CARE-RFT: Confidence-Anchored Reinforcement Finetuning for Reliable Reasoning in Large Language Models
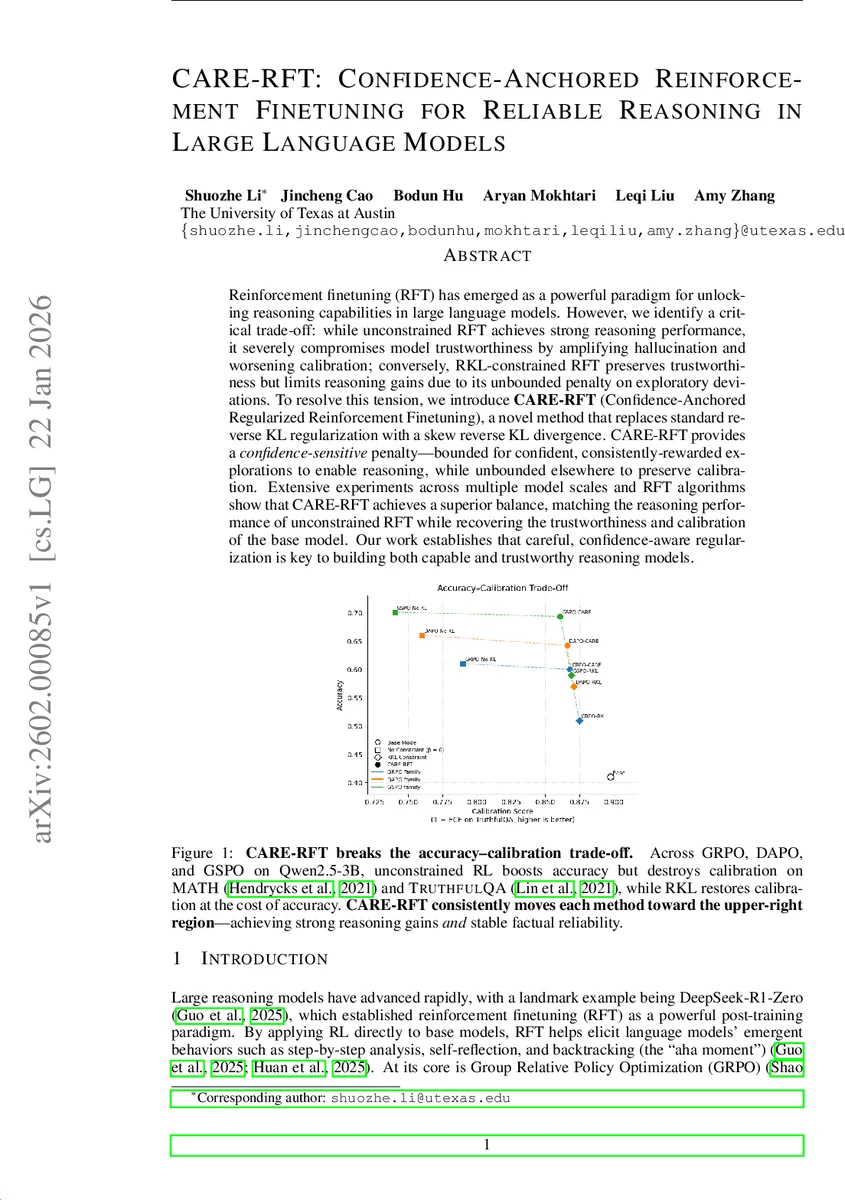
Reinforcement finetuning (RFT) has emerged as a powerful paradigm for unlocking reasoning capabilities in large language models. However, we identify a critical trade-off: while unconstrained RFT achieves strong reasoning performance, it severely compromises model trustworthiness by amplifying hallucination and worsening calibration; conversely, RKL-constrained RFT preserves trustworthiness but limits reasoning gains due to its unbounded penalty on exploratory deviations. To resolve this tension, we introduce CARE-RFT (Confidence-Anchored Regularized Reinforcement Finetuning), a novel method that replaces standard reverse KL regularization with a skew reverse KL divergence. CARE-RFT provides a confidence-sensitive penalty: it is bounded for confident, consistently rewarded explorations to enable reasoning, while unbounded elsewhere to preserve calibration. Extensive experiments across multiple model scales and RFT algorithms show that CARE-RFT achieves a superior balance, matching the reasoning performance of unconstrained RFT while recovering the trustworthiness and calibration of the base model. Our work establishes that careful, confidence-aware regularization is key to building both capable and trustworthy reasoning models.
💡 Research Summary
This paper investigates a fundamental tension in reinforcement finetuning (RFT) of large language models (LLMs): unconstrained RFT dramatically improves reasoning performance but simultaneously degrades trustworthiness, manifesting as higher hallucination rates and larger Expected Calibration Error (ECE). Conversely, applying a reverse‑KL (RKL) regularizer preserves the base model’s calibration and factuality but imposes an unbounded penalty in low‑probability regions, which suppresses the exploration needed for novel reasoning strategies and thus limits reasoning gains.
Through a series of controlled experiments with the GRPO algorithm, the authors dissect two failure modes of unconstrained RFT. Positive‑only updates (+Reward) reinforce entire generations when a high outcome reward is received, causing the model to become over‑confident in spurious reasoning chains. Negative‑only updates (‑Reward) uniformly penalize all tokens in incorrect generations, leading to “forgetting” of desirable base‑model behaviors such as grammaticality and factual grounding, which in turn harms calibration. Adding an RKL constraint mitigates these issues by providing token‑level guidance, but its infinite penalty when the reference policy assigns near‑zero probability prevents the model from moving into promising low‑probability reasoning paths.
To reconcile these opposing forces, the authors propose CARE‑RFT (Confidence‑Anchored Regularized Reinforcement Finetuning). CARE‑RFT replaces the standard RKL term with a skew‑reverse KL (SRKL) divergence, originally introduced by Lee (2001). SRKL computes the KL between the current policy πθ and a mixture distribution α·πθ + (1‑α)·πref, where α∈(0,1) controls the strength of the anchor. When α→0, SRKL collapses to ordinary RKL; when α→1, the regularizer vanishes, allowing free exploration. CARE‑RFT dynamically adjusts α on a per‑token basis according to the model’s own confidence and the consistency of the reward signal: tokens that are generated with high confidence and repeatedly receive positive reward are assigned a larger α, thereby relaxing the regularization and permitting probability mass to shift toward these promising trajectories. Conversely, tokens in uncertain or negatively‑rewarded contexts receive a small α, preserving a strong RKL‑like pull toward the well‑calibrated reference model.
The paper evaluates CARE‑RFT across multiple model sizes (including Qwen2.5‑3B), several RFT variants (GRPO, DAPO, GSPO), and a suite of benchmarks covering reasoning (MATH, GSM‑8K), factual retrieval (TruthfulQA), and calibration (ECE). Results consistently show that CARE‑RFT matches or slightly exceeds the reasoning accuracy of unconstrained RFT while restoring ECE to the level of the base model and achieving factuality comparable to RKL‑constrained training. Visualizations (e.g., Figure 1) illustrate that CARE‑RFT moves methods toward the upper‑right quadrant of the accuracy‑calibration trade‑off space, indicating strong reasoning gains without sacrificing trustworthiness.
Key technical contributions include: (1) a rigorous analysis of why both unconstrained RFT and standard RKL regularization are insufficient for trustworthy reasoning; (2) the formulation of a confidence‑aware SRKL penalty that is bounded for confident, consistently rewarded tokens yet unbounded elsewhere, thereby preserving calibration; (3) an algorithmic scheme for dynamically setting α based on token‑level confidence and reward signals; and (4) extensive empirical validation demonstrating that this approach yields a superior balance of accuracy, factuality, and calibration across diverse settings.
In summary, CARE‑RFT demonstrates that trust‑aware regularization—anchoring the policy to the base model in uncertain regions while allowing flexible growth in confident, rewarding regions—can resolve the long‑standing accuracy‑calibration trade‑off in reinforcement finetuning. This confidence‑anchored regularization paradigm offers a promising direction for building LLMs that are both highly capable in reasoning and reliably trustworthy, a prerequisite for high‑stakes applications such as healthcare, law, and finance. Future work may explore more sophisticated confidence estimation mechanisms, alternative skewed divergences, or integration with other safety‑oriented training techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment