Mirai: Autoregressive Visual Generation Needs Foresight
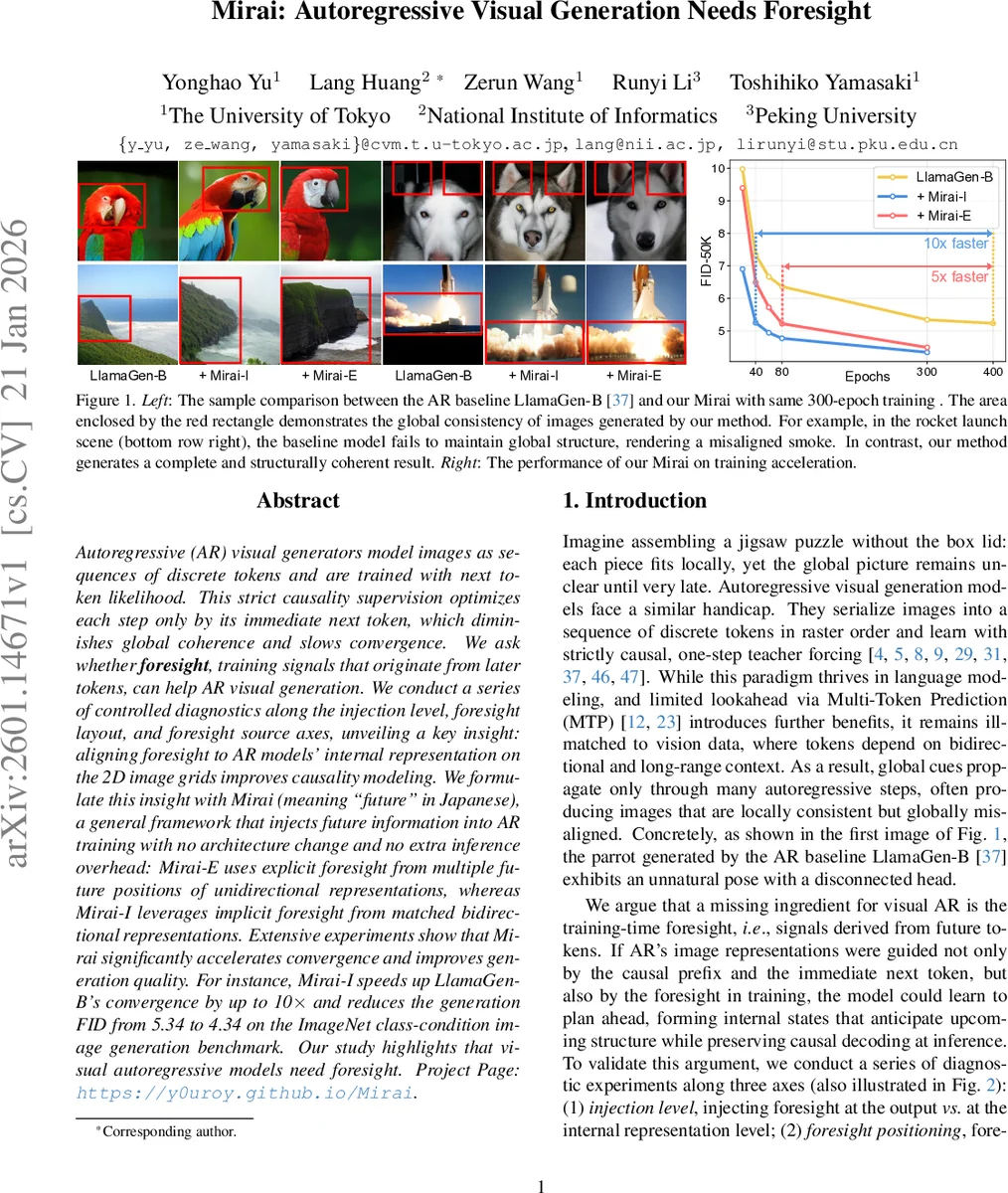
Autoregressive (AR) visual generators model images as sequences of discrete tokens and are trained with next token likelihood. This strict causality supervision optimizes each step only by its immediate next token, which diminishes global coherence and slows convergence. We ask whether foresight, training signals that originate from later tokens, can help AR visual generation. We conduct a series of controlled diagnostics along the injection level, foresight layout, and foresight source axes, unveiling a key insight: aligning foresight to AR models’ internal representation on the 2D image grids improves causality modeling. We formulate this insight with Mirai (meaning “future” in Japanese), a general framework that injects future information into AR training with no architecture change and no extra inference overhead: Mirai-E uses explicit foresight from multiple future positions of unidirectional representations, whereas Mirai-I leverages implicit foresight from matched bidirectional representations. Extensive experiments show that Mirai significantly accelerates convergence and improves generation quality. For instance, Mirai can speed up LlamaGen-B’s convergence by up to 10$\times$ and reduce the generation FID from 5.34 to 4.34 on the ImageNet class-condition image generation benchmark. Our study highlights that visual autoregressive models need foresight.
