Is On-Policy Data always the Best Choice for Direct Preference Optimization-based LM Alignment?
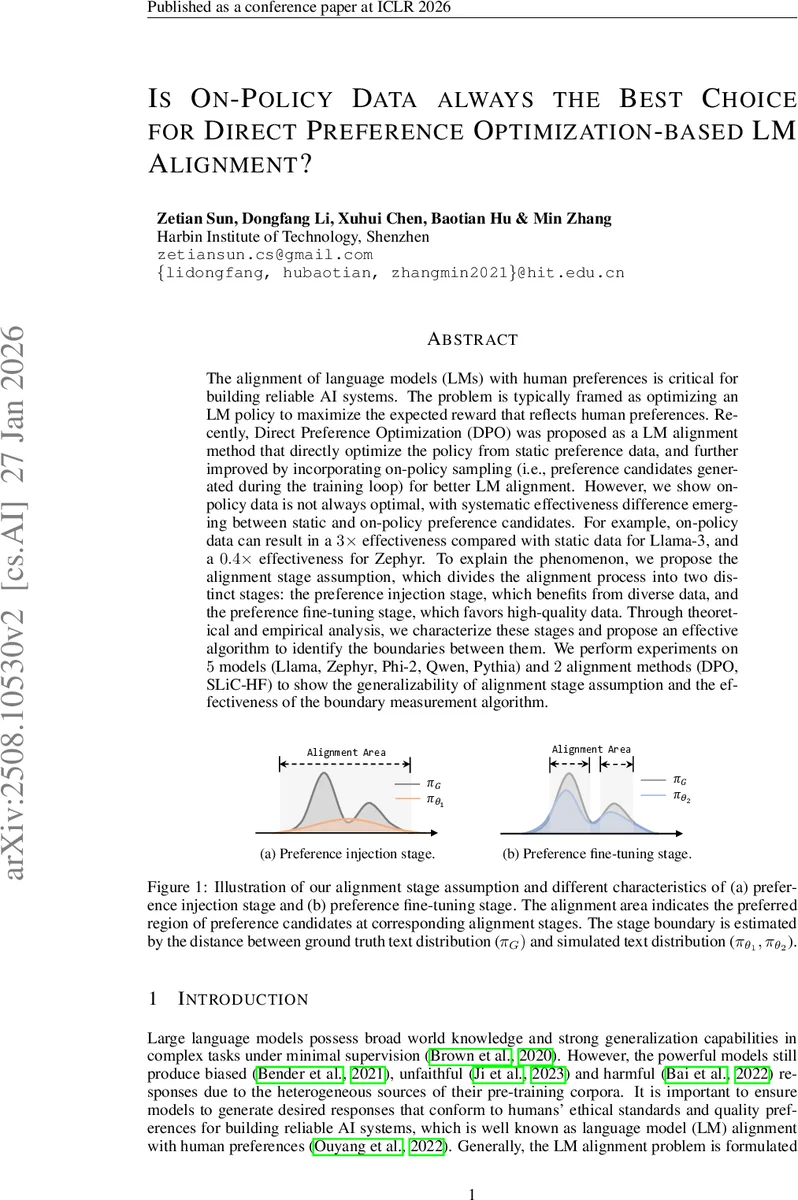
The alignment of language models~(LMs) with human preferences is critical for building reliable AI systems. The problem is typically framed as optimizing an LM policy to maximize the expected reward that reflects human preferences. Recently, Direct Preference Optimization~(DPO) was proposed as a LM alignment method that directly optimize the policy from static preference data, and further improved by incorporating on-policy sampling~(i.e., preference candidates generated during the training loop) for better LM alignment. However, we show on-policy data is not always optimal, with systematic effectiveness difference emerging between static and on-policy preference candidates. For example, on-policy data can result in a $3\times$ effectiveness compared with static data for Llama-3, and a $0.4\times$ effectiveness for Zephyr. To explain the phenomenon, we propose the alignment stage assumption, which divides the alignment process into two distinct stages: the preference injection stage, which benefits from diverse data, and the preference fine-tuning stage, which favors high-quality data. Through theoretical and empirical analysis, we characterize these stages and propose an effective algorithm to identify the boundaries between them. We perform experiments on $5$ models~(Llama, Zephyr, Phi-2, Qwen, Pythia) and $2$ alignment methods~(DPO, SLiC-HF) to show the generalizability of alignment stage assumption and the effectiveness of the boundary measurement algorithm.
💡 Research Summary
The paper investigates the role of on‑policy data in Direct Preference Optimization (DPO)‑based language model (LM) alignment and finds that on‑policy data is not universally beneficial. Empirical results across five models (Llama‑3, Zephyr, Phi‑2, Qwen, Pythia) and two alignment methods (DPO, SLiC‑HF) reveal a systematic discrepancy: for Llama‑3, on‑policy preference candidates improve performance up to threefold, whereas for Zephyr the same data can reduce effectiveness to 0.4×, and Phi‑2 shows the opposite trend. To explain these observations, the authors propose the “alignment stage assumption,” which divides the alignment process into two distinct phases.
-
Preference Injection Stage – Early in training the policy has not yet captured the human‑derived reward distribution. In this phase, diversity of preference candidates (both in the underlying text space and in the preference labels) is crucial. On‑policy sampling introduces novel text patterns, expanding coverage of the latent reward distribution and enabling a more accurate approximation of the ground‑truth text distribution π_G.
-
Preference Fine‑Tuning Stage – After the policy has learned a coarse approximation of the reward, further improvements depend on high‑quality (high‑win‑rate) candidates. Here, the emphasis shifts from diversity to fidelity; low‑quality on‑policy samples can degrade performance, making static off‑policy data preferable.
The paper introduces a boundary measurement algorithm that automatically determines which stage a policy currently occupies. The algorithm computes divergence metrics (KL, JS, or Bradley‑Terry consistency scores) between the current policy distribution π_θ and two reference distributions: π_off (derived from the static off‑policy dataset) and π_on (derived from the policy’s own on‑policy generations). By comparing distances to the ground‑truth distribution π_G (approximated by a strong reward model, PairRM), the algorithm selects the reference that better matches π_G, thereby signalling whether the model is still in the injection phase or has entered fine‑tuning.
Theoretical analysis under the Bradley‑Terry model shows that candidate diversity directly reduces the bias in estimating π_G, while candidate quality minimizes the KL regularization term, confirming the empirical stage characteristics.
Experimental methodology: a two‑iteration training loop is used for each model. Four data‑mixing configurations are evaluated: (i) off→off, (ii) off→on, (iii) on→off, and (iv) on→on. Performance is measured with AlpacaEval 2.0 win‑rate against reference responses. Results demonstrate that Llama‑3 consistently benefits from on‑policy data in both iterations, Zephyr benefits from on‑policy data only after an initial off‑policy warm‑up, and Phi‑2 prefers off‑policy data throughout. The boundary measurement algorithm successfully identifies the transition point, and dynamically switching data sources based on its signal yields a 5–7 % average gain over static schedules. The same patterns hold for SLiC‑HF, indicating that the stage assumption generalizes beyond DPO.
In summary, the paper contributes: (1) a systematic characterization of when on‑policy versus off‑policy preference data is advantageous, (2) a principled two‑stage model of LM alignment (injection vs. fine‑tuning), (3) a practical algorithm for detecting the stage boundary, and (4) extensive empirical validation across models and methods. The work suggests future directions such as refining the boundary metric with human feedback, extending the framework to domain‑specific alignment tasks, and improving on‑policy sample quality via meta‑learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment