Parallel Spawning Strategies for Dynamic-Aware MPI Applications
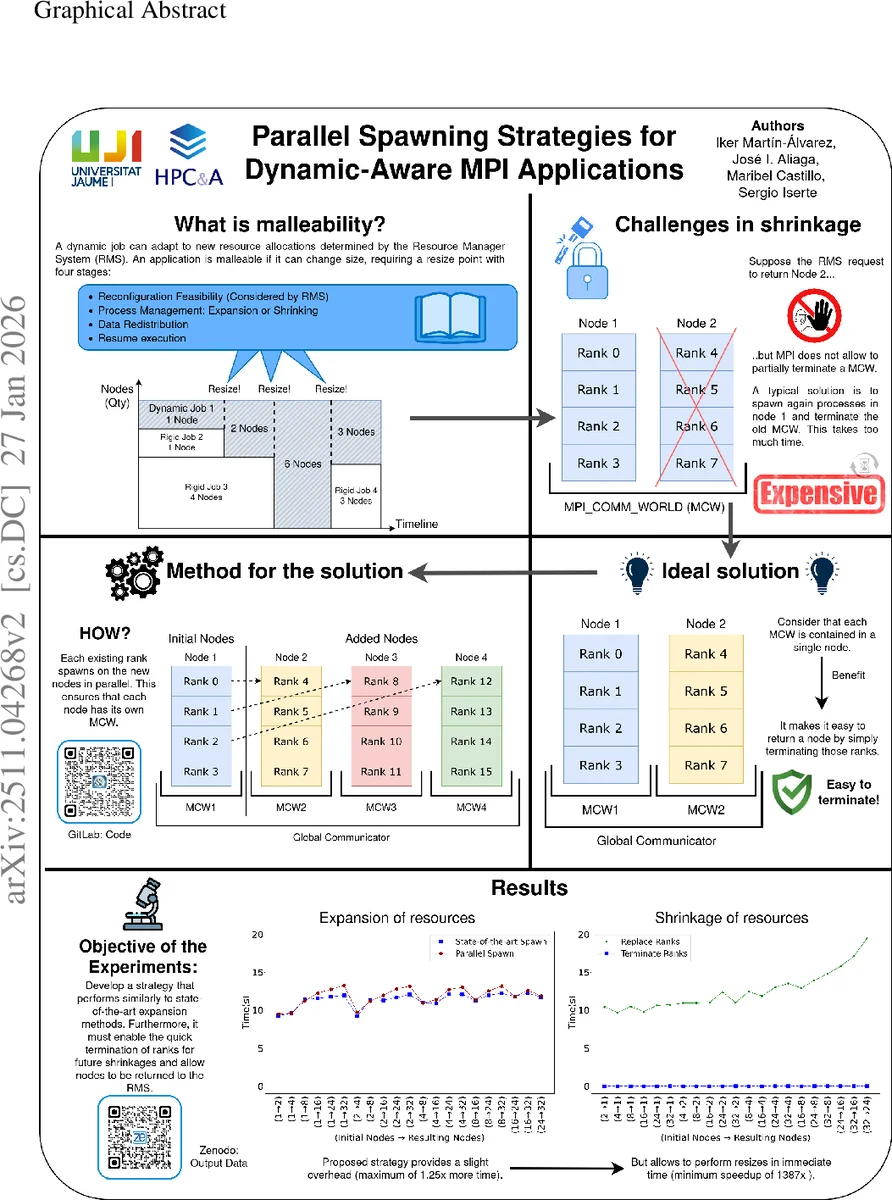
Dynamic resource management is an increasingly important capability of High Performance Computing systems, as it enables jobs to adjust their resource allocation at runtime. This capability can reduce workload makespan, substantially decreasing job waiting times and optimizing resource allocation. In this context, malleability refers to the ability of applications to adapt to new resource allocations during execution. Although beneficial, malleability incurs significant reconfiguration costs, making the reduction of these costs an important research topic. Some existing solutions for MPI applications respawn the entire application, which is an expensive solution that avoids the reuse of original processes. Other MPI solutions reuse them, but fail to fully release unneeded processes when shrinking, since some ranks within the same communicator remain active across nodes, preventing the application from returning those nodes to the system. This work overcomes both limitations by proposing a novel parallel spawning strategy, in which all processes cooperate in the spawning. This allows expansions to reuse processes while also terminating unneeded ones. This strategy has been validated on two systems with either machines with equal or different numbers of cores. Experiments show that this strategy preserves competitive expansion times with at most a $1.13\times$ and $1.25\times$ overhead for equal and different number of cores per node, respectively. More importantly, it enables fast shrink operations that reduce their cost by at least $1387\times$ and $20\times$ in the same scenarios.
💡 Research Summary
The paper addresses the growing need for dynamic resource management (DRM) in high‑performance computing (HPC) systems, focusing on MPI applications that must be malleable—that is, capable of changing their number of processes at runtime. Existing approaches suffer from two major drawbacks. The first class respawns the entire application, discarding all existing processes and incurring a large overhead. The second class reuses processes but cannot fully release processes during a shrink operation because the global communicator MPI_COMM_WORLD does not allow a subset of ranks to terminate; “zombie” ranks remain alive, preventing the underlying nodes from being returned to the resource manager.
To overcome these limitations, the authors propose a novel parallel spawning strategy in which every active process participates in spawning new processes and, when shrinking, terminates unneeded ranks outright. Two concrete algorithms are described. The “Hypercube” strategy targets homogeneous node allocations (all nodes have the same core count). It repeatedly invokes MPI_Comm_spawn on each node using MPI_COMM_SELF and an MPI_Info object that pins the new group to a specific node. Each spawning step involves all currently alive processes, causing the number of spawning agents to grow geometrically. The growth factor per step is C + 1, where C is the number of cores per node, and the total number of nodes after s steps follows Ts = (C + 1)^s·I − I, with I being the initial node count derived from the source process count NS (I = NS / C). The “Iterative Diffusive” strategy extends this idea to heterogeneous allocations, where nodes have different core counts; it adapts the spawning workload at each step to respect the varying capacities while preserving the same four‑phase pipeline: (1) open communication ports, (2) synchronize all groups, (3) merge the newly spawned groups into a single communicator, and (4) globally reorder ranks to maintain a logical ordering across nodes.
Process‑management is built on the two classic methods used in the MaM library: Baseline (always create a fresh group of processes) and Merge (reuse existing processes and only spawn/terminate the difference). The authors combine these with “Termination Shrinkage” (TS), a technique that fully terminates processes during a shrink, as opposed to “Zombie Shrinkage” (ZS) which leaves terminated ranks in a sleeping state. By isolating each MPI_COMM_WORLD on a separate node and performing spawning in parallel, TS can be applied without the scalability bottlenecks of earlier node‑specific sequential spawning.
The implementation was integrated into the MaM malleability module, which already provides a flexible interface for adding dynamic behavior to MPI codes. Experiments were conducted on two clusters: one with homogeneous nodes (identical core counts) and another with heterogeneous nodes (different core counts per node). Results show that expansion overhead remains modest—at most 1.13× for homogeneous and 1.25× for heterogeneous configurations—demonstrating that parallel spawning scales well. More strikingly, shrink operations are dramatically faster: the proposed TS‑based parallel approach reduces shrink time by at least 1,387× compared with traditional Spawn Shrinkage (SS) and by at least 20× compared with Zombie Shrinkage (ZS). These gains stem from the ability to immediately release nodes back to the resource manager, eliminating the “zombie” barrier.
The paper concludes that parallel spawning provides a scalable, low‑overhead path to true MPI malleability, enabling both efficient expansion and rapid, clean shrinkage. The authors note that load‑balancing across heterogeneous hardware and extending the technique to accelerator resources (e.g., GPUs) remain open research directions. Overall, the work makes a significant contribution to dynamic job resizing in exascale‑era HPC systems, offering a practical solution that can be adopted in existing MPI applications with minimal code changes.
Comments & Academic Discussion
Loading comments...
Leave a Comment