R3G: A Reasoning--Retrieval--Reranking Framework for Vision-Centric Answer Generation
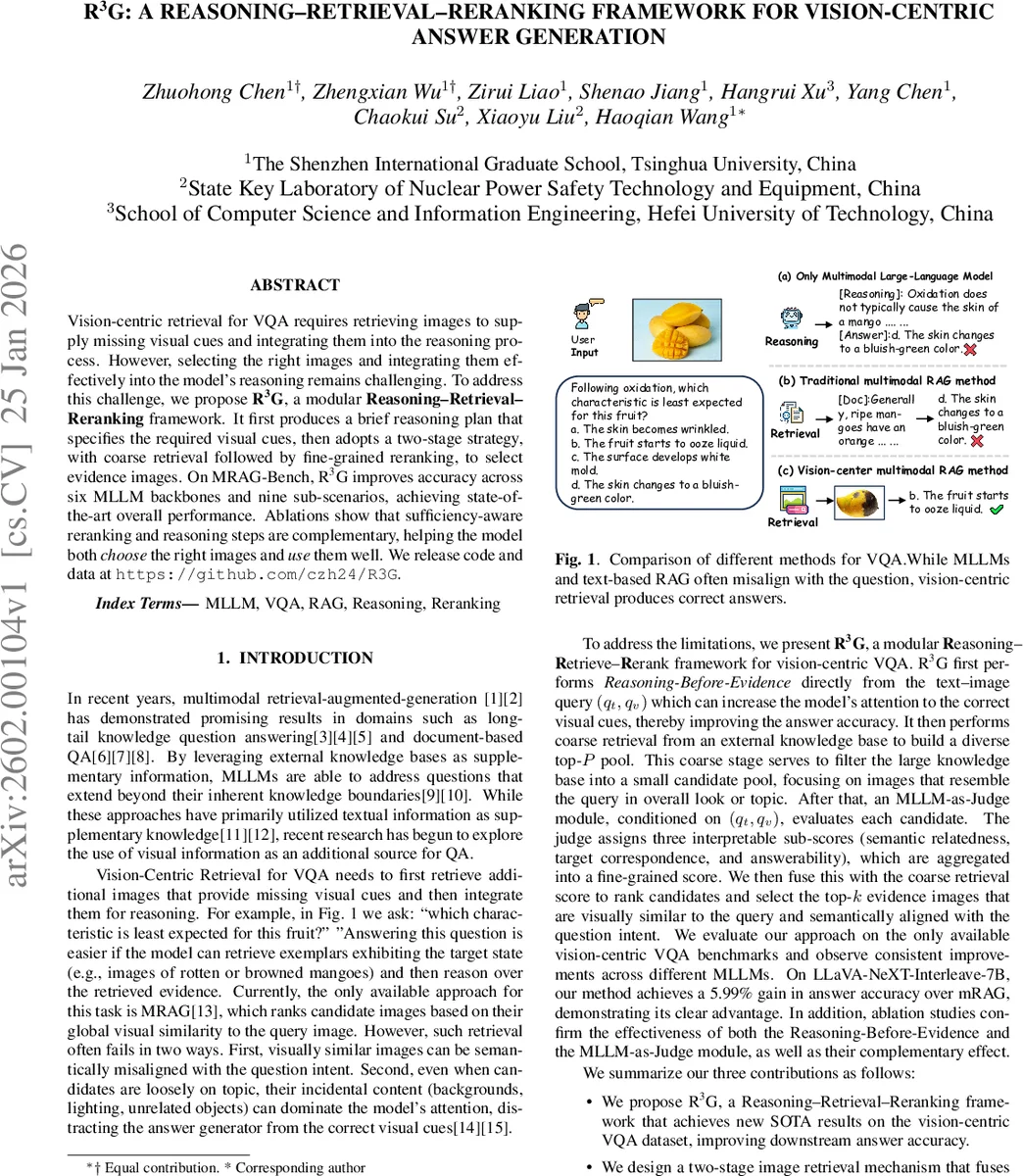
Vision-centric retrieval for VQA requires retrieving images to supply missing visual cues and integrating them into the reasoning process. However, selecting the right images and integrating them effectively into the model’s reasoning remains challenging.To address this challenge, we propose R3G, a modular Reasoning-Retrieval-Reranking framework.It first produces a brief reasoning plan that specifies the required visual cues, then adopts a two-stage strategy, with coarse retrieval followed by fine-grained reranking, to select evidence images.On MRAG-Bench, R3G improves accuracy across six MLLM backbones and nine sub-scenarios, achieving state-of-the-art overall performance. Ablations show that sufficiency-aware reranking and reasoning steps are complementary, helping the model both choose the right images and use them well. We release code and data at https://github.com/czh24/R3G.
💡 Research Summary
The paper introduces R3G, a modular Reasoning‑Retrieval‑Reranking framework designed to improve vision‑centric visual question answering (VQA) where the query image lacks crucial visual cues. Existing methods such as MRAG retrieve images based solely on global visual similarity, which often selects visually similar but semantically irrelevant images, leading to noisy evidence that misguides the language model. R3G tackles this by first generating a concise reasoning plan that explicitly lists the missing visual cues, then performing a two‑stage retrieval process, and finally reranking candidates with a large‑language‑model‑as‑judge that evaluates three interpretable criteria: semantic relevance, target correspondence, and answerability.
Reasoning‑Before‑Evidence: Given the textual query (q_t) and the query image (q_v), a frozen multimodal LLM produces a list of single‑sentence steps (R^\star) describing which visual aspects need to be inspected (e.g., “check for browning on the fruit skin”). This plan is kept separate from any retrieved images, preventing noisy evidence from contaminating the reasoning flow.
Coarse Retrieval: Using a CLIP‑style visual encoder (f_v), the system embeds the query image and all images in an external knowledge base. Cosine similarity (s_{\text{img}}(q_v, I)) ranks the database, and the top‑(P) candidates form the coarse pool (\mathcal{C}_P). A temperature‑scaled softmax converts these similarities into normalized scores (s_1(i)). This stage quickly filters out globally unrelated images while preserving computational efficiency.
MLLM‑as‑Judge Reranking: For each candidate (I^{(i)}) in (\mathcal{C}_P), a frozen multimodal LLM (the “judge”) receives ((q_t, q_v, I^{(i)})) and outputs a natural‑language rationale plus three sub‑scores in (
Comments & Academic Discussion
Loading comments...
Leave a Comment