering the backbone architecture, incurring < 2 % extra parameters and < 1 ms inference overhead. Results show consistent gains: overall AUC improves by up to 1.15 % points, log‑loss drops by up to 2.25 % points, and the most pronounced improvements appear for short‑sequence users (≤ 100 interactions), where AUC lifts by ~2 % points. Ablation studies confirm that each component contributes positively, with SLE alone yielding ~0.3 % AUC gain, and the combination of LCP and LMA delivering the bulk of the improvement.
The paper concludes that explicitly conditioning on sequence length introduces a new inductive bias that mitigates data‑imbalance‑induced bias, enhances cold‑start performance for new or low‑activity users, and can be deployed in production with negligible cost. Limitations include the focus solely on length (other user‑state signals remain unexplored) and the need for specialized handling of ultra‑short sequences (≤ 5 interactions). Future work may explore multi‑modal length‑aware modeling and dynamic adaptation of the temperature scaling parameter α.
Comments & Academic Discussion
Loading comments...
Leave a Comment