💡 Research Summary
The paper addresses a fundamental limitation of autoregressive (AR) visual generation models, which treat image synthesis as a sequential prediction of discrete tokens in raster order and are trained solely with next‑token likelihood (NTP loss). This strict causal supervision provides each step with only local feedback from the immediate next token, leading to slow convergence and, more critically, a lack of global coherence: generated images often contain locally plausible details but exhibit fragmented or misaligned structures at the whole‑image level.
To mitigate this, the authors introduce the concept of “foresight”: training‑time signals derived from future tokens that can be used to guide the model’s internal representations. Formally, for each position n, a set of foresight targets fₙₖ ( k = 1…K) is defined, each depending on tokens xₙ₊ₖ or on features extracted from a “foresight encoder”. A foresight loss L₍foresight₎ encourages the hidden state hₙ (at some intermediate layer) to align with these future‑derived targets via a cosine‑similarity objective. The total training objective becomes L₍Mirai₎ = L₍NTP₎ + λ L₍foresight₎.
The authors systematically explore three design axes: (1) Injection level – whether foresight is applied at the output layer (direct token prediction) or at an internal representation layer; (2) Layout – whether future tokens are selected along the 1‑D raster scan or based on 2‑D spatial proximity on the image grid; (3) Source – whether foresight is generated explicitly from the AR model itself (via an exponential moving average, EMA) or implicitly from a frozen bidirectional vision encoder (e.g., DINOv2).
Key findings from these diagnostics are:
- Internal‑layer injection outperforms output‑layer prediction. Directly predicting multiple future tokens (akin to Multi‑Token Prediction) harms optimization due to competing gradients, whereas aligning hidden states with future information regularizes the representation without forcing discrete token prediction.
- 2‑D spatial layout consistently beats 1‑D raster layout. Aligning to the K nearest spatial neighbors respects image geometry, leading to lower FID scores across all K values.
- Both explicit (EMA) and implicit (bidirectional encoder) foresight improve performance, with the latter providing the strongest global coherence because it encodes full‑image context.
Based on these insights, the paper proposes Mirai, a general training framework that injects foresight while keeping the model architecture and inference unchanged. Two concrete instantiations are introduced:
-
Mirai‑E (Explicit foresight). The foresight encoder is the EMA of the AR decoder’s intermediate layers. For each token n, K future positions are selected on the 2‑D grid; each position has its own lightweight projection head ρₖ that maps hₙ to the EMA representation of that future token. The loss aligns each ρₖ(hₙ) with the corresponding EMA target, providing explicit, position‑indexed look‑ahead.
-
Mirai‑I (Implicit foresight). A pretrained bidirectional encoder (e.g., DINOv2) processes the full image to produce a feature map fₙ. The AR hidden state hₙ is aligned to the co‑located bidirectional feature via a single projection head and cosine similarity. Because the encoder aggregates global context, each fₙ carries implicit information about distant structures, encouraging the AR model to form representations that anticipate the overall layout.
During inference, the projection heads and foresight encoders are discarded; decoding proceeds token‑by‑token exactly as in the baseline, incurring no extra computational cost.
Experimental validation is performed on ImageNet 256×256 using the LlamaGen‑B autoregressive decoder. Results include:
- Quality improvement: Mirai‑I reduces FID from 5.34 (baseline) to 4.34 after 80 epochs, with a corresponding increase in Inception Score.
- Training acceleration: When trained for 300 epochs, Mirai‑E and Mirai‑I together achieve the same FID that the baseline reaches after roughly 10× more epochs; convergence speedups of 5–10× are reported.
- Layer selection: Aligning foresight to intermediate layers 4–6 yields the best trade‑off between representation richness and gradient flow.
- Ablations on K and block size: Varying the number of foresight tokens (K = 3, 4, 9) confirms that 2‑D alignment consistently outperforms 1‑D. Blocking the bidirectional encoder’s attention demonstrates a monotonic relationship between the amount of future context available to the foresight encoder and final generation quality.
The paper’s contributions are threefold: (1) a thorough empirical study of foresight injection in visual AR models; (2) the Mirai framework, which introduces foresight without architectural changes or inference overhead; (3) demonstration that both explicit EMA‑based and implicit bidirectional‑encoder‑based foresight substantially speed up training and improve image fidelity.
In conclusion, the work reveals that visual autoregressive generators benefit from “looking ahead” during training: aligning future‑derived signals to internal 2‑D representations strengthens causal learning, enables the model to plan globally coherent structures, and dramatically accelerates convergence. This opens a new direction for improving AR‑based generative models across modalities, suggesting future extensions such as lightweight foresight encoders, integration with alternative tokenizers, or application to video and 3‑D generation tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment